This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
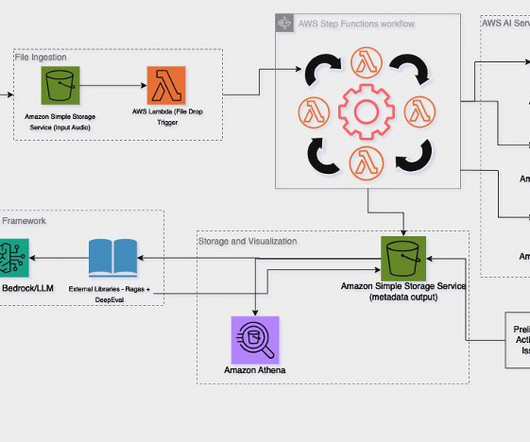
This enables the efficient processing of content, including scientific formulas and data visualizations, and the population of Amazon Bedrock Knowledge Bases with appropriate metadata. JupyterLab applications flexible and extensive interface can be used to configure and arrange machine learning (ML) workflows.
When you initiate a sync, Amazon Q will crawl the data source to extract relevant documents, then sync them to the Amazon Q index, making them searchable After syncing data sources, you can configure the metadata controls in Amazon Q Business. Joseph Mart is an AI/ML Specialist Solutions Architect at Amazon Web Services (AWS).
For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security. The role information is also used to configure metadata filtering in the knowledge bases to generate relevant responses.
Amazon Bedrock offers fine-tuning capabilities that allow you to customize these pre-trained models using proprietary call transcript data, facilitating high accuracy and relevance without the need for extensive machine learning (ML) expertise. Architecture The following diagram illustrates the solution architecture.
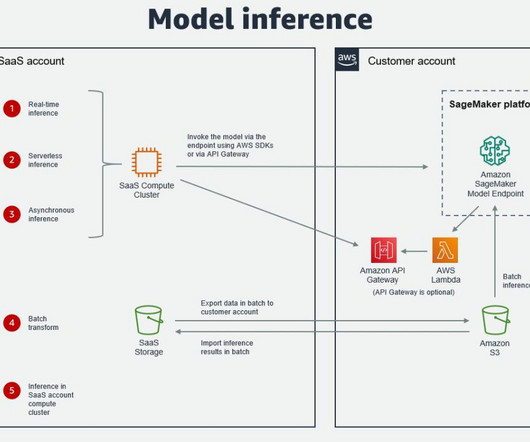
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
The connector supports the crawling of the following entities in Gmail: Email – Each email is considered a single document Attachment – Each email attachment is considered a single document Additionally, supported custom metadata and custom objects are also crawled during the sync process. Vineet Kachhawaha is a Sr.
Many organizations choose SageMaker as their ML platform because it provides a common set of tools for developers and data scientists. This is usually in a dedicated customer AWS account, meaning there still needs to be cross-account access to the customer AWS account where SageMaker is running.
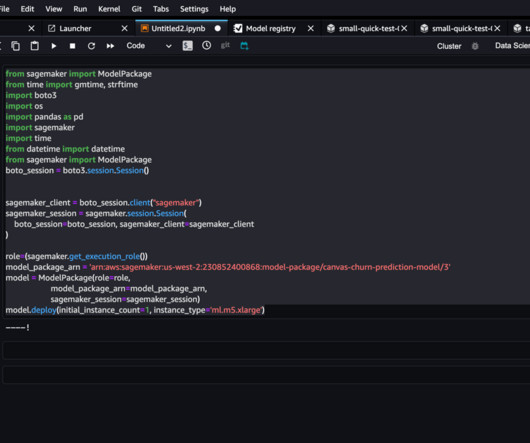
You can now register machine learning (ML) models built in Amazon SageMaker Canvas with a single click to the Amazon SageMaker Model Registry , enabling you to operationalize ML models in production. Build ML models and analyze their performance metrics.
This solution simplifies the integration of advanced monitoring tools such as Prometheus and Grafana, enabling you to set up and manage your machine learning (ML) workflows with AWS AI Chips. By deploying the Neuron Monitor DaemonSet across EKS nodes, developers can collect and analyze performance metrics from ML workload pods.
SageMaker JumpStart is a machine learning (ML) hub that provides a wide range of publicly available and proprietary FMs from providers such as AI21 Labs, Cohere, Hugging Face, Meta, and Stability AI, which you can deploy to SageMaker endpoints in your own AWS account. It’s serverless so you don’t have to manage the infrastructure.
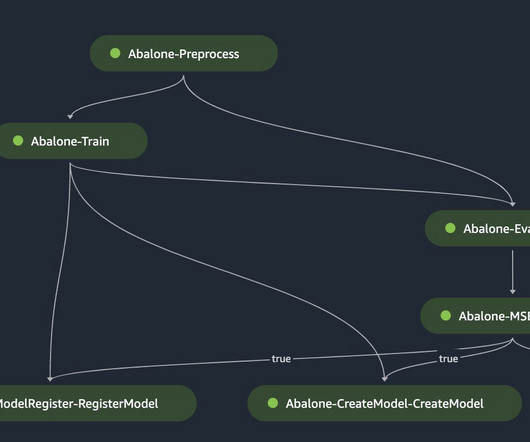
You can use Amazon SageMaker Model Building Pipelines to collaborate between multiple AI/ML teams. SageMaker Pipelines You can use SageMaker Pipelines to define and orchestrate the various steps involved in the ML lifecycle, such as data preprocessing, model training, evaluation, and deployment.
It stores models, organizes model versions, captures essential metadata and artifacts such as container images, and governs the approval status of each model. About the Authors Alston Chan is a SoftwareDevelopment Engineer at Amazon Ads. Outside of work, he enjoys game development and rock climbing.
It also enables economies of scale with development velocity given that over 75 engineers at Octus already use AWS services for application development. This includes file type verification, size validation, and metadata extraction before routing to Amazon Textract.
In this comprehensive guide, we’ll explore the key concepts, challenges, and best practices for ML model packaging, including the different types of packaging formats, techniques, and frameworks. These teams may include but are not limited to data scientists, softwaredevelopers, machine learning engineers, and DevOps engineers.
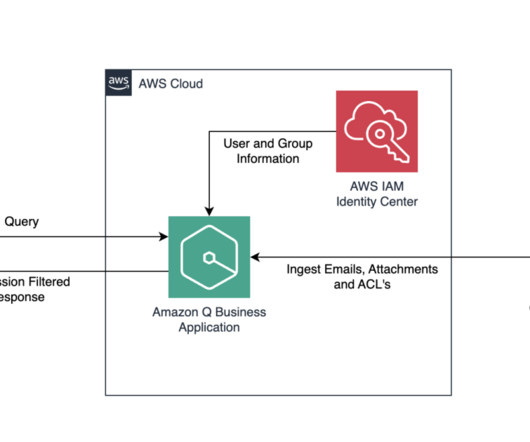
Additionally, they want access to metadata, timestamps, and access control lists (ACLs) for the indexed documents. Crawling stage The first stage is the crawling stage, where the connector crawls all documents and their metadata from the data source. The following diagram shows a flowchart of a sync run job.
A document is a collection of information that consists of a title, the content (or the body), metadata (data about the document) and access control list (ACL) information to make sure answers are provided from documents that the user has access to. Amazon Q supports the crawling and indexing of these custom objects and custom metadata.
We use HuggingFaces Optimum-Neuron softwaredevelopment kit (SDK) to apply LoRA to fine-tuning jobs, and use SageMaker HyperPod as the primary compute cluster to perform distributed training on Trainium. After a few minutes, its status should change from Creating to InService. Modify permissions and ssh chmod +x easy-ssh.sh./easy-ssh.sh
You then format these pairs as individual text files with corresponding metadata JSON files , upload them to an S3 bucket, and ingest them into your cache knowledge base. Chaithanya Maisagoni is a Senior SoftwareDevelopment Engineer (AI/ML) in Amazons Worldwide Returns and ReCommerce organization.
In this article, you will learn about: the challenges plaguing the ML space and why conventional tools are not the right answer to them. ML model versioning: where are we at? Further, maintaining model versions will save the risk of losing the model details in case the original model developer is longer working on the project.
To further boost these capabilities, OpenSearch offers advanced features, such as: Connector for Amazon Bedrock You can seamlessly integrate Amazon Bedrock machine learning (ML) models with OpenSearch through built-in connectors for services, enabling direct access to advanced ML features.
In this example, the ML engineering team is borrowing 5 GPUs for their training task With SageMaker HyperPod, you can additionally set up observability tools of your choice. metadata: name: job-name namespace: hyperpod-ns-researchers labels: kueue.x-k8s.io/queue-name: queue-name: hyperpod-ns-researchers-localqueue kueue.x-k8s.io/priority-class:
ML Engineer at Tiger Analytics. The large machine learning (ML) model development lifecycle requires a scalable model release process similar to that of softwaredevelopment. Model developers often work together in developingML models and require a robust MLOps platform to work in.
Amazon Kendra is an intelligent search service powered by machine learning (ML). Additionally, you might need access to metadata, timestamps, and access control lists (ACLs) for the indexed documents. Crawling stage The first stage is the crawling stage, where the connector crawls all documents and their metadata from the data source.
Amazon Kendra is a highly accurate and simple-to-use intelligent search service powered by machine learning (ML). In addition, the ML-powered intelligent search can accurately get answers for your questions from unstructured documents with natural language narrative content, for which keyword search is not very effective.
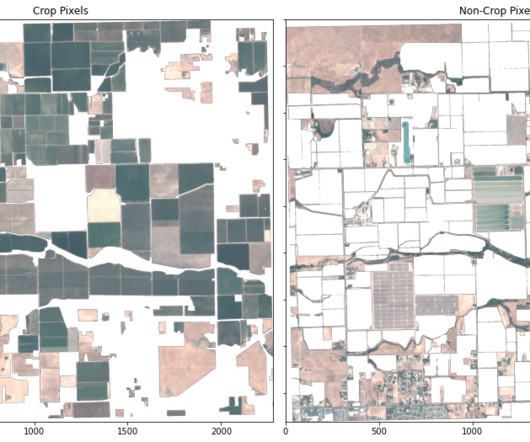
In this post, we illustrate how to use a segmentation machine learning (ML) model to identify crop and non-crop regions in an image. Identifying crop regions is a core step towards gaining agricultural insights, and the combination of rich geospatial data and ML can lead to insights that drive decisions and actions.
In a terminal with the AWS Command Line Interface (AWS CLI) or AWS CloudShell , run the following commands to upload the documents to the data source bucket: aws s3 cp s3://aws-ml-blog/artifacts/building-a-secure-search-application-with-access-controls-kendra/docs.zip. In the IAM role section, select Create new service role (Recommended).
Machine learning (ML) models do not operate in isolation. To deliver value, they must integrate into existing production systems and infrastructure, which necessitates considering the entire ML lifecycle during design and development. GitHub serves as a centralized location to store, version, and manage your ML code base.
Solution overview The LMA sample solution captures speaker audio and metadata from your browser-based meeting app (as of this writing, Zoom and Chime are supported), or audio only from any other browser-based meeting app, softphone, or audio source. Inventory list of meetings – LMA keeps track of all your meetings in a searchable list.
In this example, were using Smartsheet to track tasks for a softwaredevelopment project. These reports provide comprehensive and detailed insights integrated into the sync history, including granular indexing status, metadata, and access control list (ACL) details for every document processed during a data source sync job.
MLOps is a key discipline that often oversees the path to productionizing machine learning (ML) models. MLOps tooling helps you repeatably and reliably build and simplify these processes into a workflow that is tailored for ML. It’s natural to focus on a single model that you want to train and deploy.
Just so you know where I am coming from: I have a heavy softwaredevelopment background (15+ years in software). Came to ML from software. Founded two successful software services companies. Founded neptune.ai , a modular MLOps component for MLmetadata store , aka “experiment tracker + model registry”.
This shift in thinking has led us to DevSecOps , a novel methodology that integrates security into the softwaredevelopment/ MLOps process. This enables the developers to write code with security in mind, thus reducing development time to a great extent. Where and Why is Data Security Required in the MLOps Lifecycle?
Next, we present the solution architecture and process flows for machine learning (ML) model building, deployment, and inferencing. Here, Amazon SageMaker Ground Truth allowed ML engineers to easily build the human-in-the-loop workflow (step v). Burak Gozluklu is a Principal AI/ML Specialist Solutions Architect located in Boston, MA.
Combining accurate transcripts with Genesys CTR files, Principal could properly identify the speakers, categorize the calls into groups, analyze agent performance, identify upsell opportunities, and conduct additional machine learning (ML)-powered analytics.
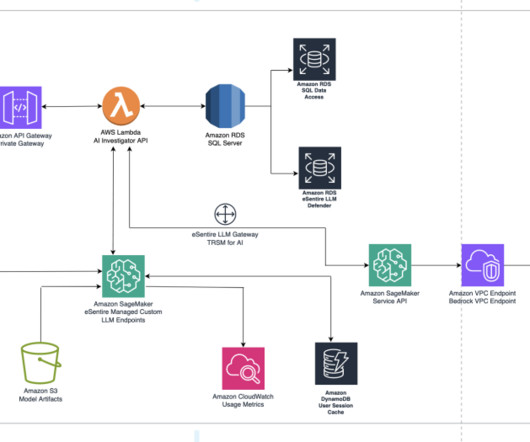
eSentire used gigabytes of additional human investigation metadata to perform supervised fine-tuning on Llama 2. All of this was entirely automated with the softwaredevelopment lifecycle (SDLC) using Terraform and GitHub, which is only possible through SageMaker ecosystem.
A document is a collection of information that consists of a title, the content (or the body), metadata (data about the document), and access control list (ACL) information to make sure answers are provided from documents that the user has access to. Amazon Q supports the crawling and indexing of these custom objects and custom metadata.
Amazon SageMaker Studio is a fully integrated development environment (IDE) for machine learning (ML) partly based on JupyterLab 3. Studio provides a web-based interface to interactively perform MLdevelopment tasks required to prepare data and build, train, and deploy ML models. AWS CDK scripts.
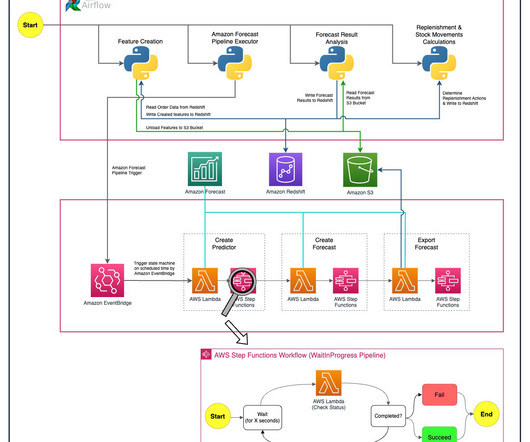
Getir used Amazon Forecast , a fully managed service that uses machine learning (ML) algorithms to deliver highly accurate time series forecasts, to increase revenue by four percent and reduce waste cost by 50 percent. As previously mentioned, CNN-QR can employ related time series and metadata about the items being forecasted.
This allows machine learning (ML) practitioners to rapidly launch an Amazon Elastic Compute Cloud (Amazon EC2) instance with a ready-to-use deep learning environment, without having to spend time manually installing and configuring the required packages. You also need the ML job scripts ready with a command to invoke them.
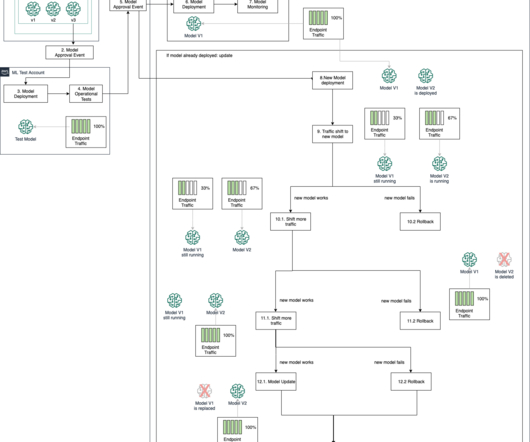
After you build, train, and evaluate your machine learning (ML) model to ensure it’s solving the intended business problem proposed, you want to deploy that model to enable decision-making in business operations. SageMaker deployment guardrails Guardrails are an essential part of softwaredevelopment.
This approach allows for greater flexibility and integration with existing AI and machine learning (AI/ML) workflows and pipelines. By providing multiple access points, SageMaker JumpStart helps you seamlessly incorporate pre-trained models into your AI/MLdevelopment efforts, regardless of your preferred interface or workflow.
Developers can use Amazon Personalize to build applications powered by the same type of machine learning (ML) technology used by Amazon.com for real-time personalized recommendations. With Amazon Personalize, developers can improve user engagement through personalized product and content recommendations with no ML expertise required.
SageMaker JumpStart SageMaker JumpStart is a powerful feature within the Amazon SageMaker ML platform that provides ML practitioners a comprehensive hub of publicly available and proprietary foundation models. She has over 15 years of IT experience in softwaredevelopment, design and architecture.
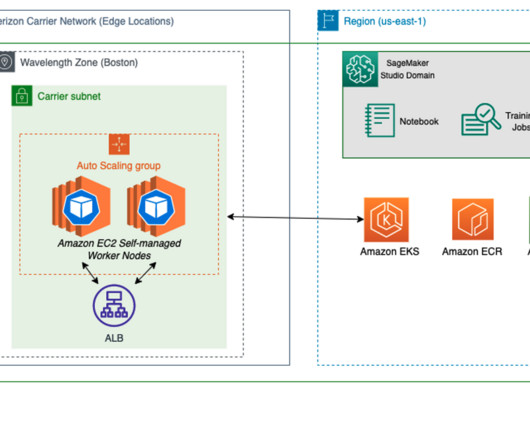
As one of the most prominent use cases to date, machine learning (ML) at the edge has allowed enterprises to deploy ML models closer to their end-customers to reduce latency and increase responsiveness of their applications. Even ground and aerial robotics can use ML to unlock safer, more autonomous operations.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content