This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
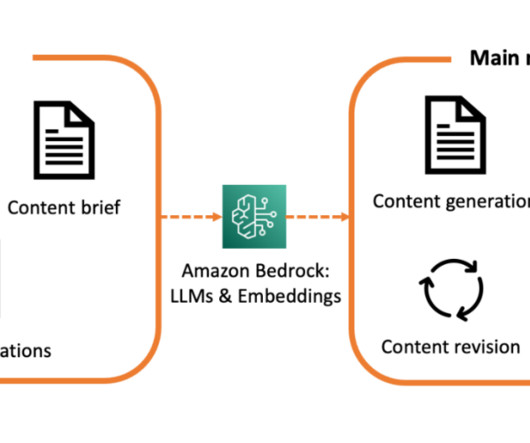
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
Customizable Uses promptengineering , which enables customization and iterative refinement of the prompts used to drive the large language model (LLM), allowing for refining and continuous enhancement of the assessment process. Metadata filtering is used to improve retrieval accuracy.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
By documenting the specific model versions, fine-tuning parameters, and promptengineering techniques employed, teams can better understand the factors contributing to their AI systems performance. SageMaker is a data, analytics, and AI/ML platform, which we will use in conjunction with FMEval to streamline the evaluation process.
SageMaker JumpStart is a machine learning (ML) hub that provides a wide range of publicly available and proprietary FMs from providers such as AI21 Labs, Cohere, Hugging Face, Meta, and Stability AI, which you can deploy to SageMaker endpoints in your own AWS account. It’s serverless so you don’t have to manage the infrastructure.
Sensitive information disclosure is a risk with LLMs because malicious promptengineering can cause LLMs to accidentally reveal unintended details in their responses. You can build a segmented access solution on top of a knowledge base using metadata and filtering feature. This can lead to privacy and confidentiality violations.
Introduction PromptEngineering is arguably the most critical aspect in harnessing the power of Large Language Models (LLMs) like ChatGPT. However; current promptengineering workflows are incredibly tedious and cumbersome. Logging prompts and their outputs to .csv First install the package via pip.
Machine learning (ML) engineers must make trade-offs and prioritize the most important factors for their specific use case and business requirements. You can use metadata filtering to narrow down search results by specifying inclusion and exclusion criteria. Nitin Eusebius is a Sr.
Introduction to AI and Machine Learning on Google Cloud This course introduces Google Cloud’s AI and ML offerings for predictive and generative projects, covering technologies, products, and tools across the data-to-AI lifecycle. It includes labs on feature engineering with BigQuery ML, Keras, and TensorFlow.
One such component is a feature store, a tool that stores, shares, and manages features for machine learning (ML) models. Features are the inputs used during training and inference of ML models. Amazon SageMaker Feature Store is a fully managed repository designed specifically for storing, sharing, and managing ML model features.
Used alongside other techniques such as promptengineering, RAG, and contextual grounding checks, Automated Reasoning checks add a more rigorous and verifiable approach to enhancing the accuracy of LLM-generated outputs.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. Create a simple web application using LangChain and Streamlit.
Introduction to Large Language Models Difficulty Level: Beginner This course covers large language models (LLMs), their use cases, and how to enhance their performance with prompt tuning. Students will learn to write precise prompts, edit system messages, and incorporate prompt-response history to create AI assistant and chatbot behavior.
SageMaker JumpStart is a machine learning (ML) hub with foundation models (FMs), built-in algorithms, and prebuilt ML solutions that you can deploy with just a few clicks. This post walks through examples of building information extraction use cases by combining LLMs with promptengineering and frameworks such as LangChain.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. IBM watsonx.ai With watsonx.ai, businesses can effectively train, validate, tune and deploy AI models with confidence and at scale across their enterprise.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
Experts can check hard drives, metadata, data packets, network access logs or email exchanges to find, collect, and process information. They can use machine learning (ML), natural language processing (NLP) and generative models for pattern recognition, predictive analysis, information seeking, or collaborative brainstorming.
Although these traditional machine learning (ML) approaches might perform decently in terms of accuracy, there are several significant advantages to adopting generative AI approaches. The following table compares the generative approach (generative AI) with the discriminative approach (traditional ML) across multiple aspects.
The embedding representations of text chunks along with related metadata are indexed in OpenSearch Service. Text embedding models are machine learning (ML) models that map words or phrases from text to dense vector representations. join(context) return context The input question is combined with retrieved context to create a prompt.
Evaluating a RAG solution Contrary to traditional machine learning (ML) models, for which evaluation metrics are well defined and straightforward to compute, evaluating a RAG framework is still an open problem. Try metadata filtering in your OpenSearch index. Try using query rewriting to get the right metadata filtering.
Additionally, VitechIQ includes metadata from the vector database (for example, document URLs) in the model’s output, providing users with source attribution and enhancing trust in the generated answers. PromptengineeringPromptengineering is crucial for the knowledge retrieval system.
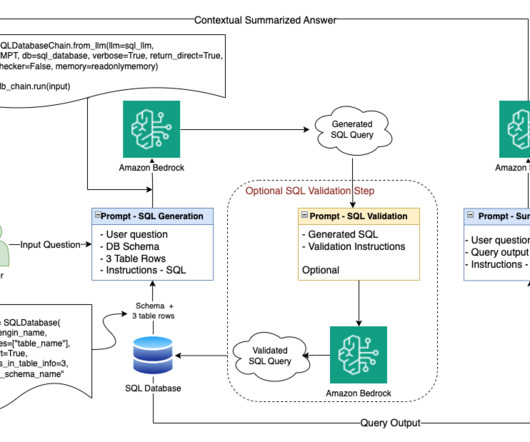
An AWS Glue crawler is scheduled to run at frequent intervals to extract metadata from databases and create table definitions in the AWS Glue Data Catalog. LangChain, a tool to work with LLMs and prompts, is used in Studio notebooks. However, these databases must have their metadata registered with the AWS Glue Data Catalog.
The workflow for NLQ consists of the following steps: A Lambda function writes schema JSON and table metadata CSV to an S3 bucket. The wrapper function reads the table metadata from the S3 bucket. The wrapper function creates a dynamic prompt template and gets relevant tables using Amazon Bedrock and LangChain.
We provide a list of reviews as context and create a prompt to generate an output with a concise summary, overall sentiment, confidence score of the sentiment, and action items from the input reviews. Our example prompt requests the FM to generate the response in JSON format. Outside of work, he is passionate about travel and driving.
For this purpose, we use Amazon Textract, a machine learning (ML) service for entity recognition and extraction. We use promptengineering to send our summarization instructions to the LLM. Importantly, when performed, summarization should preserve as much article’s metadata as possible, such as the title, authors, date, etc.
Given the right context, metadata, and instructions, a well-selected general purpose LLM can produce good-quality SQL as long as it has access to the right domain-specific context. Further performance optimization involved fine-tuning the query generation process using efficient promptengineering techniques.
You can customize the model using promptengineering, Retrieval Augmented Generation (RAG), or fine-tuning. Fine-tuning an LLM can be a complex workflow for data scientists and machine learning (ML) engineers to operationalize. Each iteration can be considered a run within an experiment.
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from scanned documents. Amazon Comprehend is a natural language processing (NLP) service that uses ML to extract insights from text. Use the prompt to construct a structured query, using an LLM, to derive the data from the table.
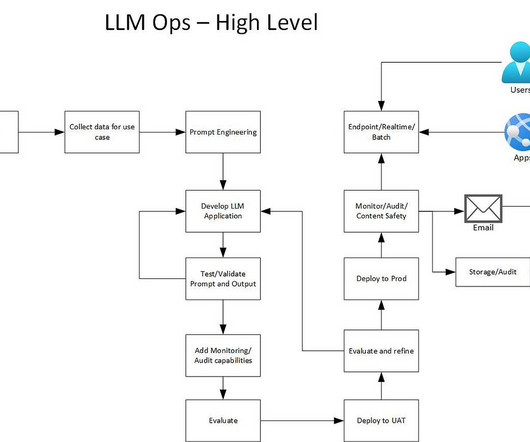
Introduction Create ML Ops for LLM’s Build end to end development and deployment cycle. PromptEngineering — this is where figuring out what is the right prompt to use for the problem. Storage all prompts and completions in a data lake for future use and also metadata about api, configurations etc.
AWS delivers services that meet customers’ artificial intelligence (AI) and machine learning (ML) needs with services ranging from custom hardware like AWS Trainium and AWS Inferentia to generative AI foundation models (FMs) on Amazon Bedrock. Amazon SageMaker JumpStart is an ML hub that can helps you accelerate your ML journey.
This includes sales collateral, customer engagements, external web data, machine learning (ML) insights, and more. AI-driven recommendations – By combining generative AI with ML, we deliver intelligent suggestions for products, services, applicable use cases, and next steps.
As promptengineering is fundamentally different from training machine learning models, Comet has released a new SDK tailored for this use case comet-llm. In this article you will learn how to log the YOLOPandas prompts with comet-llm, keep track of the number of tokens used in USD($), and log your metadata.
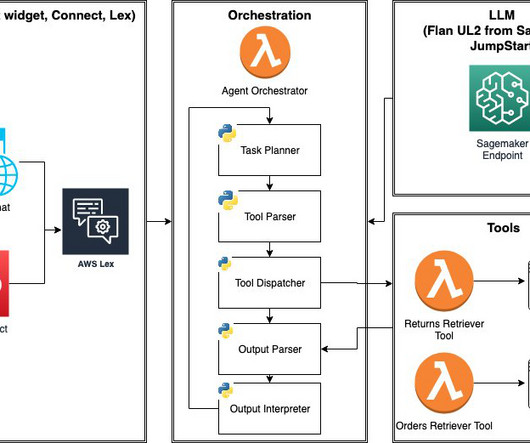
Often, these LLMs require some metadata about available tools (descriptions, yaml, or JSON schema for their input parameters) in order to output tool invocations. We use promptengineering only and Flan-UL2 model as-is without fine-tuning. You have access to the following tools.
Of course, all of the things that control vector does can be done through promptengineering as well as one can consider control vector to be an “addition” to the prompt that is provided by the user. This is where metadata comes in. Metadata is essentially data about data.
Specifically, Vidmob analyzes the client ad campaigns and extracts information related to the ads using various machine learning (ML) models and AWS services. He specializes in building ML pipelines using Large Language Models, primarily through Amazon Bedrock and other AWS Cloud services.
Additionally, evaluation can identify potential biases, hallucinations, inconsistencies, or factual errors that may arise from the integration of external sources or from sub-optimal promptengineering. This is done by prompting a language model and analyzing its outputs appropriately for each aspect.
This article was originally an episode of the ML Platform Podcast , a show where Piotr Niedźwiedź and Aurimas Griciūnas, together with ML platform professionals, discuss design choices, best practices, example tool stacks, and real-world learnings from some of the best ML platform professionals. Stefan: Yeah.
Comet’s LLMOps tools are focused on quicker iterations for the following: Prompt History: Keeping track of prompts, responses, and chains is critical to understanding and debugging the behavior of ML products based on Large Language Models. Comet’s LLMOps tool provides an intuitive and responsive view of our prompt history.
” – Zain Hasan, Senior ML Developer Advocate at Weaviate “An under-discussed yet crucial question is how to ensure that LLMs can be trained in a way that respects user privacy and does not rely on exploiting vast amounts of personal data.” solves this problem by extracting metadata during the data preparation process.
Shutterstock Datasets and AI-generated Content: Contributor FAQ They present this as a responsible and ethical approach to AI-generated content but I think they tend to overestimate the role of the individual training images and underestimate the role of promptengineering.
outputsearch)), Char(10),""), """","") Goal is to use semantic search get the top 3 docs and then pass that with promptengineering to chatgpt and get the response back and display it in power apps original article — Samples2023/pinesearchgpt.md
These models offer tremendous potential but also bring a unique set of challenges when it comes to building large-scale ML projects. Naturally, training a machine learning model (regardless of the problem being solved or the particular model architecture that was chosen) is a key part of every ML project. But what happens next?
Post-Retrieval Next, the RAG model augments the user input (or prompts) by adding the relevant retrieved data in context (query + context). This step uses promptengineering techniques to communicate effectively with the LLM. Remove unnecessary information such as special characters, unwanted metadata, or text.
Getting Started With Comet LLMOps Comet’s LLMOps toolkit opens the door to cutting-edge advancements in prompt management, offering users a gateway to expedited iterations, improved identification of performance bottlenecks, and a visual journey through the inner workings of prompt chains within Comet’s ecosystem.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


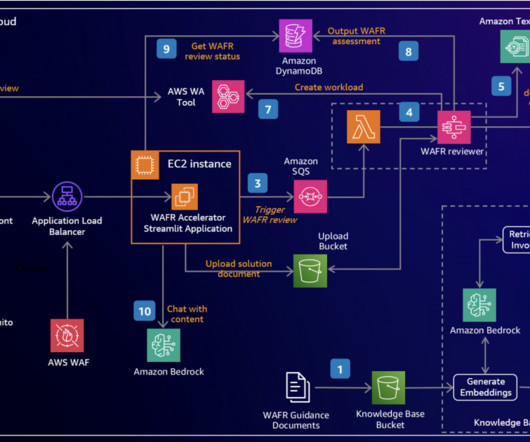




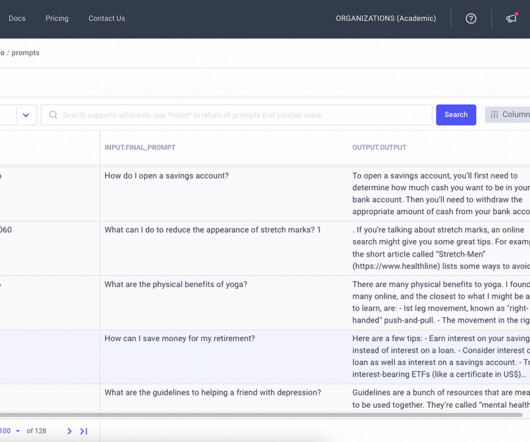














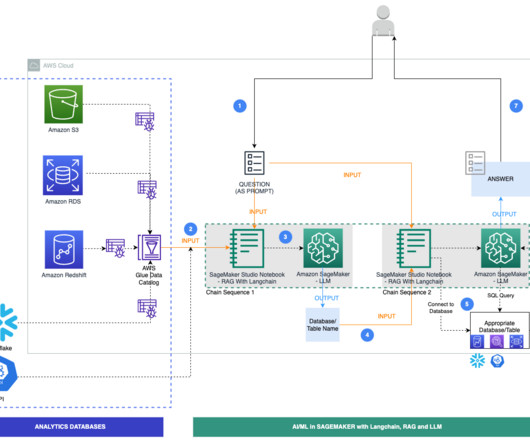

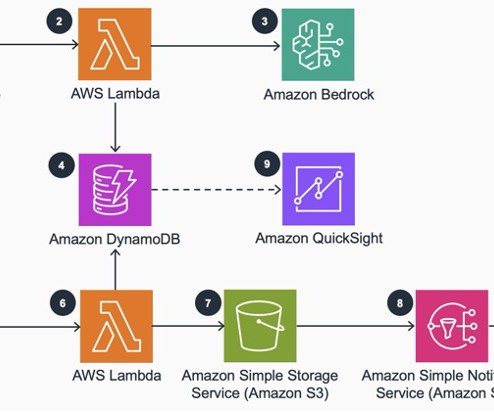


















Let's personalize your content