This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Design patterns are reusable solutions to common problems in software design. For AI and large language model (LLM) engineers , design patterns help build robust, scalable, and maintainable systems that handle complex workflows efficiently. I'll explain each pattern with practical AI use cases and Python code examples.
Evaluating large language models (LLMs) is crucial as LLM-based systems become increasingly powerful and relevant in our society. Rigorous testing allows us to understand an LLMs capabilities, limitations, and potential biases, and provide actionable feedback to identify and mitigate risk.
Through advanced analytics, software, research, and industry expertise across more than 20 countries, Verisk helps build resilience for individuals, communities, and businesses. The company is committed to ethical and responsibleAI development with human oversight and transparency.
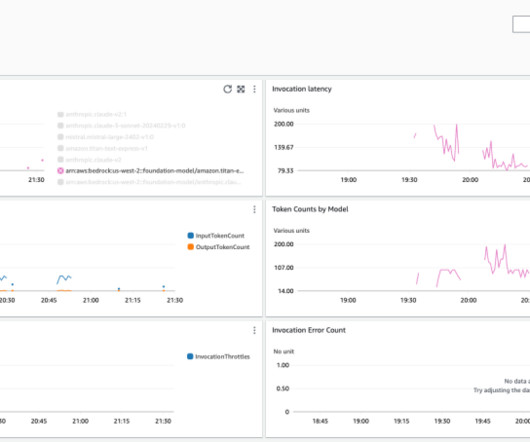
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API. The following screenshot shows the response. You can try out something harder as well.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsibleAI.
This is where the concept of guardrails comes into play, providing a comprehensive framework for implementing governance and control measures with safeguards customized to your application requirements and responsibleAI policies. TDD is a software development methodology that emphasizes writing tests before implementing actual code.
After closely observing the softwareengineering landscape for 23 years and engaging in recent conversations with colleagues, I can’t help but feel that a specialized Large Language Model (LLM) is poised to power the following programming language revolution.
Sessions: Keynotes: Eric Xing, PhD, Professor at CMU and President of MBZUAI: Toward Public and Reproducible Foundation Models Beyond Lingual Intelligence Book Signings: Sinan Ozdemir: Quick Start Guide to Large LanguageModels Matt Harrison: Effective Pandas: Patterns for Data Manipulation Workshops: Adaptive RAG Systems with Knowledge Graphs: Building (..)
For a demonstration on how you can use a RAG evaluation framework in Amazon Bedrock to compute RAG quality metrics, refer to New RAG evaluation and LLM-as-a-judge capabilities in Amazon Bedrock. ResponsibleAI Implementing responsibleAI practices is crucial for maintaining ethical and safe deployment of RAG systems.
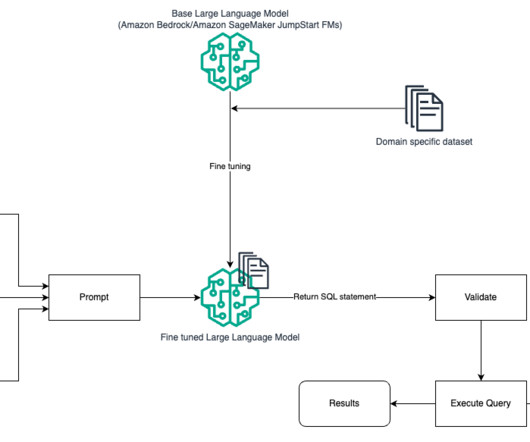
You can use supervised fine-tuning based on your LLM to improve the effectiveness of text-to-SQL. Prompt engineering – The model is trained to complete prompts designed to prompt the target SQL syntax. This prompt engineering allows you to develop the capability without needing to do fine-tuning.
His current area of research includes LLM evaluation and data generation. With over 15 years of experience, he supports customers globally in leveraging AI and ML for innovative solutions and building ML platforms on AWS. Li Erran Li is the applied science manager at humain-in-the-loop services, AWS AI, Amazon.
Must-Use Data Visualization Datasets, AI Frameworks for SoftwareEngineering, DynGAN, and 50% Off ODSC West 12 Must-Use Datasets for Data Visualization in 2024 Need to practice making sense of your data? Learn how to ensure AI benefits people and aligns with ethical standards across various industries.
To scale ground truth generation and curation, you can apply a risk-based approach in conjunction with a prompt-based strategy using LLMs. Its important to note that LLM-generated ground truth isnt a substitute for use case SME involvement. To convert the source document excerpt into ground truth, we provide a base LLM prompt template.
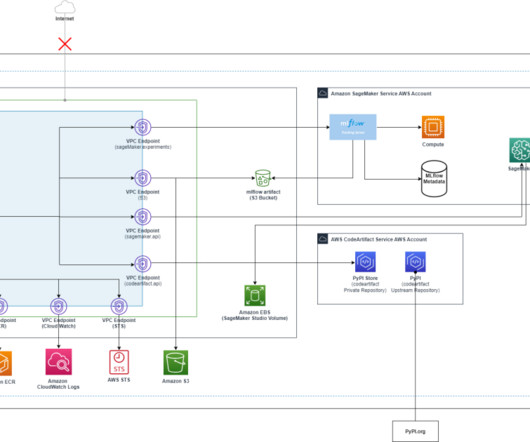
Find more details in the blogpost LLM experimentation with MLFlow. He holds a PhD in Telecommunications Engineering and has experience in softwareengineering. He specializes in responsibleAI, driven by a passion to develop ethically sound and transparent AI solutions.
Fine Tuning Strategies for Language Models and Large Language Models Kevin Noel | AI Lead at Uzabase Speeda | Uzabase Japan-US Language Models (LM) and Large Language Models (LLM) have proven to have applications across many industries. This talk provides a comprehensive framework for securing LLM applications.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies, such as AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsibleAI.
In this post Toloka showcases Human-in-the-Loop using StarCoder, a code LLM, as an example. This successful implementation demonstrates how responsibleAI and high-performing models can align. The risks of harmful results do not align with the principles of ResponsibleAI.
RAG enables LLMs to generate more relevant, accurate, and contextual responses by cross-referencing an organization’s internal knowledge base or specific domains, without the need to retrain the model. The question and context are combined and fed as a prompt to the LLM.
As customers look to operationalize these new generative AI applications, they also need prescriptive, out-of-the-box ways to monitor the health and performance of these applications. For example, you can write a Logs Insights query to calculate the token usage of the various applications and users calling the large language model (LLM).
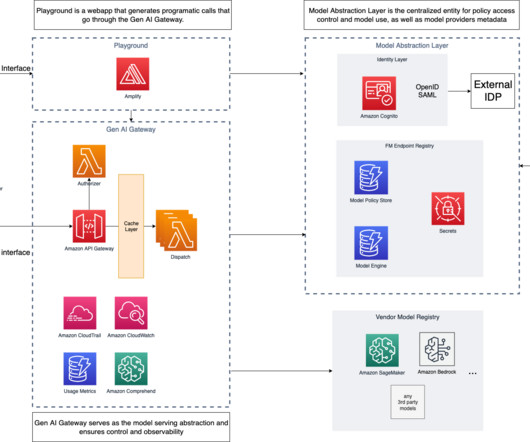
This means companies need loose coupling between app clients (model consumers) and model inference endpoints, which ensures easy switch among large language model (LLM), vision, or multi-modal endpoints if needed. When the user makes a request using the AI Gateway, it’s routed to Amazon Cognito to determine access for the client.
In softwareengineering, there is a direct correlation between team performance and building robust, stable applications. Using machine learning, AMI zAdviser monitors mainframe build, test and deploy functions across DevOps tool chains and then offers AI-led recommendations for continuous improvement.
Whats Next in AI TrackExplore the Cutting-Edge Stay ahead of the curve with insights into the future of AI. AIEngineering TrackBuild Scalable AISystems Learn how to bridge the gap between AI development and softwareengineering.
Conversational AI agents also encompass multiple layers, from Retrieval Augmented Generation (RAG) to function-calling mechanisms that interact with external knowledge sources and tools. Although existing large language model (LLM) benchmarks like MT-bench evaluate model capabilities, they lack the ability to validate the application layers.
These organizations and others will be showcasing their latest products and services that can help you implement AI in your organization or improve your processes that are already in progress. Learn more about the AI Insight Talks below.
to be precise) of data scientists and engineers plan to deploy Large Language Model (LLM) applications into production in the next 12 months or “as soon as possible.” of data science teams have implemented LLM applications currently in use by their own or client companies. Additionally, the data indicates that 8.3%
This article by Samhita Alla, a softwareengineer and tech evangelist at Union.ai, provides a simplified walkthrough of the applications of Flyte in MLOps. LLM training configurations. Guardrails: – Does pydantic-style validation of LLM outputs. Check out the documentation to get started.
Ali Arsanjani, director of cloud partner engineering at Google Cloud , presented a talk entitled “Challenges and Ethics of DLM and LLM Adoption in the Enterprise” at Snorkel AI’s recent Foundation Model Virtual Summit. Below follows a transcript of his talk, lightly edited for readability.
Ali Arsanjani, director of cloud partner engineering at Google Cloud , presented a talk entitled “Challenges and Ethics of DLM and LLM Adoption in the Enterprise” at Snorkel AI’s recent Foundation Model Virtual Summit. Below follows a transcript of his talk, lightly edited for readability.
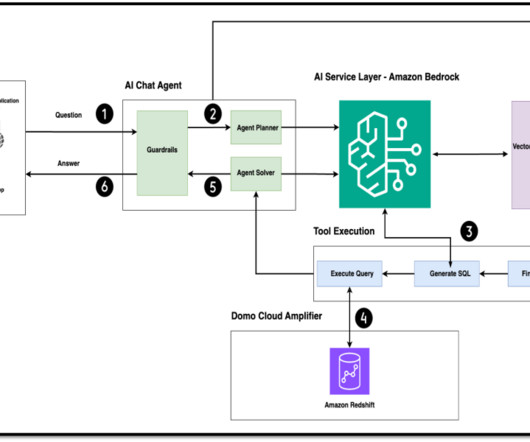
As you build and refine your web search agent with Amazon Bedrock, keep these factors in mind to provide a robust, scalable, and responsibleAI system. Expanding the solution With this post, you’ve taken the first step towards revolutionizing your applications with Amazon Bedrock Agents and the power of agentic workflows with LLMs.
I am a Principal SoftwareEngineer at Microsoft, where I have worked on various AI projects and have been a core contributor in the development of Microsoft Copilot. While my colleagues recognize me as a diligent engineer, but only a few have had the opportunity to witness my prowess as a skier. All the way to AGI?
This solution is also deployed by using the AWS Cloud Development Kit (AWS CDK), which is an open-source software development framework that defines cloud infrastructure in modern programming languages and provisions it through AWS CloudFormation. Domain-scoped agents enable code reuse across multiple agents.
With a PhD, a law degree, and a Harvard fellowship, Rajiv is not only a technical leader but also a dynamic communicatorhis viral AI insights on @rajistics have amassed over 10 millionviews. Dr. Andre Franca, CTO ofErgodic Andre is the co-founder and CTO of Ergodic, pioneering AI powered by world models for smarter decision-making.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsibleAI.
In this episode, they discussed the democratization of AI, advancements in AI-assisted coding, and the ethics of innovation. Paige also discussed the need for responsibleAI development, the importance of careful product design around LLMs, the role of a product manager within AI research teams, and much more.
In this blog post, we provide an introduction to preparing your own dataset for LLM training. Whether your goal is to fine-tune a pre-trained modIn this blog post, we provide an introduction to preparing your own dataset for LLM training. Generally, for training an LLM, there are a variety of approaches that you can take.
RAG is the process of optimizing the output of a large language model (LLM) so it references an authoritative knowledge base outside of its training data sources before generating a response. Bhaskar Pratap is a Senior SoftwareEngineer with the Amazon SageMaker team.
Moreover, well-designed prompts serve to steer the model towards the specific task at hand, ensuring that the LLM focuses on the most relevant information and produces outputs aligned with the desired outcome. The context-aware nature of the LLM, combined with careful prompt engineering, resulted in more natural and accurate translations.
” “Meta and other ‘open’ LLM providers might go this route to keep their competitive advantage: more openness about the models, but preventing competitors from using them,” Sobrier warned. Response: Set and enforce guardrails to ensure safe and secure model adoption.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content