This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
From Solo Notebooks to Collaborative Powerhouse: VS Code Extensions for Data Science and ML Teams Photo by Parabol | The Agile Meeting Toolbox on Unsplash In this article, we will explore the essential VS Code extensions that enhance productivity and collaboration for data scientists and machine learning (ML) engineers.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. Recent developments in generative AI models have further sped up the need of ML adoption across industries.
Real-world applications vary in inference requirements for their artificial intelligence and machine learning (AI/ML) solutions to optimize performance and reduce costs. SageMaker Model Monitor monitors the quality of SageMaker ML models in production. Your client applications invoke this endpoint to get inferences from the model.
This post explores how Amazon SageMaker AI with MLflow can help you as a developer and a machine learning (ML) practitioner efficiently experiment, evaluate generative AI agent performance, and optimize their applications for production readiness.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
FMEval is an open source LLM evaluation library, designed to provide data scientists and machine learning (ML) engineers with a code-first experience to evaluate LLMs for various aspects, including accuracy, toxicity, fairness, robustness, and efficiency. This allows you to keep track of your ML experiments.
Data preparation isn’t just a part of the MLengineering process — it’s the heart of it. Data is a key differentiator in ML projects (more on this in my blog post below). This post dives into key steps for preparing data to build real-world ML systems. This member-only story is on us. Upgrade to access all of Medium.
Introduction to AI and Machine Learning on Google Cloud This course introduces Google Cloud’s AI and ML offerings for predictive and generative projects, covering technologies, products, and tools across the data-to-AI lifecycle. It includes labs on feature engineering with BigQuery ML, Keras, and TensorFlow.
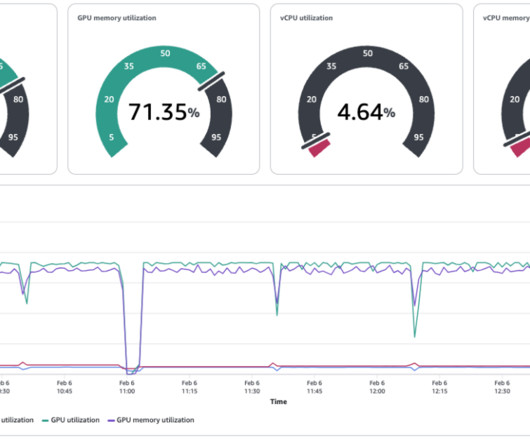
This solution simplifies the integration of advanced monitoring tools such as Prometheus and Grafana, enabling you to set up and manage your machine learning (ML) workflows with AWS AI Chips. By deploying the Neuron Monitor DaemonSet across EKS nodes, developers can collect and analyze performance metrics from ML workload pods.
Its scalability and load-balancing capabilities make it ideal for handling the variable workloads typical of machine learning (ML) applications. Amazon SageMaker provides capabilities to remove the undifferentiated heavy lifting of building and deploying ML models. They often work with DevOps engineers to operate those pipelines.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Third, despite the larger adoption of centralized analytics solutions like data lakes and warehouses, complexity rises with different table names and other metadata that is required to create the SQL for the desired sources.
You can use Amazon SageMaker Model Building Pipelines to collaborate between multiple AI/ML teams. SageMaker Pipelines You can use SageMaker Pipelines to define and orchestrate the various steps involved in the ML lifecycle, such as data preprocessing, model training, evaluation, and deployment.
Artificial intelligence (AI) and machine learning (ML) are becoming an integral part of systems and processes, enabling decisions in real time, thereby driving top and bottom-line improvements across organizations. However, putting an ML model into production at scale is challenging and requires a set of best practices.
Since then, TR has achieved many more milestones as its AI products and services are continuously growing in number and variety, supporting legal, tax, accounting, compliance, and news service professionals worldwide, with billions of machine learning (ML) insights generated every year. The challenges. Solution overview.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
This approach allows for greater flexibility and integration with existing AI and machine learning (AI/ML) workflows and pipelines. By providing multiple access points, SageMaker JumpStart helps you seamlessly incorporate pre-trained models into your AI/ML development efforts, regardless of your preferred interface or workflow.
In this example, the MLengineering team is borrowing 5 GPUs for their training task With SageMaker HyperPod, you can additionally set up observability tools of your choice. metadata: name: job-name namespace: hyperpod-ns-researchers labels: kueue.x-k8s.io/queue-name: queue-name: hyperpod-ns-researchers-localqueue kueue.x-k8s.io/priority-class:
In the ever-evolving landscape of machine learning, feature management has emerged as a key pain point for MLEngineers at Airbnb. Chronon empowers ML practitioners to define features and centralize data computation for model training and production inference, guaranteeing accuracy and consistency throughout the process.
Machine learning (ML) engineers must make trade-offs and prioritize the most important factors for their specific use case and business requirements. You can use metadata filtering to narrow down search results by specifying inclusion and exclusion criteria. Nitin Eusebius is a Sr.
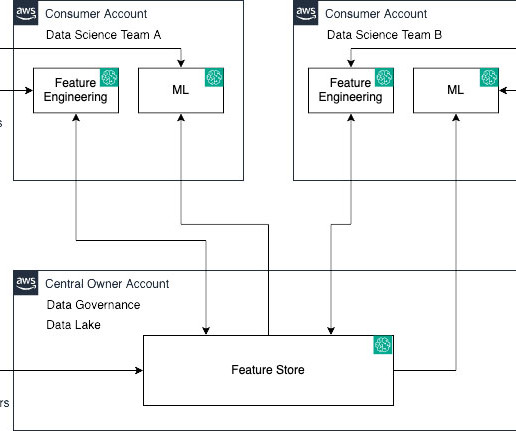
Amazon SageMaker Feature Store is a fully managed, purpose-built repository to store, share, and manage features for machine learning (ML) models. Features are inputs to ML models used during training and inference. SageMaker Feature Store now makes it effortless to share, discover, and access feature groups across AWS accounts.
Secondly, to be a successful MLengineer in the real world, you cannot just understand the technology; you must understand the business. Some typical examples are given in the following table, along with some discussion as to whether or not ML would be an appropriate tool for solving the problem: Figure 1.1:
When working on real-world machine learning (ML) use cases, finding the best algorithm/model is not the end of your responsibilities. Reusability & reproducibility: Building ML models is time-consuming by nature. Save vs package vs store ML models Although all these terms look similar, they are not the same.
Specialist Data Engineering at Merck, and Prabakaran Mathaiyan, Sr. MLEngineer at Tiger Analytics. The large machine learning (ML) model development lifecycle requires a scalable model release process similar to that of software development. The input to the training pipeline is the features dataset.
When machine learning (ML) models are deployed into production and employed to drive business decisions, the challenge often lies in the operation and management of multiple models. They swiftly began to work on AI/ML capabilities by building image recognition models using Amazon SageMaker.
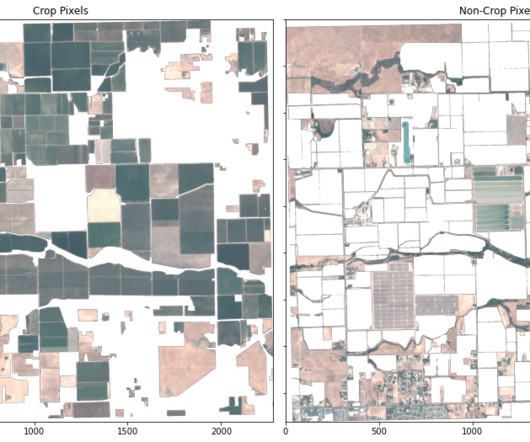
In this post, we illustrate how to use a segmentation machine learning (ML) model to identify crop and non-crop regions in an image. Identifying crop regions is a core step towards gaining agricultural insights, and the combination of rich geospatial data and ML can lead to insights that drive decisions and actions.
Amazon SageMaker Studio is a fully integrated development environment (IDE) for machine learning (ML) partly based on JupyterLab 3. Studio provides a web-based interface to interactively perform ML development tasks required to prepare data and build, train, and deploy ML models. cdk.json – Contains metadata, and feature flags.
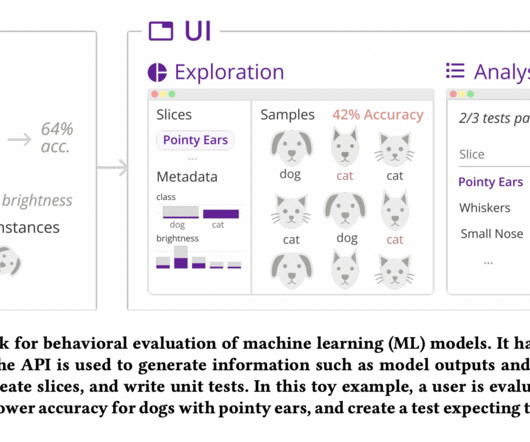
In the actual world, machine learning (ML) systems can embed issues like societal prejudices and safety worries. Stakeholders such as MLengineers, designers, and domain experts must work together to identify a model’s expected and potential faults. Zeno works together with other systems and combines the methods of others.
It is ideal for MLengineers, data scientists, and technical leaders, providing real-world training for production-ready generative AI using Amazon Bedrock and cloud-native services.
Learn about the flow, difficulties, and tools for performing ML clustering at scale Ori Nakar | Principal Engineer, Threat Research | Imperva Given that there are billions of daily botnet attacks from millions of different IPs, the most difficult challenge of botnet detection is choosing the most relevant data.
Came to ML from software. Founded neptune.ai , a modular MLOps component for MLmetadata store , aka “experiment tracker + model registry”. Most of our customers are doing ML/MLOps at a reasonable scale, NOT at the hyperscale of big-tech FAANG companies. A special type of software with ML in it but software nonetheless.
Luckily, we have tried and trusted tools and architectural patterns that provide a blueprint for reliable ML systems. In this article, I’ll introduce you to a unified architecture for ML systems built around the idea of FTI pipelines and a feature store as the central component. But what is an ML pipeline?
Statistical methods and machine learning (ML) methods are actively developed and adopted to maximize the LTV. In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.
Next, we present the solution architecture and process flows for machine learning (ML) model building, deployment, and inferencing. Here, Amazon SageMaker Ground Truth allowed MLengineers to easily build the human-in-the-loop workflow (step v). We end with lessons learned.
Amazon SageMaker provides purpose-built tools for machine learning operations (MLOps) to help automate and standardize processes across the ML lifecycle. In this post, we describe how Philips partnered with AWS to develop AI ToolSuite—a scalable, secure, and compliant ML platform on SageMaker.
Fine-tuning an LLM can be a complex workflow for data scientists and machine learning (ML) engineers to operationalize. Solution overview Running hundreds of experiments, comparing the results, and keeping a track of the ML lifecycle can become very complex. Each iteration can be considered a run within an experiment.
Machine learning (ML) models do not operate in isolation. To deliver value, they must integrate into existing production systems and infrastructure, which necessitates considering the entire ML lifecycle during design and development. GitHub serves as a centralized location to store, version, and manage your ML code base.
When working on real-world ML projects , you come face-to-face with a series of obstacles. The ml model reproducibility problem is one of them. This is indeed an erroneous thing to do when working on ML projects at scale. Reproducibility is the key factor when it comes to stabilizing the outcomes of any ML pipeline.
As Artificial Intelligence (AI) and Machine Learning (ML) technologies have become mainstream, many enterprises have been successful in building critical business applications powered by ML models at scale in production. They provide a fact sheet of the model that is important for model governance.
ML operationalization summary As defined in the post MLOps foundation roadmap for enterprises with Amazon SageMaker , ML and operations (MLOps) is the combination of people, processes, and technology to productionize machine learning (ML) solutions efficiently.
In 2018, I joined Cruise and cofounded the ML Infrastructure team there. We built many critical platform systems that enabled the ML teams to develop and ship models much faster, which contributed to the commercial launch of robotaxis in San Francisco in 2022. This required large end-to-end pipelines.
As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and MLengineers to build and deploy models at scale. In this comprehensive guide, we’ll explore everything you need to know about machine learning platforms, including: Components that make up an ML platform.
This is often referred to as platform engineering and can be neatly summarized by the mantra “You (the developer) build and test, and we (the platform engineering team) do all the rest!” Amazon Bedrock is compatible with robust observability features to monitor and manage ML models and applications.
Additionally, VitechIQ includes metadata from the vector database (for example, document URLs) in the model’s output, providing users with source attribution and enhancing trust in the generated answers. Prompt engineering Prompt engineering is crucial for the knowledge retrieval system.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content