This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
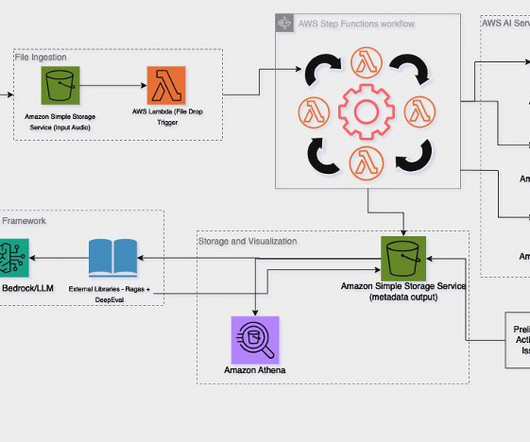
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Video data analysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.
Introduction to LAION-DISCO-12M To address this gap, LAION AI has released LAION-DISCO-12M—a collection of 12 million links to publicly available YouTube samples, paired with metadata designed to support foundational machine learning research in audio and music. Don’t Forget to join our 55k+ ML SubReddit.
This post is part of an ongoing series about governing the machine learning (ML) lifecycle at scale. The data mesh architecture aims to increase the return on investments in data teams, processes, and technology, ultimately driving business value through innovative analytics and ML projects across the enterprise.
By using Amazon Q Business, which simplifies the complexity of developing and managing ML infrastructure and models, the team rapidly deployed their chat solution. For the metadata file used in this example, we focus on boosting two key metadata attributes: _document_title and services.
However, with the help of AI and machine learning (ML), new software tools are now available to unearth the value of unstructured data. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data. But in the case of unstructured data, metadata discovery is challenging because the raw data isn’t easily readable.
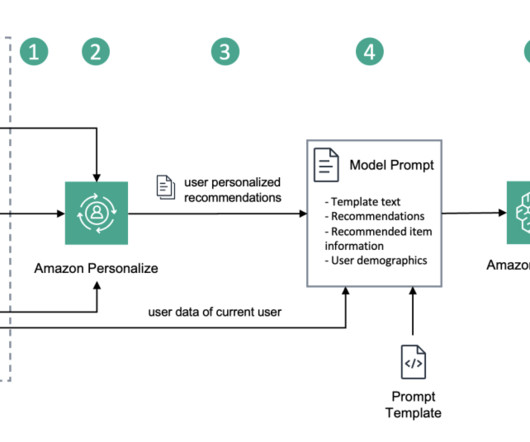
You can get started without any prior machine learning (ML) experience, and Amazon Personalize allows you to use APIs to build sophisticated personalization capabilities. For this example, we use the ml-latest-small dataset from the MovieLens dataset to simulate user-item interactions.
With metadata filtering now available in Knowledge Bases for Amazon Bedrock, you can define and use metadata fields to filter the source data used for retrieving relevant context during RAG. Metadata filtering gives you more control over the RAG process for better results tailored to your specific use case needs.
When building machine learning (ML) models using preexisting datasets, experts in the field must first familiarize themselves with the data, decipher its structure, and determine which subset to use as features. So much so that a basic barrier, the great range of data formats, is slowing advancement in ML.
This enables the efficient processing of content, including scientific formulas and data visualizations, and the population of Amazon Bedrock Knowledge Bases with appropriate metadata. JupyterLab applications flexible and extensive interface can be used to configure and arrange machine learning (ML) workflows.
As a global leader in agriculture, Syngenta has led the charge in using data science and machine learning (ML) to elevate customer experiences with an unwavering commitment to innovation. Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB.
FMI’s container-based approach aids in replicating simulations but requires metadata for broader reproducibility and adaptation. MaRDIFlow’s design principle revolves around treating components as abstract objects defined by their input-output behavior and metadata. If you like our work, you will love our newsletter.
Ensure Data Quality and Governance Establish data lineage, metadata management, and automated quality checks Leverage AI-powered data catalogs for better discoverability and classification Simplify data management to ensure seamless governance of structured and unstructured data , machine learning (ML) models, notebooks, dashboards, and files A good (..)
Unlike previous frameworks that require predefined tool configurations, OctoTools introduces tool cards, which encapsulate tool functionalities and metadata. The planner first analyzes the user query and determines the appropriate tools based on metadata associated with each tool card. Check out the Paper and GitHub Page.
These datasets encompass millions of hours of music, over 10 million recordings and compositions accompanied by comprehensive metadata, including key, tempo, instrumentation, keywords, moods, energies, chords, and more, facilitating training and commercial usage. GCX provides datasets with over 4.4
The development of machine learning (ML) models for scientific applications has long been hindered by the lack of suitable datasets that capture the complexity and diversity of physical systems. The data is available with a PyTorch interface, allowing for seamless integration into existing ML pipelines.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services.
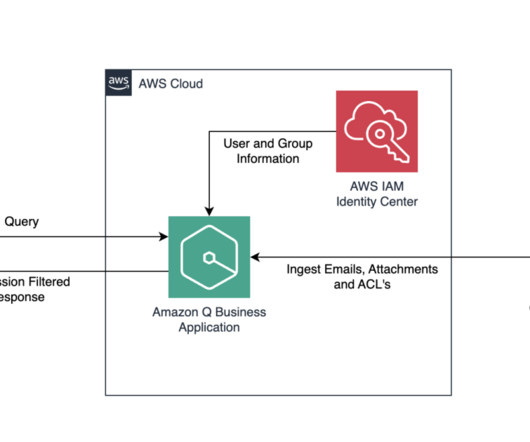
When you initiate a sync, Amazon Q will crawl the data source to extract relevant documents, then sync them to the Amazon Q index, making them searchable After syncing data sources, you can configure the metadata controls in Amazon Q Business. Joseph Mart is an AI/ML Specialist Solutions Architect at Amazon Web Services (AWS).
AI/ML and generative AI: Computer vision and intelligent insights As drones capture video footage, raw data is processed through AI-powered models running on Amazon Elastic Compute Cloud (Amazon EC2) instances. It even aids in synthetic training data generation, refining our ML models for improved accuracy.
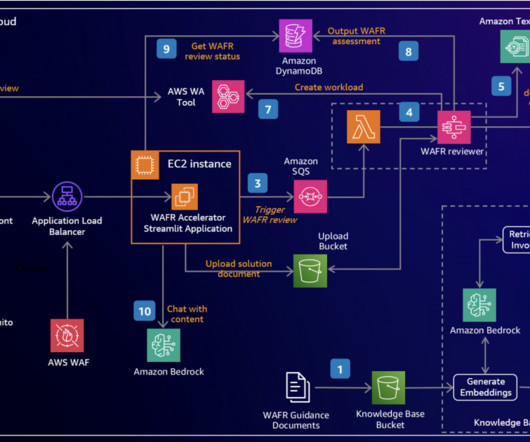
Amazon Bedrock offers fine-tuning capabilities that allow you to customize these pre-trained models using proprietary call transcript data, facilitating high accuracy and relevance without the need for extensive machine learning (ML) expertise. Architecture The following diagram illustrates the solution architecture.
Solution overview By combining the powerful vector search capabilities of OpenSearch Service with the access control features provided by Amazon Cognito , this solution enables organizations to manage access controls based on custom user attributes and document metadata. If you don’t already have an AWS account, you can create one.
Machine learning (ML) has become a critical component of many organizations’ digital transformation strategy. From predicting customer behavior to optimizing business processes, ML algorithms are increasingly being used to make decisions that impact business outcomes.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. Recent developments in generative AI models have further sped up the need of ML adoption across industries.
Real-world applications vary in inference requirements for their artificial intelligence and machine learning (AI/ML) solutions to optimize performance and reduce costs. SageMaker Model Monitor monitors the quality of SageMaker ML models in production. Your client applications invoke this endpoint to get inferences from the model.
For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security. The role information is also used to configure metadata filtering in the knowledge bases to generate relevant responses.
However, while many cyber vendors claim to bring AI to the fight, machine learning (ML) – a less sophisticated form of AI – remains a core part of their products. ML is unfit for the task. The distinction between ML and DL-based solutions becomes evident when examining their ability to identify and prevent known and unknown threats.
Metadata filtering is used to improve retrieval accuracy. Brijesh specializes in AI/ML solutions and has experience with serverless architectures. Using the extracted document content and retrieved embeddings, the WAFR reviewer generates an assessment using Amazon Bedrock.
This archive includes over 24 million image-text pairs from 6 million articles enriched with metadata and expert annotations. Articles and media files are downloaded from the NCBI server, extracting metadata, captions, and figure references from nXML files and the Entrez API. Dont Forget to join our 65k+ ML SubReddit.
This approach has two primary shortcomings: Missed Contextual Signals : Without considering metadata such as source URLs, LMs overlook important contextual information that could guide their understanding of a texts intent or quality. MeCo leverages readily available metadata, such as source URLs, during the pre-training phase.
Typically, on their own, data warehouses can be restricted by high storage costs that limit AI and ML model collaboration and deployments, while data lakes can result in low-performing data science workloads. Also, a lakehouse can introduce definitional metadata to ensure clarity and consistency, which enables more trustworthy, governed data.
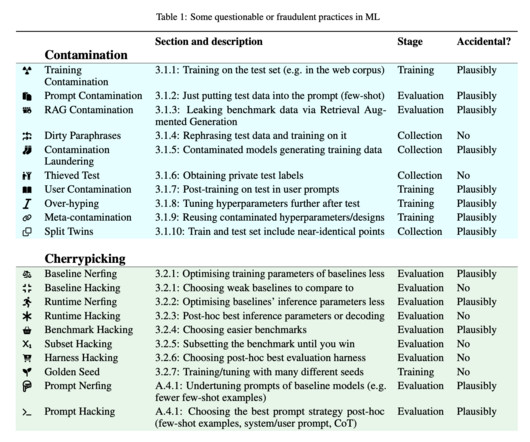
These methods have the potential to greatly exaggerate published results, deceiving the scientific community and the general public about the actual effectiveness of ML models. Due to the intricacy of ML research, which includes pre-training, post-training, and evaluation stages, there is much potential for QRPs. Check out the Paper.
Additionally, for every retrieval result you bring, you can provide a name and additional metadata in the form of key-value pairs. His expertise is in reproducible and end-to-end AI/ML methods, practical implementations, and helping global customers formulate and develop scalable solutions to interdisciplinary problems. are optional.
It stores information such as job ID, status, creation time, and other metadata. The following is a screenshot of the DynamoDB table where you can track the job status and other types of metadata related to the job. With a strong background in AI/ML, Ishan specializes in building Generative AI solutions that drive business value.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
Building ML infrastructure and integrating ML models with the larger business are major bottlenecks to AI adoption [1,2,3]. IBM Db2 can help solve these problems with its built-in ML infrastructure. Db2 Warehouse on cloud also supports these ML features.
It often requires managing multiple machine learning (ML) models, designing complex workflows, and integrating diverse data sources into production-ready formats. Audio metadata extraction : Extraction of file properties such as format, duration, and bit rate is handled by either Amazon Transcribe Analytics or another call center solution.
Name a product and extract metadata to generate a tagline and description In the field of marketing and product development, coming up with a perfect product name and creative promotional content can be challenging. About the Authors Mithil Shah is a Principal AI/ML Solution Architect at Amazon Web Services. model on Amazon Bedrock.
Instead, organizations are increasingly looking to take advantage of transformative technologies like machine learning (ML) and artificial intelligence (AI) to deliver innovative products, improve outcomes, and gain operational efficiencies at scale. Data is presented to the personas that need access using a unified interface.
From Solo Notebooks to Collaborative Powerhouse: VS Code Extensions for Data Science and ML Teams Photo by Parabol | The Agile Meeting Toolbox on Unsplash In this article, we will explore the essential VS Code extensions that enhance productivity and collaboration for data scientists and machine learning (ML) engineers.
This post explores how Amazon SageMaker AI with MLflow can help you as a developer and a machine learning (ML) practitioner efficiently experiment, evaluate generative AI agent performance, and optimize their applications for production readiness.
Aggressive query filtering Overly strict search filters or metadata constraints might exclude relevant records. You should review the metadata filters or boosting settings applied in Amazon Q Business to make sure they dont unnecessarily restrict results. He is focusing on AI/ML and IoT. Julia Hu is a Sr.
In this post, we explore how to use Amazon Bedrock for synthetic data generation, considering these challenges alongside the potential benefits to develop effective strategies for various applications across multiple industries, including AI and machine learning (ML). Incorporate rare events and edge cases at appropriate frequencies.
Challenges in deploying advanced ML models in healthcare Rad AI, being an AI-first company, integrates machine learning (ML) models across various functions—from product development to customer success, from novel research to internal applications. Rad AI’s ML organization tackles this challenge on two fronts.
The connector supports the crawling of the following entities in Gmail: Email – Each email is considered a single document Attachment – Each email attachment is considered a single document Additionally, supported custom metadata and custom objects are also crawled during the sync process. Vineet Kachhawaha is a Sr.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content