This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
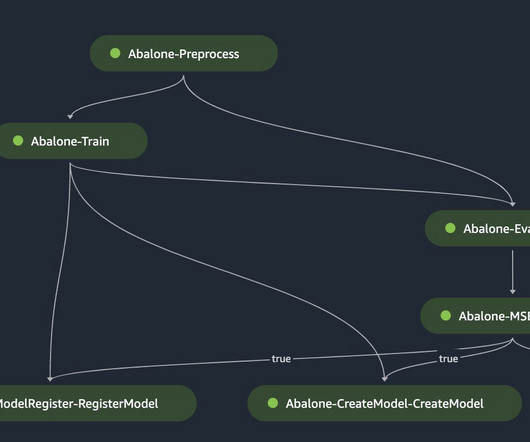
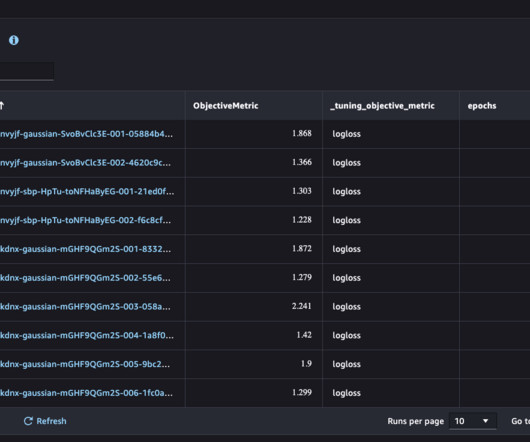
One of these strategies is using Amazon Simple Storage Service (Amazon S3) folder structures and Amazon Bedrock Knowledge Bases metadata filtering to enable efficient data segmentation within a single knowledge base. The S3 bucket, containing customer data and metadata, is configured as a knowledge base data source.
If you're looking to implement Automatic Speech Recognition (ASR) in Python, you may have noticed that there is a wide array of available options. Broadly, Python speech recognition and Speech-to-Text solutions can be categorized into two main types: open-source libraries and cloud-based services. What is Speech Recognition?
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services. However, some components may incur additional usage-based costs.
How to save a trained model in Python? Saving trained model with pickle The pickle module can be used to serialize and deserialize the Python objects. For saving the ML models used as a pickle file, you need to use the Pickle module that already comes with the default Python installation. Now let’s see how we can save our model.
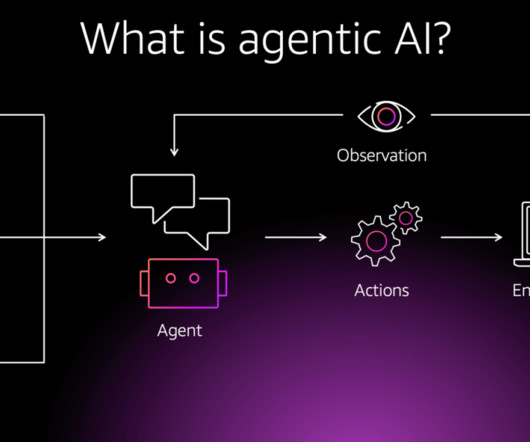
The following illustration describes the components of an agentic AI system: Overview of CrewAI CrewAI is an enterprise suite that includes a Python-based open source framework. In contrast, an agentic system can use real-time data (such as weather or geopolitical risks) to proactively reroute supply chains and reallocate resources.
This allows users to accomplish different NaturalLanguageProcessing (NLP) functional tasks and take advantage of IBM vetted pre-trained open-source foundation models. Encoder-decoder and decoder-only large language models are available in the Prompt Lab today. To bridge the tuning gap, watsonx.ai
Sonnet model for naturallanguageprocessing. For example, we export pre-chunked asset metadata from our asset library to Amazon S3, letting Amazon Bedrock handle embeddings, vector storage, and search. This could be, for example, Keep all your replies as short as possible or If I ask for code its always Python.
This setup uses the AWS SDK for Python (Boto3) to interact with AWS services. You then format these pairs as individual text files with corresponding metadata JSON files , upload them to an S3 bucket, and ingest them into your cache knowledge base.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. This generative AI task is called text-to-SQL, which generates SQL queries from naturallanguageprocessing (NLP) and converts text into semantically correct SQL. We use Anthropic Claude v2.1
It supports various programming languages and environments, including Python, Node.js, Ruby, Rust, and Go. Installation is straightforward, with commands such as ‘pip install sqlite-vec’ for Python and ‘npm install sqlite-vec’ for Node.js.
Introduction to LLMs in Python Difficulty Level: Intermediate This hands-on course teaches you to understand, build, and utilize Large Language Models (LLMs) for tasks like translation and question-answering. Students learn about key innovations, ethical challenges, and hands-on labs for generating text with Python.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., For example, if your team works on recommender systems or naturallanguageprocessing applications, you may want an MLOps tool that has built-in algorithms or templates for these use cases.
Overview of RAG RAG solutions are inspired by representation learning and semantic search ideas that have been gradually adopted in ranking problems (for example, recommendation and search) and naturallanguageprocessing (NLP) tasks since 2010. The search precision can also be improved with metadata filtering.
Addressing this challenge, researchers from Eindhoven University of Technology have introduced a novel method that leverages the power of pre-trained Transformer models, a proven success in various domains such as Computer Vision and NaturalLanguageProcessing.
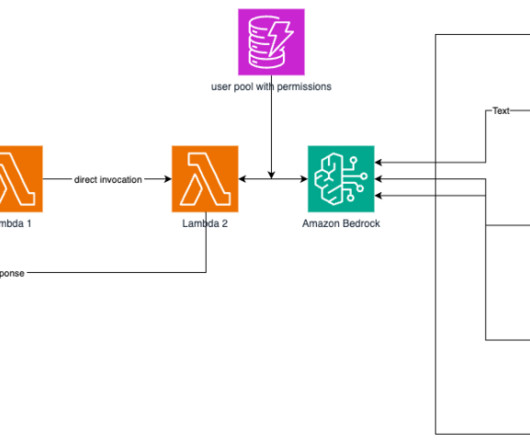
Solution overview To solve this problem, you can identify one or more unique metadata information that is associated with the documents being indexed and searched. In Amazon Kendra, you provide document metadata attributes using custom attributes. When the authentication is performed using Amazon Cognito, the “sessionState”.”sessionAttributes”.”idtokenjwt”
In this post, we illustrate how to handle OOC by utilizing the power of the IMDb dataset (the premier source of global entertainment metadata) and knowledge graphs. Creates a Lambda function to process and load movie metadata and embeddings to OpenSearch Service indexes ( **-ReadFromOpenSearchLambda-** ).
Langchain is a powerful tool for building applications that understand naturallanguage. Using advanced models, we can achieve sophisticated naturallanguageprocessing tasks such as text generation, question answering, and language translation, enabling the development of highly interactive and intelligent applications.
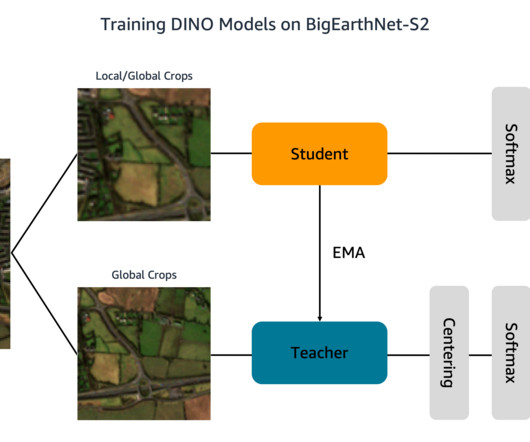
Additionally, each folder contains a JSON file with the image metadata. To perform statistical analyses of the data and load images during DINO training, we process the individual metadata files into a common geopandas Parquet file. We store the BigEarthNet-S2 images and metadata file in an S3 bucket. during training.
This could involve better preprocessing tools, semi-supervised learning techniques, and advances in naturallanguageprocessing. Data from social media, reviews, or any user generated contents can also contain toxic and biased contents, and you may need to filter them out using some pre-processing steps.
Prerequisite libraries: SageMaker Python SDK, Pinecone Client Solution Walkthrough Using SageMaker Studio notebook, we first need install prerequisite libraries: !pip Since we top_k = 1 , index.query returned the top result along side the metadata which reads Managed Spot Training can be used with all instances supported in Amazon.
Using machine learning (ML) and naturallanguageprocessing (NLP) to automate product description generation has the potential to save manual effort and transform the way ecommerce platforms operate. First, launch the notebook main.ipynb in SageMaker Studio by selecting the Image as Data Science and Kernel as Python 3.
Prerequisites To start experimenting with Selective Execution, we need to first set up the following components of your SageMaker environment: SageMaker Python SDK – Ensure that you have an updated SageMaker Python SDK installed in your Python environment. or higher: python3 -m pip install sagemaker>=2.162.0
This blog post was co-authored, and includes an introduction, by Zilong Bai, senior naturallanguageprocessing engineer at Patsnap. Install the required Python packages. The conversion process first converts the PyTorch-based model to the ONNX model and then converts the ONNX-based model to the TensorRT-based model.
Businesses can use LLMs to gain valuable insights, streamline processes, and deliver enhanced customer experiences. Although no advanced technical knowledge is required, familiarity with Python and AWS Cloud services will be beneficial if you want to explore our sample code on GitHub.
LangChain is a Python library designed to build applications with LLMs. Python 3.10 GPU Optimized image, Python 3 kernel, and ml.t3.medium To set up the development environment, you need to install the necessary Python libraries, as demonstrated in the following code. medium as the instance type.
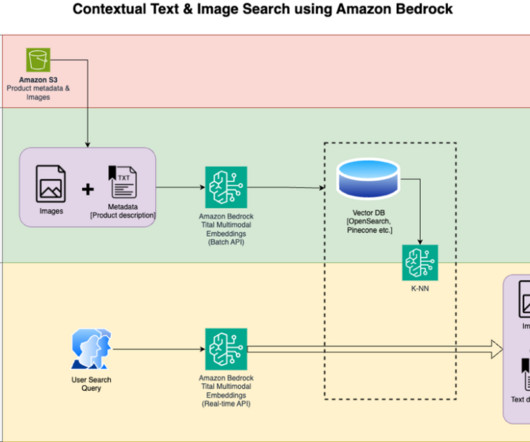
Run the solution Open the file titan_mm_embed_search_blog.ipynb and use the Data Science Python 3 kernel. Load the publicly available Amazon Berkeley Objects Dataset and metadata in a pandas data frame. The dataset is a collection of 147,702 product listings with multilingual metadata and 398,212 unique catalogue images.
Large language models (LLMs) have achieved remarkable success in various naturallanguageprocessing (NLP) tasks, but they may not always generalize well to specific domains or tasks. You also need to add the mlflow and sagemaker-mlflow Python packages as dependencies in the pipeline setup.
Retrieval Augmented Generation (RAG) models have emerged as a promising approach to enhance the capabilities of language models by incorporating external knowledge from large text corpora. These embeddings represent textual and visual data in a numerical format, which is essential for various naturallanguageprocessing (NLP) tasks.
In this post, we focus on processing a large collection of documents into raw text files and storing them in Amazon S3. The first allows you to run a Python script from any server or instance including a Jupyter notebook; this is the quickest way to get started. His focus is naturallanguageprocessing and computer vision.
This includes various products related to different aspects of AI, including but not limited to tools and platforms for deep learning, computer vision, naturallanguageprocessing, machine learning, cloud computing, and edge AI. This article provides an overview of AI software products worth checking out in 2024.
Word embeddings are considered as a type of representation used in naturallanguageprocessing (NLP) to capture the meaning of words in a numerical form. Word embeddings are used in naturallanguageprocessing (NLP) as a technique to represent words in a numerical format.
Retailers can deliver more frictionless experiences on the go with naturallanguageprocessing (NLP), real-time recommendation systems, and fraud detection. In our example, we use the Bidirectional Encoder Representations from Transformers (BERT) model, commonly used for naturallanguageprocessing.
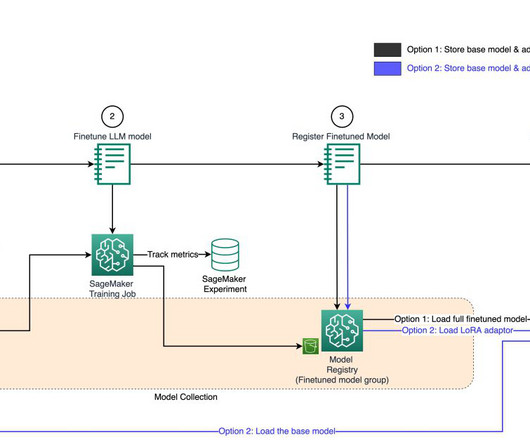
The model registry maintains records of model versions, their associated artifacts, lineage, and metadata. Model registry – This monitors the various versions of the model and the corresponding artifacts, which includes lineage and metadata. Romina’s areas of interest are naturallanguageprocessing, large language models, and MLOps.
Large language models (LLMs) have exploded in popularity over the last few years, revolutionizing naturallanguageprocessing and AI. Hybrid retrieval combines dense embeddings and sparse keyword metadata for improved recall. Cohere provides a studio for automating LLM workflows with a GUI, REST API and Python SDK.
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computer vision and naturallanguageprocessing. One of the primary reasons that customers are choosing a PyTorch framework is its simplicity and the fact that it’s designed and assembled to work with Python.
SageMaker pipeline SageMaker Pipelines offers a user-friendly Python SDK to create integrated machine learning (ML) workflows. It stores models, organizes model versions, captures essential metadata and artifacts such as container images, and governs the approval status of each model.
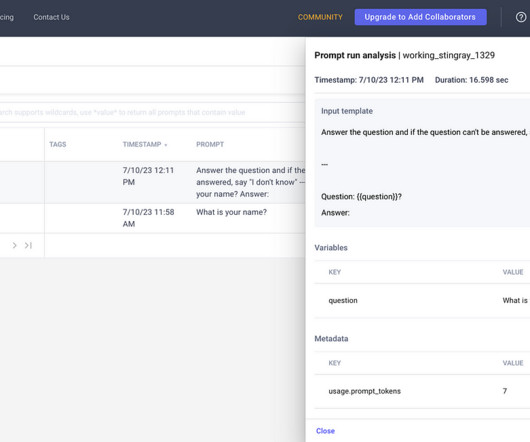
Using the LLM SDK to Log Prompts and Responses The LLM SDK supports logging prompts with its associated response and any associated metadata like token usage. metadata : Dict[str, Union[str, bool, float, None]] (optional) user-defined dictionary with additional metadata to the call. Logging full prompt and response.
LLMs, like Llama2, have shown state-of-the-art performance on naturallanguageprocessing (NLP) tasks when fine-tuned on domain-specific data. Python 3.10 Next, we fine-tune Llama2 on the databricks-dolly-15k dataset using the QLoRA method. QLoRA reduces the computational cost of fine-tuning by quantizing model weights.
Many different transformer models have already been implemented in Spark NLP, and specifically for text classification, Spark NLP provides various annotators that are designed to work with pretrained language models. Setup To install Spark NLP in Python, simply use your favorite package manager (conda, pip, etc.).
Create a Python job controller script that creates N training manifest files, one for each training run, and submits the jobs to the EKS cluster. script, you likely need to run a Python job to preprocess the data. Create a W&B sweep config file containing all hyperparameters that need to be swept and their ranges.
The impact of NaturalLanguageProcessing in everyday life is hard to ignore as it is the main driver of emerging technologies like Robotics, Big Data, Internet of Things, etc. It enables machines to process massive amounts of data and make informed decisions.
In machine learning, experiment tracking stores all experiment metadata in a single location (database or a repository). Neptune AI ML model-building metadata may be managed and recorded using the Neptune platform. You will utilize the Python API for Neptune in this project. are all included in this.
The preparation of a naturallanguageprocessing (NLP) dataset abounds with share-nothing parallelism opportunities. FSx for Lustre uses distributed file storage (stripping) and physically separates file metadata from file content to achieve high-performance read/writes.
Jupyter notebooks can differentiate between SQL and Python code using the %%sm_sql magic command, which must be placed at the top of any cell that contains SQL code. This command signals to JupyterLab that the following instructions are SQL commands rather than Python code. In his free time, he enjoys playing chess and traveling.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content