This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
From Solo Notebooks to Collaborative Powerhouse: VS Code Extensions for Data Science and ML Teams Photo by Parabol | The Agile Meeting Toolbox on Unsplash In this article, we will explore the essential VS Code extensions that enhance productivity and collaboration for data scientists and machine learning (ML) engineers.
How to save a trained model in Python? In this section, you will see different ways of saving machine learning (ML) as well as deep learning (DL) models. The first way to save an ML model is by using the pickle file. Saving trained model with pickle The pickle module can be used to serialize and deserialize the Python objects.
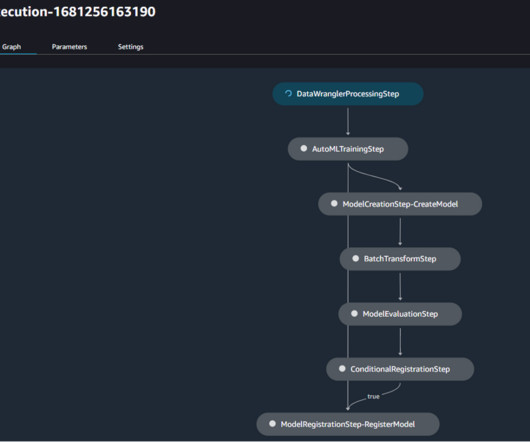
In this post, we show you how to convert Python code that fine-tunes a generative AI model in Amazon Bedrock from local files to a reusable workflow using Amazon SageMaker Pipelines decorators. You can use Amazon SageMaker Model Building Pipelines to collaborate between multiple AI/ML teams. We use Python to do this.
Create a SageMaker Model Monitor schedule Next, you use the Amazon SageMaker Python SDK to create a model monitoring schedule. You can use this framework as a starting point to monitor your custom metrics or handle other unique requirements for model quality monitoring in your AI/ML applications. About the Authors Joe King is a Sr.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Third, despite the larger adoption of centralized analytics solutions like data lakes and warehouses, complexity rises with different table names and other metadata that is required to create the SQL for the desired sources.
FMEval is an open source LLM evaluation library, designed to provide data scientists and machine learning (ML) engineers with a code-first experience to evaluate LLMs for various aspects, including accuracy, toxicity, fairness, robustness, and efficiency. This allows you to keep track of your ML experiments.
In this post, we introduce an example to help DevOps engineers manage the entire ML lifecycle—including training and inference—using the same toolkit. Solution overview We consider a use case in which an MLengineer configures a SageMaker model building pipeline using a Jupyter notebook.
In the ever-evolving landscape of machine learning, feature management has emerged as a key pain point for MLEngineers at Airbnb. Transforming Data with Flexibility With Chronon’s SQL-like transformations and time-based aggregations, ML practitioners have the freedom to process data with ease.
Introduction to LLMs in Python Difficulty Level: Intermediate This hands-on course teaches you to understand, build, and utilize Large Language Models (LLMs) for tasks like translation and question-answering. Students learn about key innovations, ethical challenges, and hands-on labs for generating text with Python.
Knowledge and skills in the organization Evaluate the level of expertise and experience of your ML team and choose a tool that matches their skill set and learning curve. For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc.,
Artificial intelligence (AI) and machine learning (ML) are becoming an integral part of systems and processes, enabling decisions in real time, thereby driving top and bottom-line improvements across organizations. However, putting an ML model into production at scale is challenging and requires a set of best practices.
Planet and AWS’s partnership on geospatial ML SageMaker geospatial capabilities empower data scientists and MLengineers to build, train, and deploy models using geospatial data. This example uses the Python client to identify and download imagery needed for the analysis.
This post guides you through the steps to get started with setting up and deploying Studio to standardize ML model development and collaboration with fellow MLengineers and ML scientists. All examples in the post are written in the Python programming language. cdk.json – Contains metadata, and feature flags.
We’ll see how this architecture applies to different classes of ML systems, discuss MLOps and testing aspects, and look at some example implementations. Understanding machine learning pipelines Machine learning (ML) pipelines are a key component of ML systems. But what is an ML pipeline?
The following is an extract from Andrew McMahon’s book , Machine Learning Engineering with Python, Second Edition. Secondly, to be a successful MLengineer in the real world, you cannot just understand the technology; you must understand the business. First of all, the ultimate goal of your work is to generate value.
Additionally, VitechIQ includes metadata from the vector database (for example, document URLs) in the model’s output, providing users with source attribution and enhancing trust in the generated answers. Prompt engineering Prompt engineering is crucial for the knowledge retrieval system. langsmith==0.0.43 pgvector==0.2.3
Fine-tuning an LLM can be a complex workflow for data scientists and machine learning (ML) engineers to operationalize. You can create workflows with SageMaker Pipelines that enable you to prepare data, fine-tune models, and evaluate model performance with simple Python code for each step.
Earth.com didn’t have an in-house MLengineering team, which made it hard to add new datasets featuring new species, release and improve new models, and scale their disjointed ML system. We initiated a series of enhancements to deliver managed MLOps platform and augment MLengineering.
. 🛠 ML Work Your most recent project is Sematic, which focuses on enabling Python-based orchestration of ML pipelines. At Cruise, we noticed a wide gap between the complexity of cloud infrastructure, and the needs of the ML workforce. Could you please tell us about the vision and inspiration behind this project?
ML operations, known as MLOps, focus on streamlining, automating, and monitoring ML models throughout their lifecycle. Data scientists, MLengineers, IT staff, and DevOps teams must work together to operationalize models from research to deployment and maintenance.
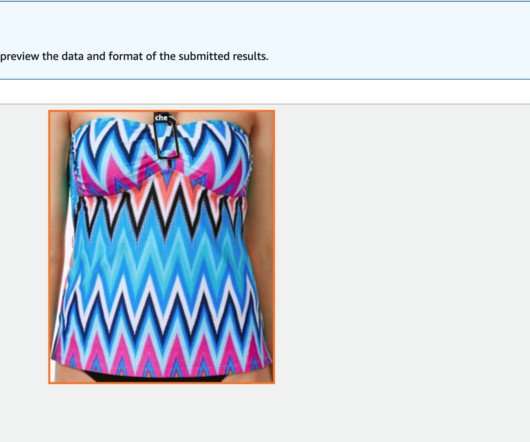
Solution overview Ground Truth is a fully self-served and managed data labeling service that empowers data scientists, machine learning (ML) engineers, and researchers to build high-quality datasets. For our example use case, we work with the Fashion200K dataset , released at ICCV 2017.
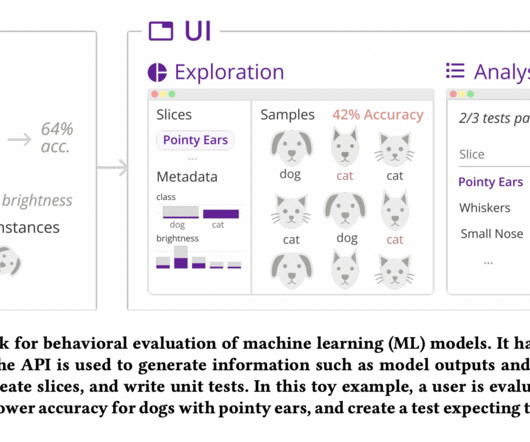
Stakeholders such as MLengineers, designers, and domain experts must work together to identify a model’s expected and potential faults. Instead, MLengineers collaborate with domain experts and designers to describe a model’s expected capabilities before it is iterated and deployed.
This post is co-written with Jad Chamoun, Director of Engineering at Forethought Technologies, Inc. and Salina Wu, Senior MLEngineer at Forethought Technologies, Inc. We defined logic that would take in model metadata, format the endpoint deterministically based on the metadata, and check whether the endpoint existed.
Solution overview The ML solution for LTV forecasting is composed of four components: the training dataset ETL pipeline, MLOps pipeline, inference dataset ETL pipeline, and ML batch inference. MLengineers no longer need to manage this training metadata separately.
PyMC and ArviZ are an excellent pairing of open-source Python libraries for modeling and visualizing Bayesian models. help data scientists systematically record, catalog, and analyze modeling artifacts and experiment metadata. PyMC is a powerful and well-maintained Python library that we can use for Bayesian inference.
MLflow is an open-source platform designed to manage the entire machine learning lifecycle, making it easier for MLEngineers, Data Scientists, Software Developers, and everyone involved in the process. Machine learning operations (MLOps) are a set of practices that automate and simplify machine learning (ML) workflows and deployments.
It also integrates with Machine Learning and Operation (MLOps) workflows in Amazon SageMaker to automate and scale the ML lifecycle. Here you can provide the metadata for this model hosting information along with the input format/template your specific model expects. What is FMEval? How can you get started?
This is your Custom Python Hook speaking!" A session stores metadata and application-specific data known as session attributes. Ryan Gomes is a Data & MLEngineer with the AWS Professional Services Intelligence Practice. A session persists over time unless manually stopped or timed out.
By directly integrating with Amazon Managed Service for Prometheus and Amazon Managed Grafana and abstracting the management of hardware failures and job resumption, SageMaker HyperPod allows data scientists and MLengineers to focus on model development rather than infrastructure management.
Cost and resource requirements There are several cost-related constraints we had to consider when we ventured into the ML model deployment journey Data storage costs: Storing the data used to train and test the model, as well as any new data used for prediction, can add to the cost of deployment. S3 buckets. Redshift, S3, and so on.
This is Piotr Niedźwiedź and Aurimas Griciūnas from neptune.ai , and you’re listening to ML Platform Podcast. Stefan is a software engineer, data scientist, and has been doing work as an MLengineer. You could almost think of Hamilton as DBT for Python functions. Piotr: This is procedural Python code.
How did you manage to jump from a more analytical, scientific type of role to a more engineering one? I actually did not pick up Python until about a year before I made the transition to a data scientist role. I see so many of these job seekers, especially on the MLOps side or the MLengineer side. It’s two things.
One of the most prevalent complaints we hear from MLengineers in the community is how costly and error-prone it is to manually go through the ML workflow of building and deploying models. Building end-to-end machine learning pipelines lets MLengineers build once, rerun, and reuse many times.
You can integrate a Data Wrangler data preparation flow into your ML workflows to simplify and streamline data preprocessing and feature engineering using little to no coding. You can also add your own Python scripts and transformations to customize workflows. Python code file. Choose the file browser icon view the path.
You can use the new inference capabilities from Amazon SageMaker Studio , the SageMaker Python SDK , AWS SDKs , and AWS Command Line Interface (AWS CLI). They are also supported by AWS CloudFormation. Now you also can use them with SageMaker Operators for Kubernetes. Refer to the guidance provided in the API documentation for more details.
As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and MLengineers to build and deploy models at scale. In this comprehensive guide, we’ll explore everything you need to know about machine learning platforms, including: Components that make up an ML platform.
Data scientists collaborate with MLengineers to transition code from notebooks to repositories, creating ML pipelines using Amazon SageMaker Pipelines, which connect various processing steps and tasks, including pre-processing, training, evaluation, and post-processing, all while continually incorporating new production data.
You can now register machine learning (ML) models in Amazon SageMaker Model Registry with Amazon SageMaker Model Cards , making it straightforward to manage governance information for specific model versions directly in SageMaker Model Registry in just a few clicks. It’s mapped to the custom_details field.
Role of metadata while indexing data in vector databases Metadata plays a crucial role when loading documents into a vector data store in Amazon Bedrock. Content categorization – Metadata can provide information about the content or category of a document, such as the subject matter, domain, or topic.
To make the most out of this interactive session, participants should ensure theyhave: A Linux or Mac-based Developers Laptop Windows Users should use a VM or CloudInstance Python Installed: version 3.10 . """ txt_files = glob.glob(os.path.join(folder_path, "*.txt")) See youthere!
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content