This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
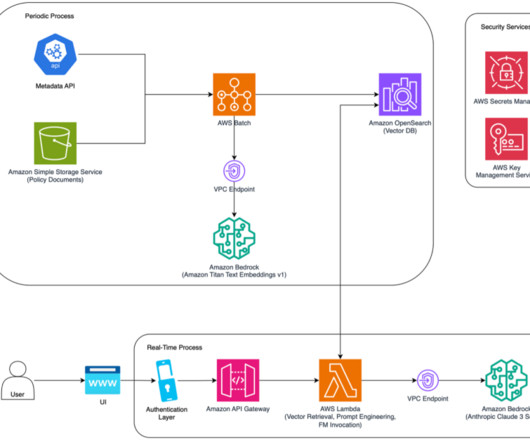
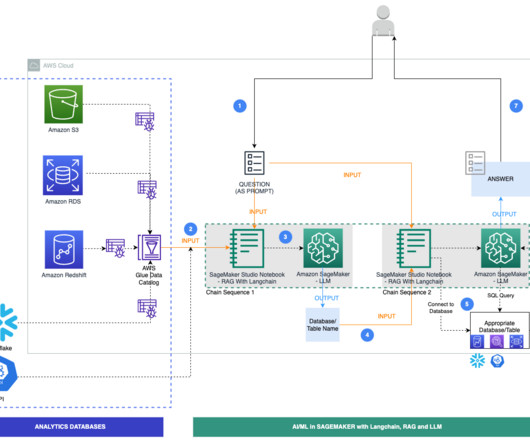
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
The solution proposed in this post relies on LLMs context learning capabilities and promptengineering. It enables you to use an off-the-shelf model as is without involving machinelearning operations (MLOps) activity. The request is sent to the prompt generator.
Along with each document slice, we store the metadata associated with it using an internal Metadata API, which provides document characteristics like document type, jurisdiction, version number, and effective dates. Prompt optimization The change summary is different than showing differences in text between the two documents.
If it was a 4xx error, its written in the metadata of the Job. PromptengineeringPromptengineering involves the skillful crafting and refining of input prompts. Essentially, promptengineering is about effectively interacting with an LLM.
It demands substantial effort in data preparation, coupled with a difficult optimization procedure, necessitating a certain level of machinelearning expertise. But the drawback for this is its reliance on the skill and expertise of the user in promptengineering. However, this process isn't without its challenges.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
SageMaker JumpStart is a machinelearning (ML) hub that provides a wide range of publicly available and proprietary FMs from providers such as AI21 Labs, Cohere, Hugging Face, Meta, and Stability AI, which you can deploy to SageMaker endpoints in your own AWS account. It’s serverless so you don’t have to manage the infrastructure.
Machinelearning (ML) engineers must make trade-offs and prioritize the most important factors for their specific use case and business requirements. You can use metadata filtering to narrow down search results by specifying inclusion and exclusion criteria.
By documenting the specific model versions, fine-tuning parameters, and promptengineering techniques employed, teams can better understand the factors contributing to their AI systems performance. He holds a PhD in Telecommunications Engineering and has experience in software engineering.
Introduction PromptEngineering is arguably the most critical aspect in harnessing the power of Large Language Models (LLMs) like ChatGPT. However; current promptengineering workflows are incredibly tedious and cumbersome. Logging prompts and their outputs to .csv First install the package via pip.
This article lists the top AI courses by Google that provide comprehensive training on various AI and machinelearning technologies, equipping learners with the skills needed to excel in the rapidly evolving field of AI. Participants learn how to improve model accuracy and write scalable, specialized ML models.
makes it easy for RAG developers to track evaluation metrics and metadata, enabling them to analyze and compare different system configurations. Further, LangChain offers features for promptengineering, like templates and example selectors. The framework also contains a collection of tools that can be called by LLM agents.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machinelearning (ML) and new generative AI capabilities powered by foundation models. Automated development: Automates data preparation, model development, feature engineering and hyperparameter optimization using AutoAI.
One such component is a feature store, a tool that stores, shares, and manages features for machinelearning (ML) models. Another essential component is an orchestration tool suitable for promptengineering and managing different type of subtasks. A media metadata store keeps the promotion movie list up to date.
Evaluating a RAG solution Contrary to traditional machinelearning (ML) models, for which evaluation metrics are well defined and straightforward to compute, evaluating a RAG framework is still an open problem. Try metadata filtering in your OpenSearch index. Try using query rewriting to get the right metadata filtering.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machinelearning (ML) services to run their daily workloads. Refine your existing application using strategic methods such as promptengineering , optimizing inference parameters and other LookML content.
Used alongside other techniques such as promptengineering, RAG, and contextual grounding checks, Automated Reasoning checks add a more rigorous and verifiable approach to enhancing the accuracy of LLM-generated outputs.
Although these traditional machinelearning (ML) approaches might perform decently in terms of accuracy, there are several significant advantages to adopting generative AI approaches. Operational efficiency Uses promptengineering, reducing the need for extensive fine-tuning when new categories are introduced.
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. Pay-as-you-go pricing makes it easy to scale when needed.
The embedding representations of text chunks along with related metadata are indexed in OpenSearch Service. Text embedding models are machinelearning (ML) models that map words or phrases from text to dense vector representations. The application uses Amazon Textract to get the text and tables from the input documents.
SageMaker JumpStart is a machinelearning (ML) hub with foundation models (FMs), built-in algorithms, and prebuilt ML solutions that you can deploy with just a few clicks. This post walks through examples of building information extraction use cases by combining LLMs with promptengineering and frameworks such as LangChain.
For this purpose, we use Amazon Textract, a machinelearning (ML) service for entity recognition and extraction. We use promptengineering to send our summarization instructions to the LLM. Data Scientist with 8+ years of experience in Data Science and MachineLearning.
For several years, we have been actively using machinelearning and artificial intelligence (AI) to improve our digital publishing workflow and to deliver a relevant and personalized experience to our readers. We use a single-shot prompt with the full article text in context to generate the summary.
Experts can check hard drives, metadata, data packets, network access logs or email exchanges to find, collect, and process information. They can use machinelearning (ML), natural language processing (NLP) and generative models for pattern recognition, predictive analysis, information seeking, or collaborative brainstorming.
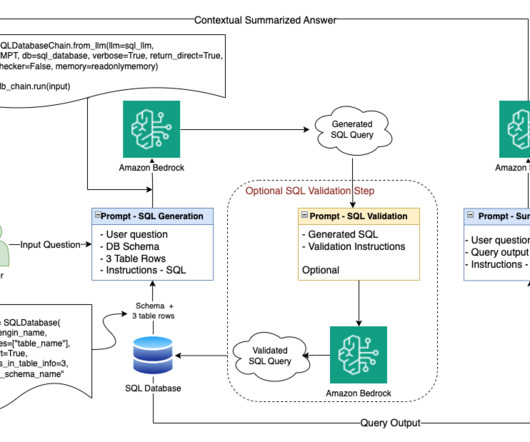
This would have required a dedicated cross-disciplinary team with expertise in data science, machinelearning, and domain knowledge. Given the right context, metadata, and instructions, a well-selected general purpose LLM can produce good-quality SQL as long as it has access to the right domain-specific context.
The workflow for NLQ consists of the following steps: A Lambda function writes schema JSON and table metadata CSV to an S3 bucket. The wrapper function reads the table metadata from the S3 bucket. The wrapper function creates a dynamic prompt template and gets relevant tables using Amazon Bedrock and LangChain.
Additionally, VitechIQ includes metadata from the vector database (for example, document URLs) in the model’s output, providing users with source attribution and enhancing trust in the generated answers. PromptengineeringPromptengineering is crucial for the knowledge retrieval system.
An AWS Glue crawler is scheduled to run at frequent intervals to extract metadata from databases and create table definitions in the AWS Glue Data Catalog. LangChain, a tool to work with LLMs and prompts, is used in Studio notebooks. However, these databases must have their metadata registered with the AWS Glue Data Catalog.
You can customize the model using promptengineering, Retrieval Augmented Generation (RAG), or fine-tuning. Fine-tuning an LLM can be a complex workflow for data scientists and machinelearning (ML) engineers to operationalize. Each iteration can be considered a run within an experiment.
Specifically, Vidmob analyzes the client ad campaigns and extracts information related to the ads using various machinelearning (ML) models and AWS services. The chatbot built by AWS GenAIIC would take in this tag data and retrieve insights. Dataset The dataset includes a set of ad-related data corresponding to a specific client.
Amazon Textract is a machinelearning (ML) service that automatically extracts text, handwriting, and data from scanned documents. For example, we can follow promptengineering best practices to fine-tune an LLM to format dates into MM/DD/YYYY format, which may be compatible with a database DATE column.
Additionally, evaluation can identify potential biases, hallucinations, inconsistencies, or factual errors that may arise from the integration of external sources or from sub-optimal promptengineering. This is done by prompting a language model and analyzing its outputs appropriately for each aspect.
The recent strides made in the field of machinelearning have given us an array of powerful language models and algorithms. In this blog post we will discuss the importance of LLMOps principles and best practices, which will enable you to take your existing or new machinelearning projects to the next level.
As promptengineering is fundamentally different from training machinelearning models, Comet has released a new SDK tailored for this use case comet-llm. In this article you will learn how to log the YOLOPandas prompts with comet-llm, keep track of the number of tokens used in USD($), and log your metadata.
Of course, all of the things that control vector does can be done through promptengineering as well as one can consider control vector to be an “addition” to the prompt that is provided by the user. This is where metadata comes in. Metadata is essentially data about data.
AWS delivers services that meet customers’ artificial intelligence (AI) and machinelearning (ML) needs with services ranging from custom hardware like AWS Trainium and AWS Inferentia to generative AI foundation models (FMs) on Amazon Bedrock. He primarily focuses on applications of artificial intelligence and machinelearning.
We provide a list of reviews as context and create a prompt to generate an output with a concise summary, overall sentiment, confidence score of the sentiment, and action items from the input reviews. Our example prompt requests the FM to generate the response in JSON format.
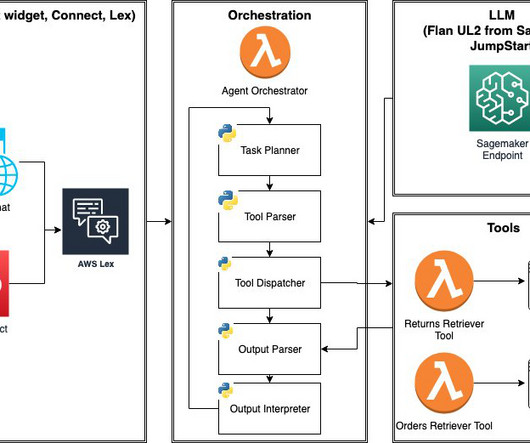
Often, these LLMs require some metadata about available tools (descriptions, yaml, or JSON schema for their input parameters) in order to output tool invocations. We use promptengineering only and Flan-UL2 model as-is without fine-tuning. You have access to the following tools.
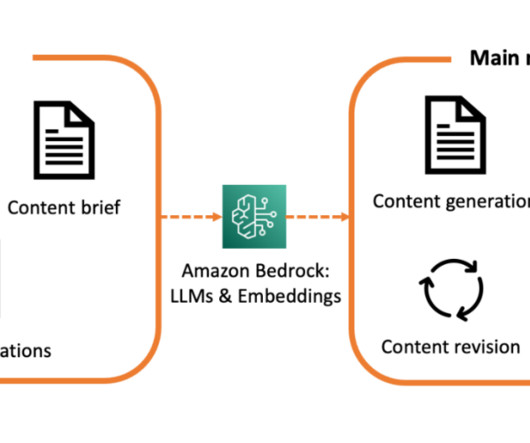
This includes sales collateral, customer engagements, external web data, machinelearning (ML) insights, and more. Our development process revolved around crafting and fine-tuning prompts that would generate accurate, relevant, and actionable insights.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machinelearning (ML) models. Text to SQL: Using natural language to enhance query authoring SQL is a complex language that requires an understanding of databases, tables, syntaxes, and metadata.
Be sure to check out his talk, “ Prompt Optimization with GPT-4 and Langchain ,” there! The difference between the average person using AI and a PromptEngineer is testing. Most people run a prompt 2–3 times and find something that works well enough.
Comet’s LLMOps tool provides an intuitive and responsive view of our prompt history. Prompt Playground: With the LLMOps tool comes the new Prompt Playground, which allows PromptEngineers to iterate quickly with different Prompt Templates and understand the impact on different contexts.
You’ll learn about the critical factors to consider when evaluating AI-assisted development tools, focusing on compliance and future product roadmaps. You’ll also be introduced to promptengineering, a crucial skill for optimizing AI interactions. You’ll also discuss loading processed data into destination storage.
In this article, we will delve deeper into these issues, exploring the advanced techniques of promptengineering with Langchain, offering clear explanations, practical examples, and step-by-step instructions on how to implement them. Prompts play a crucial role in steering the behavior of a model.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content