This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Researchers at Amazon have trained a new large language model (LLM) for text-to-speech that they claim exhibits “emergent” abilities. Explore other upcoming enterprise technology events and webinars powered by TechForge here.
The effectiveness of RAG heavily depends on the quality of context provided to the large language model (LLM), which is typically retrieved from vector stores based on user queries. In this post, we explore an innovative approach that uses LLMs on Amazon Bedrock to intelligently extract metadata filters from naturallanguage queries.
Large language models ( LLMs ) like GPT-4, PaLM, Bard, and Copilot have made a huge impact in naturallanguageprocessing (NLP). The post What are Small Language Models (SLMs)? They can generate text, solve problems, and carry out conversations with remarkable accuracy.
Large Language Models (LLMs) have shown remarkable capabilities across diverse naturallanguageprocessing tasks, from generating text to contextual reasoning. These challenges have driven researchers to seek more efficient ways to enhance LLM performance while minimizing resource demands.
Large language models’ (LLMs) training pipelines are the source of inspiration for this method in the field of naturallanguageprocessing (NLP). Tokenizing input is a crucial part of LLM training, and it’s commonly accomplished using byte pair encoding (BPE).
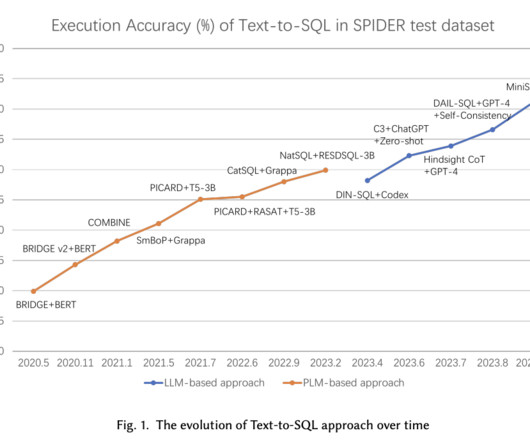
The inherent complexity of SQL syntax and the intricacies involved in database schema understanding make this a significant problem in naturallanguageprocessing (NLP) and database management. The proposed method in this paper leverages LLMs for Text-to-SQL tasks through two main strategies: prompt engineering and fine-tuning.
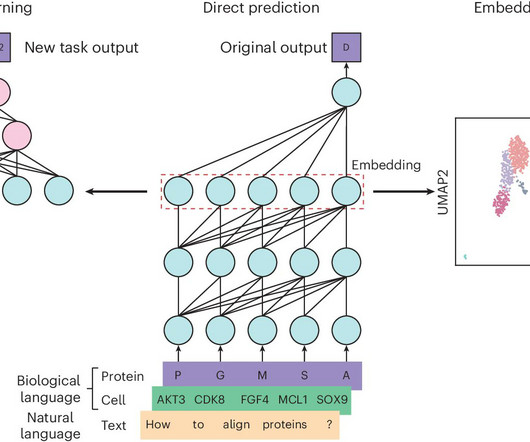
Biological data, such as DNA, RNA, and protein sequences, are fundamentally different from naturallanguage text, yet they share sequential characteristics that make them amenable to similar processing techniques. If you like our work, you will love our newsletter.
Large language models (LLMs) have made significant leaps in naturallanguageprocessing, demonstrating remarkable generalization capabilities across diverse tasks. This limitation poses a significant hurdle for AI-driven applications requiring structured LLM outputs integrated into their data streams.
Large language models (LLMs) have become crucial in naturallanguageprocessing, particularly for solving complex reasoning tasks. However, while LLMs can process and generate responses based on vast amounts of data, improving their reasoning capabilities is an ongoing challenge. Check out the Paper.
A 2-for-1 ODSC East Black Friday Deal, Multi-Agent Systems, Financial Data Engineering, and LLM Evaluation ODSC East 2025 Black Friday Deal Take advantage of our 2-for-1 Black Friday sale and join the leading conference for data scientists and AI builders. Learn, innovate, and connect as we shape the future of AI — together!
The ever-increasing size of Large Language Models (LLMs) presents a significant challenge for practical deployment. Despite their transformative impact on naturallanguageprocessing, these models are often hindered by high memory transfer requirements, which pose a bottleneck during autoregressive generation.
Studies explored whether these errors could be eliminated or required management, recognizing them as an intrinsic challenge of LLMs. Recent advancements in LLMs have revolutionized naturallanguageprocessing, yet the persistent challenge of hallucinations necessitates a deeper examination of their fundamental nature and implications.
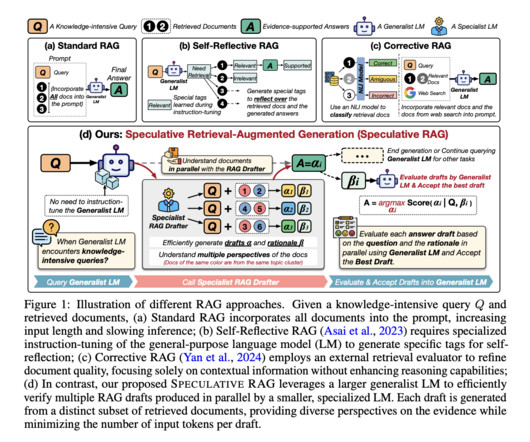
In the rapidly evolving field of naturallanguageprocessing (NLP), integrating external knowledge bases through Retrieval-Augmented Generation (RAG) systems represents a significant leap forward. However, while RAG systems have improved the performance of LLMs across various tasks, they still face critical limitations.
By encouraging models to divide tasks into intermediate steps, much like humans methodically approach complex problems, CoT improves the problem-solving process. This method has proven to be extremely effective in a number of applications, earning it a key position in the naturallanguageprocessing (NLP) community.
70b by Mobius Labs, boasting 70 billion parameters, has been designed to enhance the capabilities in naturallanguageprocessing (NLP), image recognition, and data analysis. Its improvements in naturallanguageprocessing, image recognition, and data analysis, combined with its efficiency and scalability.
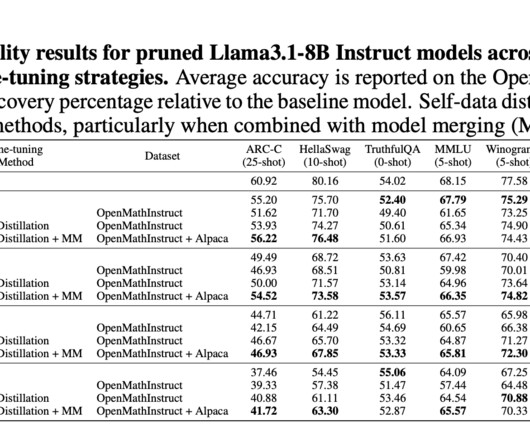
Large language models (LLMs) have become crucial tools for applications in naturallanguageprocessing, computational mathematics, and programming. A strong challenge in LLM optimization arises from the fact that traditional pruning methods are fixed. Dont Forget to join our 65k+ ML SubReddit.
Large Language Models (LLMs) have revolutionized naturallanguageprocessing, demonstrating remarkable capabilities in various applications. ” These limitations have spurred researchers to explore innovative solutions that can enhance LLM performance without the need for extensive retraining.
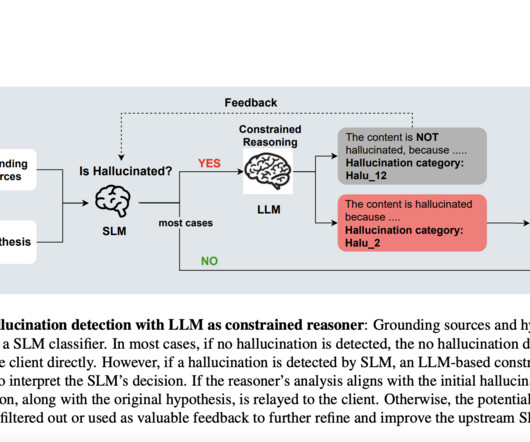
Large Language Models (LLMs) have demonstrated remarkable capabilities in various naturallanguageprocessing tasks. This issue undermines the reliability of LLMs and makes hallucination detection a critical area of research.
Large Language Models (LLMs) have achieved remarkable progress in the ever-expanding realm of artificial intelligence, revolutionizing naturallanguageprocessing and interaction. In conclusion, Agent Q represents a monumental leap forward in developing autonomous web agents.
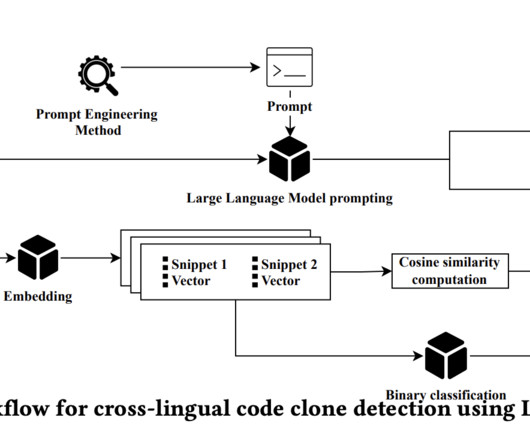
Recent advances in Artificial Intelligence and Machine Learning have made tremendous progress in handling many computing jobs possible, especially with the introduction of Large Language Models (LLMs). The study offers insightful information about how well LLM performs in code clone identification.
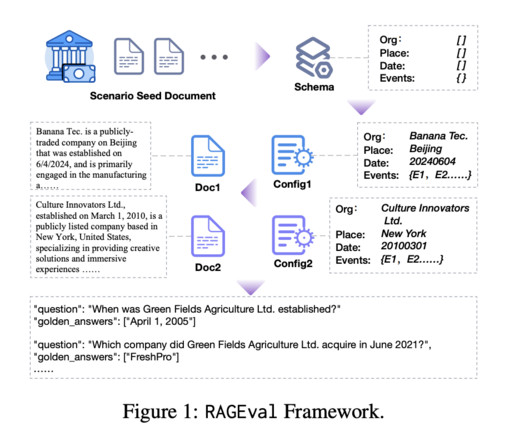
Question answering (QA) is a crucial area in naturallanguageprocessing (NLP), focusing on developing systems that can accurately retrieve and generate responses to user queries from extensive data sources. of cases compared to leading LLM answers. The framework also highlighted a 25.1%
Large language models (LLMs) like GPT-4, Gemini, and Llama 3 have revolutionized naturallanguageprocessing through extensive pre-training and supervised fine-tuning (SFT). Structured pruning has emerged as a promising method to improve LLM efficiency by selectively removing less critical components.
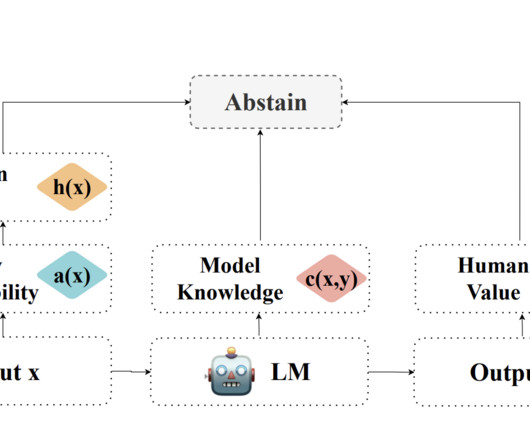
Evaluation benchmarks like SituatedQA and AmbigQA have been crucial in assessing LLM performance with unanswerable or ambiguous questions. These contributions have established a foundation for implementing effective abstention strategies in LLMs, enhancing their ability to handle uncertain or potentially harmful queries.
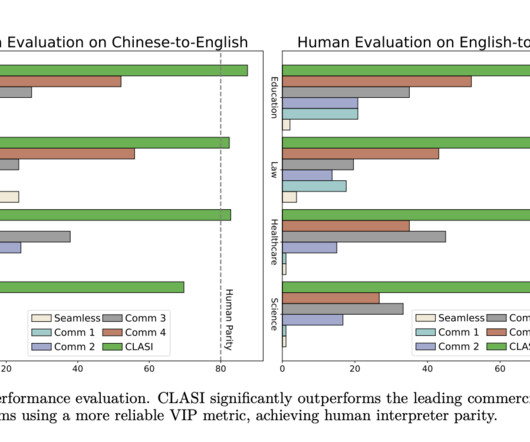
The ability to translate spoken words into another language in real time is known as simultaneous speech translation, and it paves the way for instantaneous communication across language barriers. There has been a lot of buzz about machine-assisted autonomous interpretation in naturallanguageprocessing (NLP).
Large Language Models (LLMs), like ChatGPT and GPT-4 from OpenAI, are advancing significantly and transforming the field of NaturalLanguageProcessing (NLP) and NaturalLanguage Generation (NLG), thus paving the way for the creation of a plethora of Artificial Intelligence (AI) applications indispensable to daily life.
The field of naturallanguageprocessing has made substantial strides with the advent of Large Language Models (LLMs), which have shown remarkable proficiency in tasks such as question answering. However, despite their success, LLMs need help dealing with knowledge-intensive queries.
These models are essential in various applications, including naturallanguageprocessing. These models, however, need to fully leverage the generative abilities of large language models (LLMs). For example, when verifying outputs from the Gemini 1.0 If you like our work, you will love our newsletter.
The recent development of large language models (LLMs) has transformed the field of NaturalLanguageProcessing (NLP). LLMs show human-level performance in many professional and academic fields, showing a great understanding of language rules and patterns.
NaturalLanguageProcessing (NLP), despite its progress, faces the persistent challenge of hallucination, where models generate incorrect or nonsensical information. More recent approaches use LLM-generated data to evaluate contextual relevance, faithfulness, and informativeness.
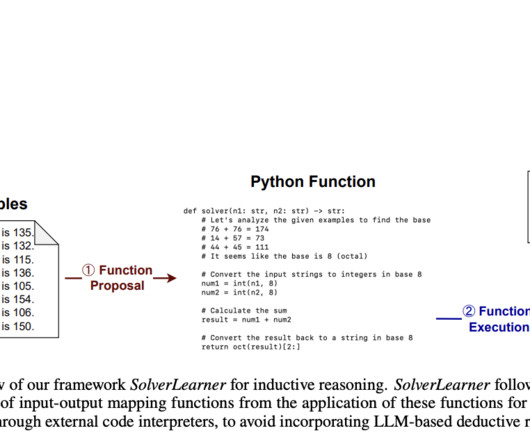
With the development of huge Large Language Models (LLMs), such as GPT-3 and GPT-4, NaturalLanguageProcessing (NLP) has developed incredibly in recent years. The current work is going to establish whether LLMs can do basic reasoning or simply use memorized patterns to approximate the answers.
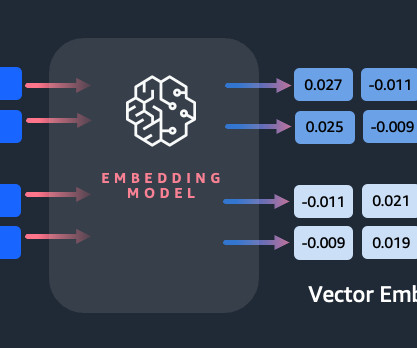
Embeddings play a key role in naturallanguageprocessing (NLP) and machine learning (ML). Text embedding refers to the process of transforming text into numerical representations that reside in a high-dimensional vector space. You can then generate focused summaries from those groupings’ content using an LLM.
Large language models (LLMs) have seen remarkable success in naturallanguageprocessing (NLP). They also introduced two case studies to demonstrate practical approaches to address LLM resource limitations while maintaining performance. Check out the Paper.
Large language models (LLMs) have gained significant attention due to their potential to enhance various artificial intelligence applications, particularly in naturallanguageprocessing. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
NaturalLanguageProcessing (NLP): Techniques for processing and understanding human language. Artificial Superintelligence (ASI): A speculative future stage where AI surpasses human intelligence, raising both potential benefits and risks. Computer Vision: Systems that analyze and interpret visual data.
Thus, developing effective methods to reduce hallucinations without compromising the model’s performance is a significant goal in naturallanguageprocessing. Watson Research Center has introduced a novel method leveraging the memory-augmented LLM named Larimar. A Team of researchers from IBM Research and T.
Multilingual applications and cross-lingual tasks are central to naturallanguageprocessing (NLP) today, making robust embedding models essential. These models underpin systems like retrieval-augmented generation and other AI-driven solutions. Dont Forget to join our 60k+ ML SubReddit.
Despite such successes in naturallanguageprocessing, computer vision, and other areas, their development often relies on heuristic approaches, limiting interpretability and scalability. Self-attention mechanisms are also vulnerable to data corruption and adversarial attacks, which makes them unreliable in practice.
Advancements in neural networks have brought significant changes across domains like naturallanguageprocessing, computer vision, and scientific computing. Despite these successes, the computational cost of training such models remains a key challenge. Dont Forget to join our 60k+ ML SubReddit.
Additionally, large language model (LLM)-based analysis is applied to derive further insights, such as video summaries and classifications. He leads machine learning initiatives and projects across business domains, leveraging multimodal AI, generative models, computer vision, and naturallanguageprocessing.
The following are some of the experiments that were conducted by the team, along with the challenges identified and lessons learned: Pre-training – Q4 understood the complexity and challenges that come with pre-training an LLM using its own dataset. In addition to the effort involved, it would be cost prohibitive.
Despite its importance, generating accurate, detailed, and descriptive video captions is challenging in fields like computer vision and naturallanguageprocessing. The researchers introduced CapScore, an LLM-based metric that evaluates the similarity and quality of generated captions compared to the ground truth.
LLMs such as LLaMA, MAP-Neo, Baichuan, Qwen, and Mixtral are trained on large amounts of text data, exhibiting strong capacities in naturallanguageprocessing and task resolution through text generation capacity. It also provides multilingual support for languages such as English and Chinese.
Large Language Models (LLMs) have revolutionized naturallanguageprocessing, enabling AI systems to perform a wide range of tasks with remarkable proficiency. However, researchers face significant challenges in optimizing LLM performance, particularly in human-LLM interactions.
For instance, in naturallanguageprocessing tasks, the sparse models performed competitively in metrics like perplexity and BLEU scores, supporting applications such as summarization, translation, and question answering. Similarly, the LLaMA 3.3 These results demonstrate tangible benefits. 8BandLlama 3.3
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















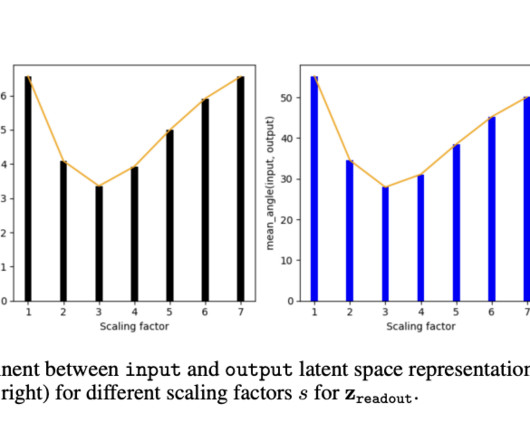




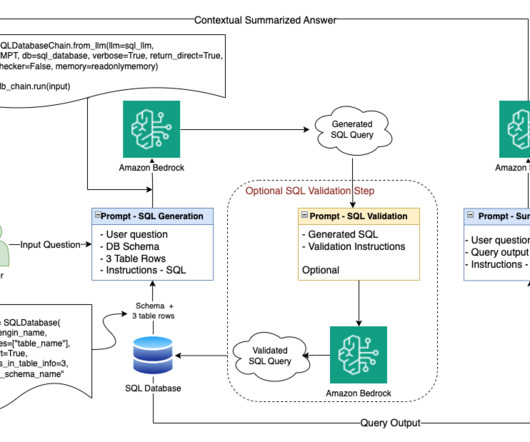
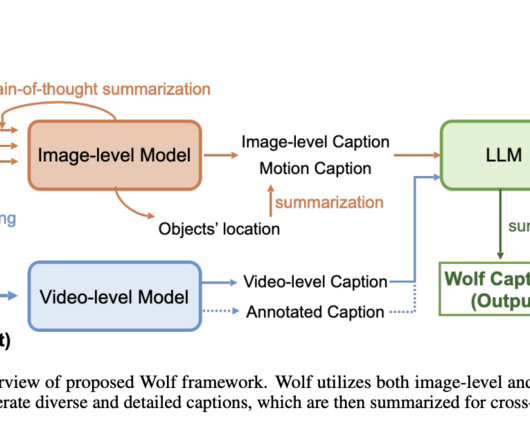









Let's personalize your content