This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The latest release of MLPerf Inference introduces new LLM and recommendation benchmarks, marking a leap forward in the realm of AI testing. It requires real engineering work and is a testament to our submitters’ commitment to AI, to their customers, and to ML.” The spotlight of MLPerf Inference v3.1 The post MLPerf Inference v3.1
By specializing in defense-oriented data, this LLM not only boasts enhanced accuracy but also improves in areas such as secure data handling, operational confidentiality, and compliance with strict defense regulations. Don’t Forget to join our 55k+ ML SubReddit. If you like our work, you will love our newsletter.
LLM Agents Learning Platform A unique course focusing on leveraging large language models (LLMs) to create advanced AI agents for diverse applications. Also, dont forget to join our 60k+ ML SubReddit. Dont forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
Gemma, and Mistral, Stable LM 2 12B offers solid results when tested on zero-shot and few-shot tasks across general benchmarks outlined in the Open LLM leaderboard: With this new release, Stability AI extends the StableLM 2 family into the 12B category, providing an open and transparent model without compromising power and accuracy.
Dont Forget to join our 65k+ ML SubReddit. FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
Managing datasets effectively has become a pressing challenge as machine learning (ML) continues to grow in scale and complexity. These challenges are particularly acute in large-scale ML projects, where proper data curation and version control are essential to ensure reliable results. Dont Forget to join our 60k+ ML SubReddit.
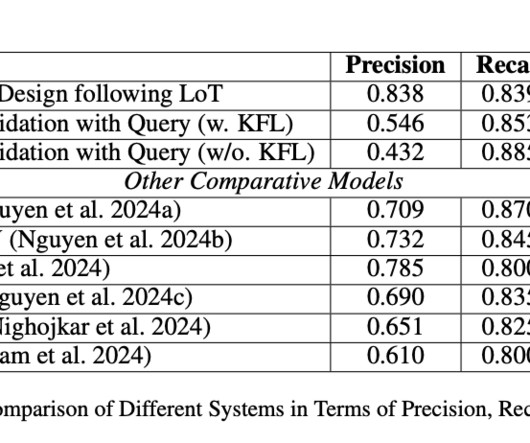
These challenges have driven researchers to seek more efficient ways to enhance LLM performance while minimizing resource demands. Conclusion SepLLM addresses critical challenges in LLM scalability and efficiency by focusing on Initial Tokens, Neighboring Tokens, and Separator Tokens. Dont Forget to join our 60k+ ML SubReddit.
Dont Forget to join our 60k+ ML SubReddit. FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
Dont Forget to join our 60k+ ML SubReddit. FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy. The post Dolphin 3.0
Dont Forget to join our 65k+ ML SubReddit. FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
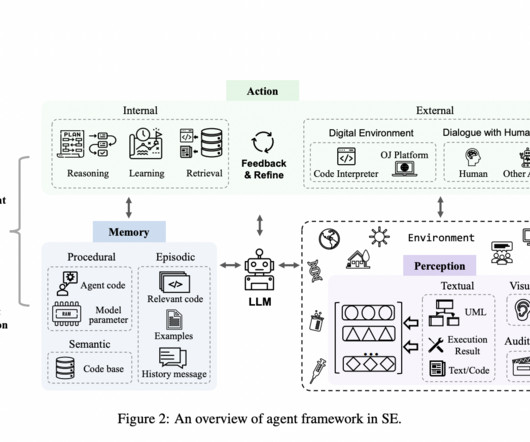
Current tools used in software engineering, such as LLM-based models, assist developers by automating tasks like code summarization, bug detection, and code translation. This framework uses LLM-driven agents for software engineering tasks and includes three key modules: perception, memory, and action.
Current methods for improving LLM reasoning capabilities include strategies such as knowledge distillation, where a smaller model learns from a larger model, and self-improvement, where models are trained on data they generate themselves. Significant improvements in LLM performance were observed across various benchmarks.
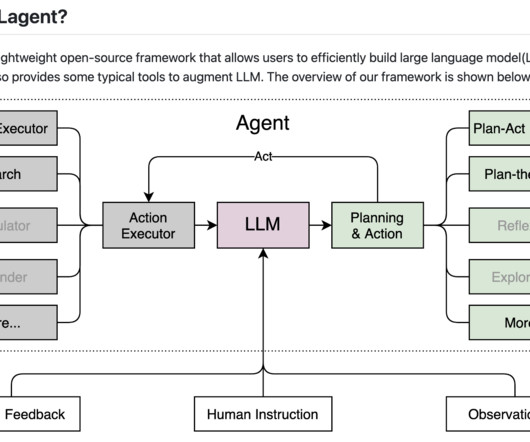
Introducing Lagent, a new open-source framework that simplifies the process of building large language model (LLM)-based agents. Lagent stands out by offering a lightweight and flexible solution that supports various models and provides tools to enhance the capabilities of LLMs.
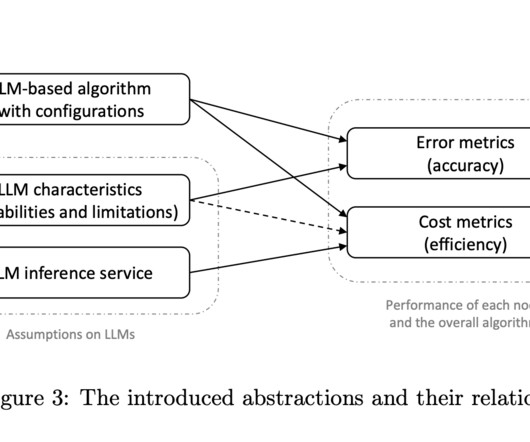
The primary issue addressed in the paper is the need for formal analysis and structured design principles for LLM-based algorithms. This approach is inefficient and lacks a theoretical foundation, making it difficult to optimize and accurately predict the performance of LLM-based algorithms.
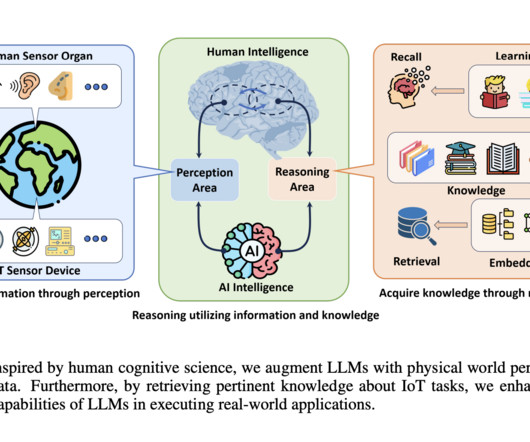
MARS Lab, NTU has devised an innovative IoT-LLM framework that combats the limitations of the LLM in handling real-world tasks. For example, in traditional LLMs like Chat-GPT 4, only 40% accuracy in activity recognition and 50% in machine diagnosis are achieved after processing the raw IoT data.
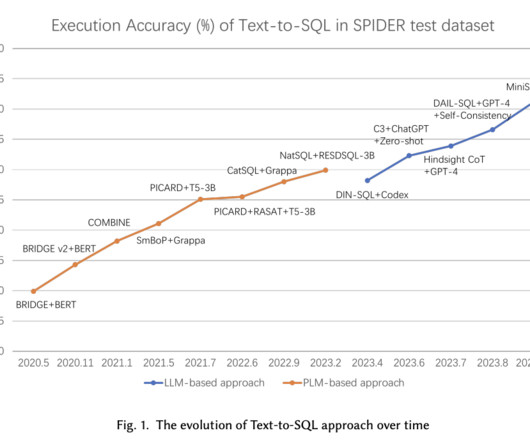
These include Chain-of-Thought (CoT), which guides LLMs to generate answers step by step by adding specific prompts to break down the task; Least-to-Most, which decomposes a complex problem into simpler sub-problems; and Self-Consistency, which uses a majority voting strategy to select the most frequent answer generated by the LLM.
The study found no statistically significant improvement in success rates or speed of completing cyberattack phases with the LLM compared to traditional methods like search engines. In conclusion, Meta AI effectively outlines the challenges of assessing LLM cybersecurity capabilities and introduces CYBERSECEVAL 3 to address these challenges.
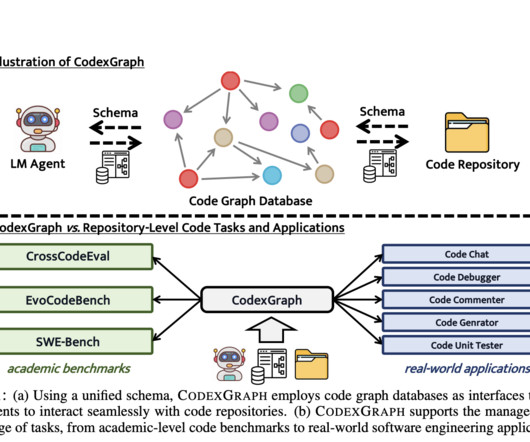
Successfully addressing this challenge is essential for advancing automated software engineering, particularly in enabling LLMs to handle real-world software development tasks that require a deep understanding of large-scale repositories. Check out the Paper and GitHub. All credit for this research goes to the researchers of this project.
Several benchmark collections for evaluation, such as BFCL, ToolEval, and API-Bank, have been developed to measure LLM tool-use capabilities. It also incorporates an LLM-based user simulator where interactions with the model are conducted in a lifelike, on-policy manner, a more realistic evaluation of its power under real-life conditions.
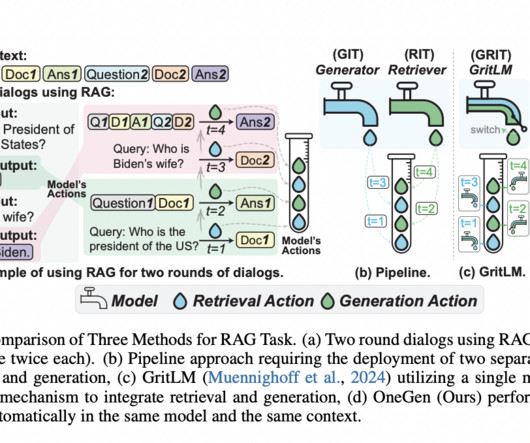
Researchers from Zhejiang University introduce OneGen, a novel solution that unifies the retrieval and generation processes into a single forward pass within an LLM. The technical foundation of OneGen involves augmenting the standard LLM vocabulary with retrieval tokens. If you like our work, you will love our newsletter.
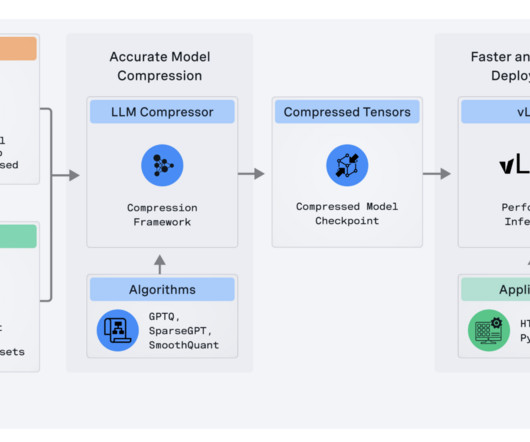
Neural Magic has released the LLM Compressor , a state-of-the-art tool for large language model optimization that enables far quicker inference through much more advanced model compression. The second key technical advancement the LLM Compressor brings is activation and weight quantization support.
Researchers from Google Cloud AI, Google DeepMind, and the University of Washington have proposed a new approach called MODEL SWARMS , which utilizes swarm intelligence to adapt LLMs through collaborative search in the weight space. Don’t Forget to join our 50k+ ML SubReddit. If you like our work, you will love our newsletter.
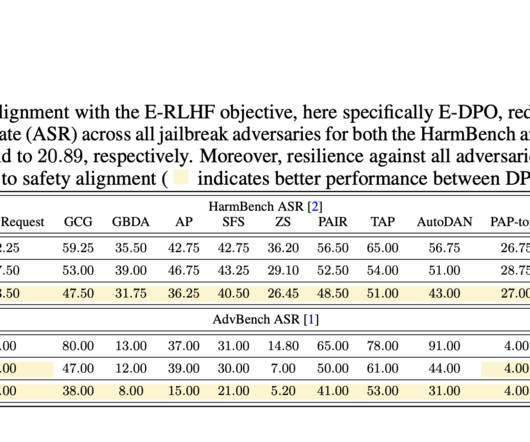
Existing approaches to address these challenges fall into three main categories: baseline methods, LLM automation and suffix-based attacks, and manipulation of the decoding process. Researchers from NYU and MetaAI, FAIR introduce a theoretical framework for analyzing LLM pretraining and jailbreaking vulnerabilities.
” Mosaic AI offers several key components, which Everts outlines: Unified tooling: Provides “tools for building, deploying, evaluating, and governing AI and ML solutions, supporting predictive models and generative AI applications.” Explore other upcoming enterprise technology events and webinars powered by TechForge here.
Foundation Models for TimesSeries Here, we explain how this model adapts the standard LLM architecture to time series, and one of the most important components, large time series data sets, and how they are assembled. What Can You Do With a Free ODSC East ExpoPass? Register by Friday for 30%off!
Research on the robustness of LLMs to jailbreak attacks has mostly focused on chatbot applications, where users manipulate prompts to bypass safety measures. However, LLM agents, which utilize external tools and perform multi-step tasks, pose a greater misuse risk, especially in malicious contexts like ordering illegal materials.
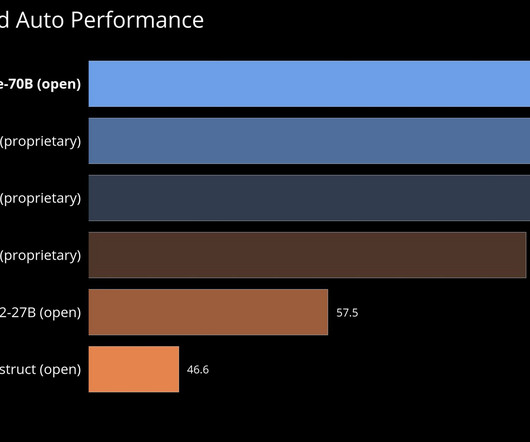
To maximize Llama-3-70B’s potential, Nexusflow developed internal benchmarks evaluating LLM capabilities in instruction following, coding, creative writing, and multilingual tasks. The enhancement stems from Nexusflow’s targeted post-training pipeline, designed to improve specific model behaviors.
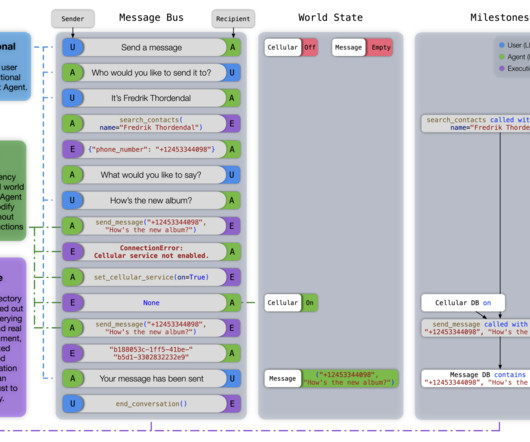
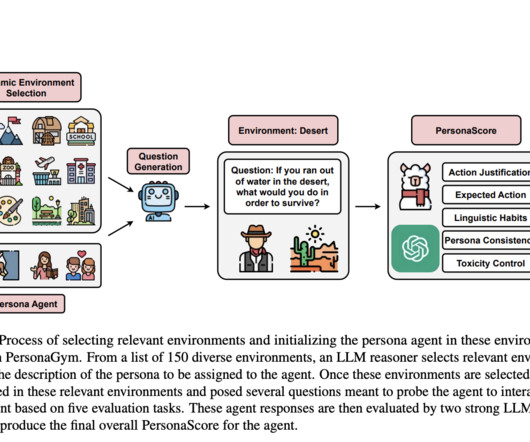
Large Language Model (LLM) agents are experiencing rapid diversification in their applications, ranging from customer service chatbots to code generation and robotics. The process begins with an LLM reasoner selecting appropriate settings from 150 diverse environments, followed by generating task-specific questions.
Despite this, LLMs’ use in requirement engineering has gradually increased, driven by advancements in contextual analysis and reasoning through prompt engineering and Chain-of-Thought techniques. The field of LLM-based agents lacks standardized benchmarks, impeding effective performance evaluation.
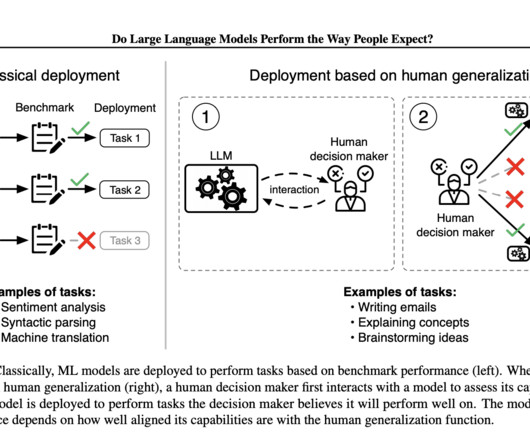
They introduce the concept of a human generalization function, which models how people update their beliefs about an LLM’s capabilities after interacting with it. This survey generated a dataset of nearly 19,000 examples across 79 tasks, highlighting how humans generalize about LLM performance.
Dont Forget to join our 60k+ ML SubReddit. FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
Large Language Models (LLMs) have transformed artificial intelligence, particularly in developing agent-based systems. Enhancing the planning capabilities of LLM-based agents has become a critical area of research due to the intricate nature and essential need for precise task completion in numerous applications.
Don’t Forget to join our 50k+ ML SubReddit. Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted) The post Stanford Researchers Propose LoLCATS: A Cutting Edge AI Method for Efficient LLM Linearization appeared first on MarkTechPost.
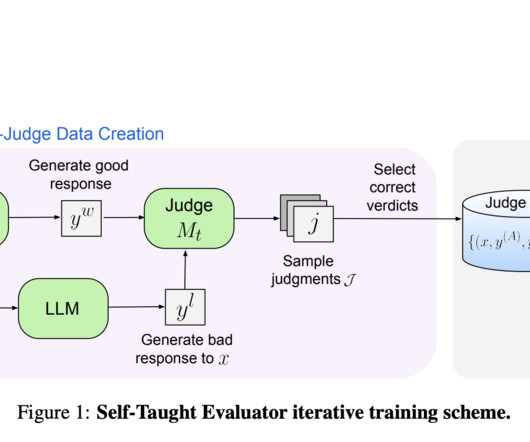
Initially, a baseline response is generated for a given instruction using a seed LLM. A modified version of the instruction is then created, prompting the LLM to generate a new response designed to be lower quality than the original. The model, acting as an LLM-as-a-Judge, generates reasoning traces and judgments for these pairs.
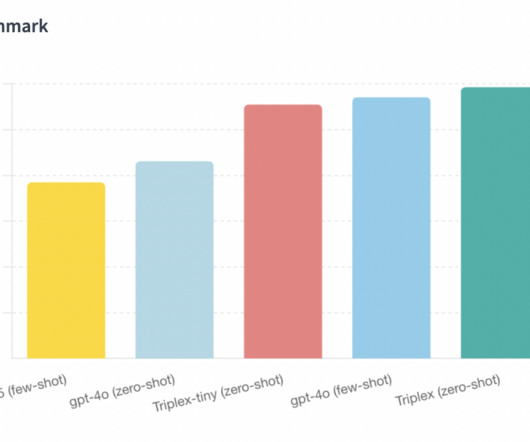
SciPhi has recently announced the release of Triplex , a state-of-the-art language model (LLM) designed specifically for knowledge graph construction. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup. If you like our work, you will love our newsletter.
This limitation poses a significant hurdle for AI-driven applications requiring structured LLM outputs integrated into their data streams. These advancements enhance the reliability and precision of LLM outputs, making Sketch a versatile solution for diverse NLP applications in both research and industrial settings.
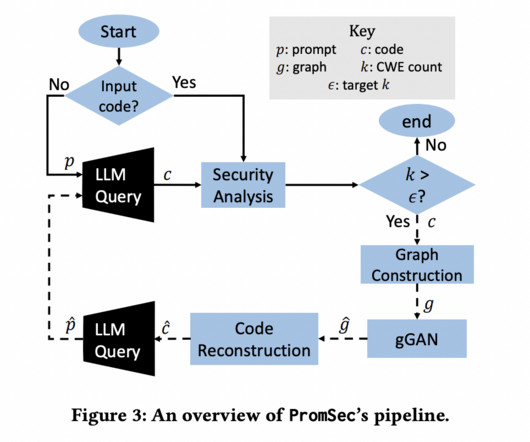
A team of researchers from the New Jersey Institute of Technology and Qatar Computing Research Institute has introduced PromSec, a solution that has been created to address this problem, which aims at optimizing LLM prompts to generate secure and functional code. It functions by combining two essential parts, which are as follows.
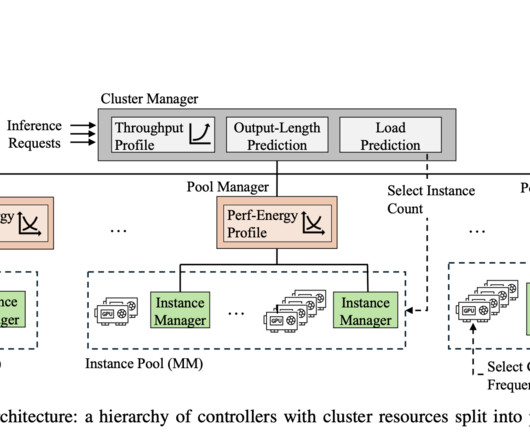
Generative Large Language Models (LLMs) have become an essential part of many applications due to their quick growth and widespread use. This means that the energy consumption of the inference clusters can be optimized by knowing the distinct processing requirements of different LLM tasks and how these requirements vary over time.
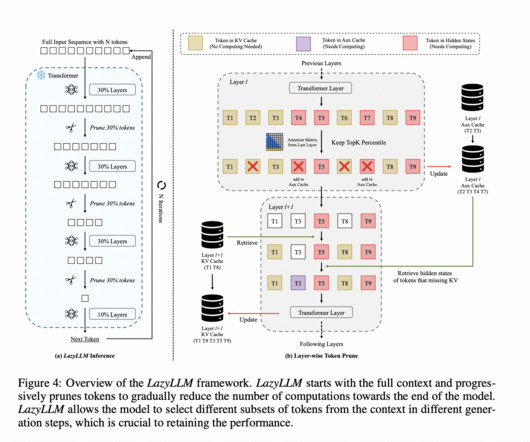
Optimizing TTFT has become a critical path toward efficient LLM inference. Prior studies have explored various approaches to address the challenges of efficient long-context inference and TTFT optimization in LLMs. The LazyLLM framework is designed to optimize LLM inference through progressive token pruning. Check out the Paper.
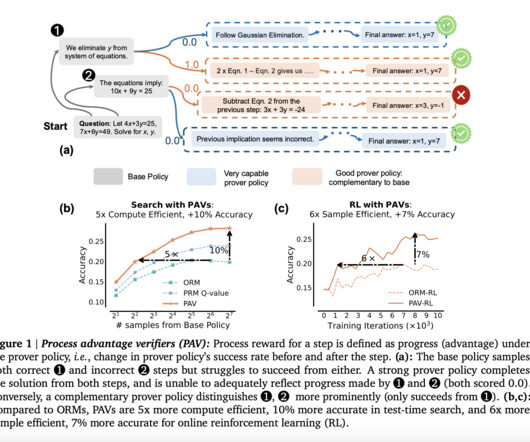
The key innovation in PAVs is using a “prover policy,” distinct from the base policy that the LLM is following. This enables the LLM to explore a wider range of potential solutions, even when early steps do not immediately lead to a correct solution. Don’t Forget to join our 50k+ ML SubReddit. Check out the Paper.
Large Language Models (LLMs) have advanced rapidly, becoming powerful tools for complex planning and cognitive tasks. This progress has spurred the development of LLM-powered multi-agent systems (LLM-MA systems), which aim to simulate and solve real-world problems through coordinated agent cooperation.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content