This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One effective way to improve context relevance is through metadata filtering, which allows you to refine search results by pre-filtering the vector store based on custom metadata attributes. By combining the capabilities of LLM function calling and Pydantic data models, you can dynamically extract metadata from user queries.
The machinelearning community faces a significant challenge in audio and music applications: the lack of a diverse, open, and large-scale dataset that researchers can freely access for developing foundation models.
Amazon Bedrock Knowledge Bases has a metadata filtering capability that allows you to refine search results based on specific attributes of the documents, improving retrieval accuracy and the relevance of responses. These metadata filters can be used in combination with the typical semantic (or hybrid) similarity search.
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Video data analysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.
Machinelearning (ML) has become a critical component of many organizations’ digital transformation strategy. In this blog post, we will explore the importance of lineage transparency for machinelearning data sets and how it can help establish and ensure, trust and reliability in ML conclusions.
The development of machinelearning (ML) models for scientific applications has long been hindered by the lack of suitable datasets that capture the complexity and diversity of physical systems. Each dataset includes metadata and training/testing splits, enabling easy benchmarking of different machine-learning models.
One of these strategies is using Amazon Simple Storage Service (Amazon S3) folder structures and Amazon Bedrock Knowledge Bases metadata filtering to enable efficient data segmentation within a single knowledge base. The S3 bucket, containing customer data and metadata, is configured as a knowledge base data source.
When building machinelearning (ML) models using preexisting datasets, experts in the field must first familiarize themselves with the data, decipher its structure, and determine which subset to use as features. This obstacle lowers productivity through machinelearning development—from data discovery to model training.
This enables the efficient processing of content, including scientific formulas and data visualizations, and the population of Amazon Bedrock Knowledge Bases with appropriate metadata. JupyterLab applications flexible and extensive interface can be used to configure and arrange machinelearning (ML) workflows.
Amazon Comprehend provides real-time APIs, such as DetectPiiEntities and DetectEntities , which use natural language processing (NLP) machinelearning (ML) models to identify text portions for redaction. For the metadata file used in this example, we focus on boosting two key metadata attributes: _document_title and services.
However, information about one dataset can be in another dataset, called metadata. Without using metadata, your retrieval process can cause the retrieval of unrelated results, thereby decreasing FM accuracy and increasing cost in the FM prompt token. This change allows you to use metadata fields during the retrieval process.
This article will focus on LLM capabilities to extract meaningful metadata from product reviews, specifically using OpenAI API. Data processing Since our main area of interest is extracting metadata from reviews, we had to choose a subset of reviews and label it manually with selected fields of interest.
To refine the search results, you can filter based on document metadata to improve retrieval accuracy, which in turn leads to more relevant FM generations aligned with your interests. With this feature, you can now supply a custom metadata file (each up to 10 KB) for each document in the knowledge base. Virginia) and US West (Oregon).
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services.
I have written short summaries of 68 different research papers published in the areas of MachineLearning and Natural Language Processing. Additive embeddings are used for representing metadata about each note. They cover a wide range of different topics, authors and venues. University of Wisconsin-Madison.
Any type of contextual information, like device context, conversational context, and metadata, […]. However, we can improve the system’s accuracy by leveraging contextual information. The post Underlying Engineering Behind Alexa’s Contextual ASR appeared first on Analytics Vidhya.
With metadata filtering now available in Knowledge Bases for Amazon Bedrock, you can define and use metadata fields to filter the source data used for retrieving relevant context during RAG. Metadata filtering gives you more control over the RAG process for better results tailored to your specific use case needs.
When you initiate a sync, Amazon Q will crawl the data source to extract relevant documents, then sync them to the Amazon Q index, making them searchable After syncing data sources, you can configure the metadata controls in Amazon Q Business. His core competence and interests lie in machinelearning applications and generative AI.
Rightsify’ s Global Copyright Exchange (GCX) offers vast collections of copyright-cleared music datasets tailored for machinelearning and generative AI music initiatives. Music Recommendation: Music recommendation systems heavily rely on music datasets that contain detailed metadata. GCX provides datasets with over 4.4
Solution overview By combining the powerful vector search capabilities of OpenSearch Service with the access control features provided by Amazon Cognito , this solution enables organizations to manage access controls based on custom user attributes and document metadata. If you don’t already have an AWS account, you can create one.
In recent years, research on tabular machinelearning has grown rapidly. Most available datasets either lack the temporal metadata necessary for time-based splits or come from less extensive data acquisition and feature engineering pipelines compared to common industry ML practices.
Ingest documents in Amazon Q Business To create an Amazon Q Business application, retriever, and index to pull data in real time during a conversation, follow the steps under the Create and configure your Amazon Q application section in the AWS MachineLearning Blog post, Discover insights from Amazon S3 with Amazon Q S3 connector.
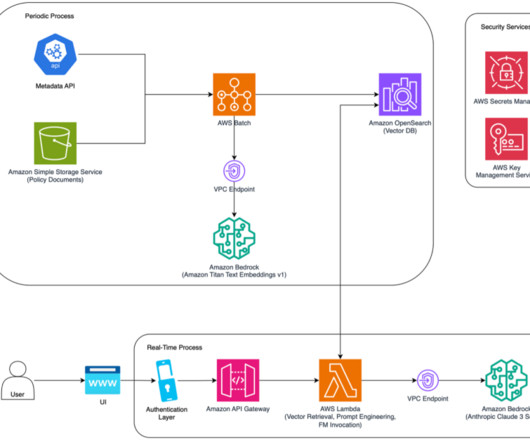
Along with each document slice, we store the metadata associated with it using an internal Metadata API, which provides document characteristics like document type, jurisdiction, version number, and effective dates. This process has been implemented as a periodic job to keep the vector database updated with new documents.
Amazon Bedrock offers fine-tuning capabilities that allow you to customize these pre-trained models using proprietary call transcript data, facilitating high accuracy and relevance without the need for extensive machinelearning (ML) expertise. Architecture The following diagram illustrates the solution architecture.
One of the major focuses over the years of AutoML is the hyperparameter search problem, where the model implements an array of optimization methods to determine the best performing hyperparameters in a large hyperparameter space for a particular machinelearning model. ai, IBM Watson AI, Microsoft AzureML, and a lot more.
AI models trained with a mix of clinical trial metadata, medical and pharmacy claims data, and patient data from membership (primary care) services can also help identify clinical trial sites that will provide access to diverse, relevant patient populations.
Amazon SageMaker AI is at the core of our machinelearning (ML) pipeline, training and deploying models for object detection, anomaly detection, and predictive maintenance. Meanwhile, structured metadata and processed results are housed in Amazon RDS, enabling fast queries and integration with enterprise applications.
Unlike previous frameworks that require predefined tool configurations, OctoTools introduces tool cards, which encapsulate tool functionalities and metadata. The planner first analyzes the user query and determines the appropriate tools based on metadata associated with each tool card.
Also, a lakehouse can introduce definitional metadata to ensure clarity and consistency, which enables more trustworthy, governed data. And AI, both supervised and unsupervised machinelearning, is often the best or sometimes only way to unlock these new big data insights at scale. All of this supports the use of AI.
They are crucial for machinelearning applications, particularly those involving natural language processing and image recognition. Often support for metadata filtering alongside vector search Popular vector databases include FAISS (Facebook AI Similarity Search), Pinecone, Weaviate, Milvus, and Chroma.
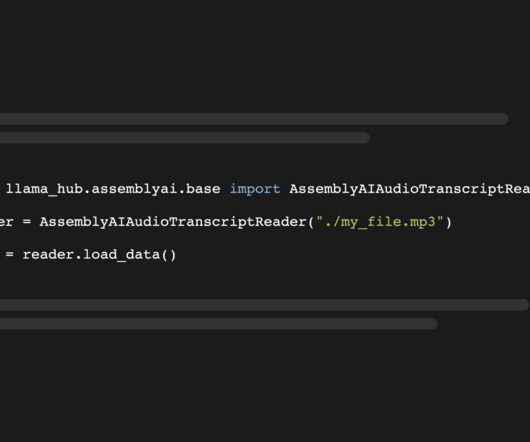
The metadata contains the full JSON response of our API with more meta information: print(docs[0].metadata) The metadata needs to be smaller than the text chunk size, and since it contains the full JSON response with extra information, it is quite large. You can read more about the integration in the official Llama Hub docs.
It often requires managing multiple machinelearning (ML) models, designing complex workflows, and integrating diverse data sources into production-ready formats. He leads machinelearning initiatives and projects across business domains, leveraging multimodal AI, generative models, computer vision, and natural language processing.
Evaluating model performance is essential in the significantly advancing fields of Artificial Intelligence and MachineLearning, especially with the introduction of Large Language Models (LLMs). This review procedure helps understand these models’ capabilities and create dependable systems based on them.
After some impressive advances over the past decade, largely thanks to the techniques of MachineLearning (ML) and Deep Learning , the technology seems to have taken a sudden leap forward. 1] Users can access data through a single point of entry, with a shared metadata layer across clouds and on-premises environments.
Can you discuss the advantages of deep learning over traditional machinelearning in threat prevention? However, while many cyber vendors claim to bring AI to the fight, machinelearning (ML) – a less sophisticated form of AI – remains a core part of their products. That process is part of our secret sauce.
The solution proposed in this post relies on LLMs context learning capabilities and prompt engineering. It enables you to use an off-the-shelf model as is without involving machinelearning operations (MLOps) activity. When using the FAISS adapter, translation units are stored into a local FAISS index along with the metadata.
You can also supply a custom metadata file (each up to 10 KB) for each document in the knowledge base. You can apply filters to your retrievals, instructing the vector store to pre-filter based on document metadata and then search for relevant documents. Reranking allows GraphRAG to refine and optimize search results.
For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security. The role information is also used to configure metadata filtering in the knowledge bases to generate relevant responses.
However, traditional machinelearning approaches often require extensive data-specific tuning and model customization, resulting in lengthy and resource-heavy development. It stores models, organizes model versions, captures essential metadata and artifacts such as container images, and governs the approval status of each model.
Name a product and extract metadata to generate a tagline and description In the field of marketing and product development, coming up with a perfect product name and creative promotional content can be challenging. You can also ask the model to combine its knowledge with the knowledge from the graph. model on Amazon Bedrock.
This capability enables organizations to create custom inference profiles for Bedrock base foundation models, adding metadata specific to tenants, thereby streamlining resource allocation and cost monitoring across varied AI applications. Dhawal Patel is a Principal MachineLearning Architect at AWS.
This post is part of an ongoing series about governing the machinelearning (ML) lifecycle at scale. Data engineers contribute to the data lineage process by providing the necessary information and metadata about the data transformations they perform. To view this series from the beginning, start with Part 1.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content