
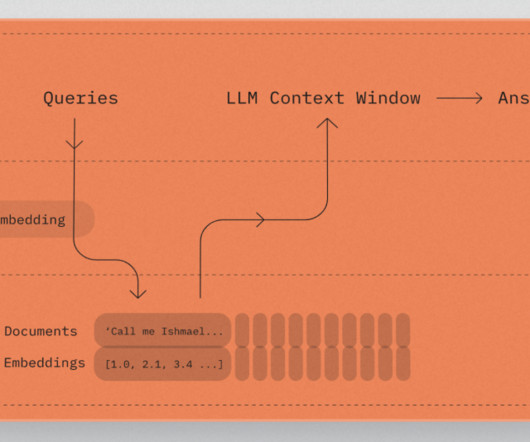
Meet Chroma: An AI-Native Open-Source Vector Database For LLMs: A Faster Way to Build Python or JavaScript LLM Apps with Memory
Marktechpost
AUGUST 19, 2023
It allows for very fast similarity search, essential for many AI uses such as recommendation systems, picture recognition, and NLP. Chroma can be used to create word embeddings using Python or JavaScript programming. Each referenced string can have extra metadata that describes the original document.






































Let's personalize your content