This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Process Data Lambda function redacts sensitive data through Amazon Comprehend. Amazon Comprehend provides real-time APIs, such as DetectPiiEntities and DetectEntities , which use naturallanguageprocessing (NLP) machine learning (ML) models to identify text portions for redaction.
This new capability integrates the power of graph data modeling with advanced naturallanguageprocessing (NLP). You can also supply a custom metadata file (each up to 10 KB) for each document in the knowledge base. More specifically, the graph created will connect chunks to documents, and entities to chunks.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
I have written short summaries of 68 different research papers published in the areas of Machine Learning and NaturalLanguageProcessing. Additive embeddings are used for representing metadata about each note. Nature Communications 2024. They cover a wide range of different topics, authors and venues.
Generative AI uses an advanced form of machine learning algorithms that takes users prompts and uses naturallanguageprocessing (NLP) to generate answers to almost any question asked. Automatic capture of model metadata and facts provide audit support while driving transparent and explainable model outcomes.
It stores models, organizes model versions, captures essential metadata and artifacts such as container images, and governs the approval status of each model. She has expertise in Machine Learning, covering naturallanguageprocessing, computer vision, and time-series analysis.
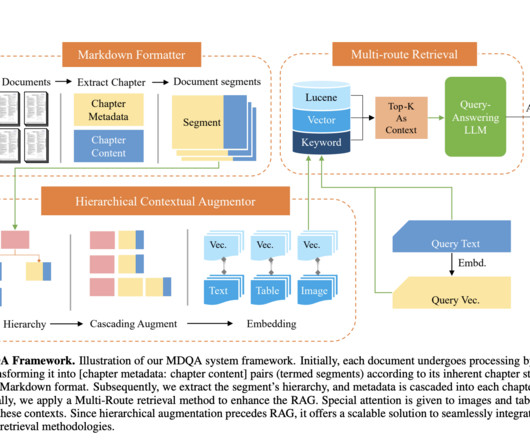
A significant challenge with question-answering (QA) systems in NaturalLanguageProcessing (NLP) is their performance in scenarios involving extensive collections of documents that are structurally similar or ‘indistinguishable.’
Third, the NLP Preset is capable of combining tabular data with NLP or NaturalLanguageProcessing tools including pre-trained deep learning models and specific feature extractors. Next, the LightAutoML inner datasets contain CV iterators and metadata that implement validation schemes for the datasets.
Artificial Intelligence is a very vast branch in itself with numerous subfields including deep learning, computer vision , naturallanguageprocessing , and more.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. It automates capturing model metadata and increases predictive accuracy to identify how AI tools are used and where model training needs to be done again. Track models and drive transparent processes.
Solution overview Data and metadata discovery is one of the primary requirements in data analytics, where data consumers explore what data is available and in what format, and then consume or query it for analysis. But in the case of unstructured data, metadata discovery is challenging because the raw data isn’t easily readable.
In NaturalLanguageProcessing (NLP) tasks, data cleaning is an essential step before tokenization, particularly when working with text data that contains unusual word separations such as underscores, slashes, or other symbols in place of spaces. The post Is There a Library for Cleaning Data before Tokenization?
However, as technology advanced, so did the complexity and capabilities of AI music generators, paving the way for deep learning and NaturalLanguageProcessing (NLP) to play pivotal roles in this tech. Initially, the attempts were simple and intuitive, with basic algorithms creating monotonous tunes.
Intelligent insights and recommendations Using its large knowledge base and advanced naturallanguageprocessing (NLP) capabilities, the LLM provides intelligent insights and recommendations based on the analyzed patient-physician interaction. These insights can include: Potential adverse event detection and reporting.
In this article, we will discuss the top Text Annotation tools for NaturalLanguageProcessing along with their characteristic features. Overview of Text Annotation Human language is highly diverse and is sometimes hard to decode for machines. It annotates images, videos, text documents, audio, and HTML, etc.
Participants learn to build metadata for documents containing text and images, retrieve relevant text chunks, and print citations using Multimodal RAG with Gemini. NaturalLanguageProcessing on Google Cloud This course introduces Google Cloud products and solutions for solving NLP problems.
Voice-based queries use naturallanguageprocessing (NLP) and sentiment analysis for speech recognition so their conversations can begin immediately. With text to speech and NLP, AI can respond immediately to texted queries and instructions. Humanize HR AI can attract, develop and retain a skills-first workforce.
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. Encoder-decoder and decoder-only large language models are available in the Prompt Lab today. To bridge the tuning gap, watsonx.ai
Previously, you had a choice between human-based model evaluation and automatic evaluation with exact string matching and other traditional naturallanguageprocessing (NLP) metrics. These methods, though fast, didnt provide a strong correlation with human evaluators.
In addition, the Amazon Bedrock Knowledge Bases team worked closely with us to address several critical elements, including expanding embedding limits, managing the metadata limit (250 characters), testing different chunking methods, and syncing throughput to the knowledge base.
Experts can check hard drives, metadata, data packets, network access logs or email exchanges to find, collect, and process information. They can use machine learning (ML), naturallanguageprocessing (NLP) and generative models for pattern recognition, predictive analysis, information seeking, or collaborative brainstorming.
AI content detectors use a combination of machine learning (ML), naturallanguageprocessing (NLP), and pattern recognition techniques to differentiate AI-generated content from human-generated content. AI detectors identify whether text, images, and videos are artificially generated or created by humans.
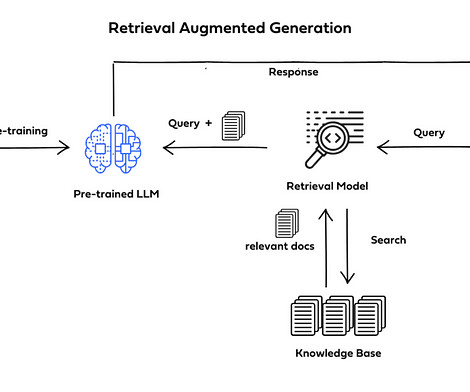
Retrieval-Augmented Generation (RAG) is a cutting-edge method of naturallanguageprocessing that produces precise and contextually relevant answers by fusing the strength of large language models (LLMs) with an external knowledge retrieval system. _pages_and_chunks( pages_and_texts ) # Create chunks with metadata.
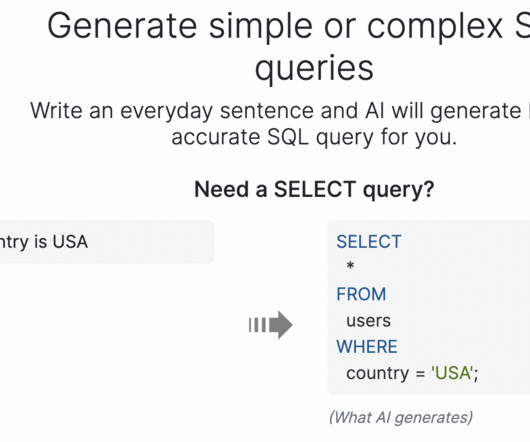
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. This generative AI task is called text-to-SQL, which generates SQL queries from naturallanguageprocessing (NLP) and converts text into semantically correct SQL.
Clinical data abstraction refers to the process of finding and recording relevant administrative and clinical data pieces. This NLP clinical solution collects data for administrative coding tasks, quality improvement, patient registry functions, and clinical research.
Using naturallanguageprocessing (NLP) and OpenAPI specs, Amazon Bedrock Agents dynamically manages API sequences, minimizing dependency management complexities. Set up the policy documents and metadata in the data source for the knowledge base We use Amazon Bedrock Knowledge Bases to manage our documents and metadata.
Large language models (LLMs) are revolutionizing fields like search engines, naturallanguageprocessing (NLP), healthcare, robotics, and code generation. A media metadata store keeps the promotion movie list up to date. A feature store maintains user profile data.
Scientific metadata in research literature holds immense significance, as highlighted by flourishing research in scientometricsa discipline dedicated to analyzing scholarly literature. Metadata improves the findability and accessibility of scientific documents by indexing and linking papers in a massive graph.
By understanding its significance, readers can grasp how it empowers advancements in AI and contributes to cutting-edge innovation in naturallanguageprocessing. By incorporating metadata tagging and maintaining a transparent development process, the dataset promotes both usability and adaptability for cutting-edge AI research.
Artificial intelligence chatbots have been trained to have conversations that resemble those of humans using naturallanguageprocessing (NLP). NLP enables the AI chatbot to comprehend written human language, allowing them to function independently.
Unlike many naturallanguageprocessing (NLP) models, which were historically dominated by recurrent neural networks (RNNs) and, more recently, transformers, wav2letter is designed entirely using convolutional neural networks (CNNs). Despite this, it remains widely recognized by its original name, wav2letter.
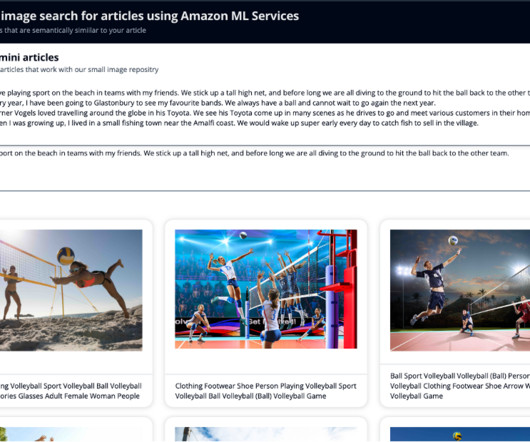
First, you extract label and celebrity metadata from the images, using Amazon Rekognition. You then generate an embedding of the metadata using a LLM. You store the celebrity names, and the embedding of the metadata in OpenSearch Service. Overview of solution The solution is divided into two main sections.
The impact of NaturalLanguageProcessing in everyday life is hard to ignore as it is the main driver of emerging technologies like Robotics, Big Data, Internet of Things, etc. It enables machines to process massive amounts of data and make informed decisions. the clinical NLP system should be able to detect it.
It interprets user input and generates suitable responses using artificial intelligence (AI) and naturallanguageprocessing (NLP). It necessitates a thorough knowledge of naturallanguageprocessing (NLP) methods. Why is NLP Required? But creating a useful chatbot is no simple task.
This method of enriching the LLM generation context with information retrieved from your internal data sources is called Retrieval Augmented Generation (RAG), and produces assistants that are domain specific and more trustworthy, as shown by Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
Sentence detection in Spark NLP is the process of identifying and segmenting a piece of text into individual sentences using the Spark NLP library. Sentence Detection in Spark NLP is the process of automatically identifying the boundaries of sentences in a given text.
Stopwords removal in naturallanguageprocessing (NLP) is the process of eliminating words that occur frequently in a language but carry little or no meaning. Stopwords cleaning in Spark NLP is the process of removing stopwords from the text data.
Businesses can use LLMs to gain valuable insights, streamline processes, and deliver enhanced customer experiences. Whether you’re a developer seeking to incorporate LLMs into your existing systems or a business owner looking to take advantage of the power of NLP, this post can serve as a quick jumpstart.
It is fueling the decision-making process in the organisation. Information retrieval systems in NLP or NaturalLanguageProcessing is the backbone of search engines, recommendation systems and chatbots. In this blog, we delve into the intricacies of Information Retrieval in NLP. Wrapping it up !!!
The Normalizer annotator in Spark NLP performs text normalization on data. The Normalizer annotator in Spark NLP is often used as part of a preprocessing step in NLP pipelines to improve the accuracy and quality of downstream analyses and models. These transformations can be configured by the user to meet their specific needs.
Using machine learning (ML) and naturallanguageprocessing (NLP) to automate product description generation has the potential to save manual effort and transform the way ecommerce platforms operate. jpg and the complete metadata from styles/38642.json.
Rule-based sentiment analysis in NaturalLanguageProcessing (NLP) is a method of sentiment analysis that uses a set of manually-defined rules to identify and extract subjective information from text data. Using Spark NLP, it is possible to analyze the sentiment in a text with high accuracy.
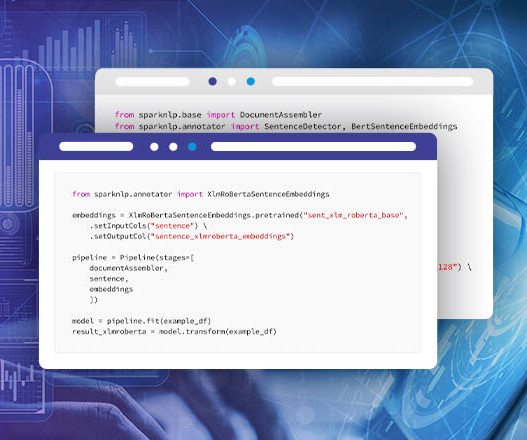
Sentence embeddings are a powerful tool in naturallanguageprocessing that helps analyze and understand language. Spark NLP has multiple solutions for producing sentence embeddings with transformers for longer pieces of text.
Word embeddings are considered as a type of representation used in naturallanguageprocessing (NLP) to capture the meaning of words in a numerical form. Word embeddings are used in naturallanguageprocessing (NLP) as a technique to represent words in a numerical format.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content