This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
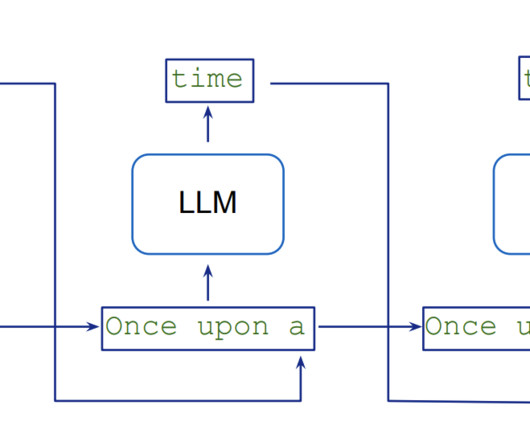
Researchers developed Medusa , a framework to speed up LLM inference by adding extra heads to predict multiple tokens simultaneously. This post demonstrates how to use Medusa-1, the first version of the framework, to speed up an LLM by fine-tuning it on Amazon SageMaker AI and confirms the speed up with deployment and a simple load test.
This transcription then serves as the input for a powerful LLM, which draws upon its vast knowledge base to provide personalized, context-aware responses tailored to your specific situation. LLM integration The preprocessed text is fed into a powerful LLM tailored for the healthcare and life sciences (HCLS) domain.
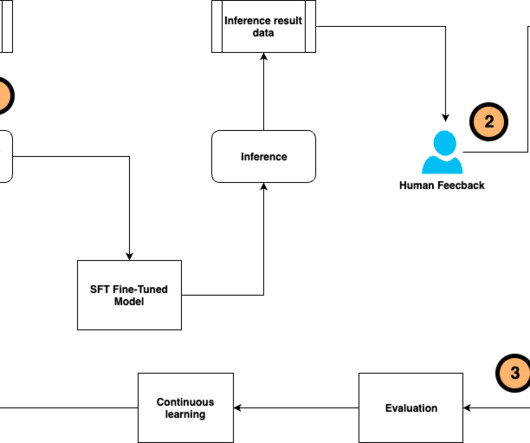
Fine-tuning a pre-trained large language model (LLM) allows users to customize the model to perform better on domain-specific tasks or align more closely with human preferences. You can use supervised fine-tuning (SFT) and instruction tuning to train the LLM to perform better on specific tasks using human-annotated datasets and instructions.
Large language models (LLMs) have achieved remarkable success in various natural language processing (NLP) tasks, but they may not always generalize well to specific domains or tasks. You may need to customize an LLM to adapt to your unique use case, improving its performance on your specific dataset or task.
Introduction to AI and Machine Learning on Google Cloud This course introduces Google Cloud’s AI and ML offerings for predictive and generative projects, covering technologies, products, and tools across the data-to-AI lifecycle. It covers how to develop NLP projects using neural networks with Vertex AI and TensorFlow.
Building LLMs for Production: Enhancing LLM Abilities and Reliability with Prompting, Fine-Tuning, and RAG” is now available on Amazon! The application topics include prompting, RAG, agents, fine-tuning, and deployment — all essential topics in an AI Engineer’s toolkit.” The defacto manual for AI Engineering.
Large Language Models (LLMs) have revolutionized the field of natural language processing (NLP), improving tasks such as language translation, text summarization, and sentiment analysis. Monitoring the performance and behavior of LLMs is a critical task for ensuring their safety and effectiveness.
This generative AI task is called text-to-SQL, which generates SQL queries from natural language processing (NLP) and converts text into semantically correct SQL. With the emergence of large language models (LLMs), NLP-based SQL generation has undergone a significant transformation. on Amazon Bedrock as our LLM.
We formulated a text-to-SQL approach where by a user’s natural language query is converted to a SQL statement using an LLM. This data is again provided to an LLM, which is asked to answer the user’s query given the data. The relevant information is then provided to the LLM for final response generation.
In part 1 of this blog series, we discussed how a large language model (LLM) available on Amazon SageMaker JumpStart can be fine-tuned for the task of radiology report impression generation. This post then seeks to assess whether prompt engineering is more performant for clinical NLP tasks compared to the RAG pattern and fine-tuning.
Machine learning (ML) engineers have traditionally focused on striking a balance between model training and deployment cost vs. performance. This is important because training ML models and then using the trained models to make predictions (inference) can be highly energy-intensive tasks.
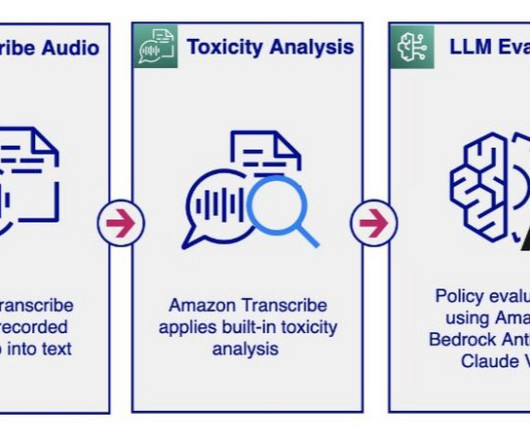
The LLM analysis provides a violation result (Y or N) and explains the rationale behind the model’s decision regarding policy violation. The audio moderation workflow activates the LLM’s policy evaluation only when the toxicity analysis exceeds a set threshold. LLMs, in contrast, offer a high degree of flexibility.
You will also find useful tools from the community, collaboration opportunities for diverse skill sets, and, in my industry-special Whats AI section, I will dive into the most sought-after role: LLM developers. But who exactly is an LLM developer, and how are they different from software developers and MLengineers?
Snorkel AI held its Enterprise LLM Virtual Summit on October 26, 2023, drawing an engaged crowd of more than 1,000 attendees across three hours and eight sessions that featured 11 speakers. How to fine-tune and customize LLMs Hoang Tran, MLEngineer at Snorkel AI, outlined how he saw LLMs creating value in enterprise environments.
Historically, natural language processing (NLP) would be a primary research and development expense. In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows.
Solution overview In the following sections, we share how you can develop an example ML project with Code Editor on Amazon SageMaker Studio. We will deploy a Mistral-7B large language model (LLM) model into an Amazon SageMaker real-time endpoint using a built-in container from HuggingFace.
Furthermore, we deep dive on the most common generative AI use case of text-to-text applications and LLM operations (LLMOps), a subset of FMOps. MLOps engineers are responsible for providing a secure environment for data scientists and MLengineers to productionize the ML use cases.
Topics Include: Agentic AI DesignPatterns LLMs & RAG forAgents Agent Architectures &Chaining Evaluating AI Agent Performance Building with LangChain and LlamaIndex Real-World Applications of Autonomous Agents Who Should Attend: Data Scientists, Developers, AI Architects, and MLEngineers seeking to build cutting-edge autonomous systems.
We have included a sample project to quickly deploy an Amazon Lex bot that consumes a pre-trained open-source LLM. This mechanism allows an LLM to recall previous interactions to keep the conversation’s context and pace. We also use LangChain, a popular framework that simplifies LLM-powered applications.
Thomson Reuters Labs, the company’s dedicated innovation team, has been integral to its pioneering work in AI and natural language processing (NLP). This technology was one of the first of its kind, using NLP for more efficient and natural legal research. A key milestone was the launch of Westlaw Is Natural (WIN) in 1992.
Services : AI Solution Development, MLEngineering, Data Science Consulting, NLP, AI Model Development, AI Strategic Consulting, Computer Vision. Generative AI integration service : proposes to train Generative AI on clients data and add new features to products.
Amazon Comprehend is a natural language processing (NLP) service that uses ML to uncover insights and relationships in unstructured data, with no managing infrastructure or ML experience required. Amazon SageMaker provides purpose-built tools for ML teams to automate and standardize processes across the ML lifecycle.
TL;DR Finding an optimal set of hyperparameters is essential for efficient and effective training of Large Language Models (LLMs). The key LLM hyperparameters influence the model size, learning rate, learning behavior, and token generation process. Hyperparameters set and tuned during pre-training influence the total size of an LLM.
We hope that you will enjoy watching the videos and learning more about the impact of LLMs on the world. Closing Keynote: LLMOps: Making LLM Applications Production-Grade Large language models are fluent text generators, but they struggle at generating factual, correct content.
The emergence of Large Language Models (LLMs) like OpenAI's GPT , Meta's Llama , and Google's BERT has ushered in a new era in this field. These LLMs can generate human-like text, understand context, and perform various Natural Language Processing (NLP) tasks.
We hope that you will enjoy watching the videos and learning more about the impact of LLMs on the world. Closing Keynote: LLMOps: Making LLM Applications Production-Grade Large language models are fluent text generators, but they struggle at generating factual, correct content.
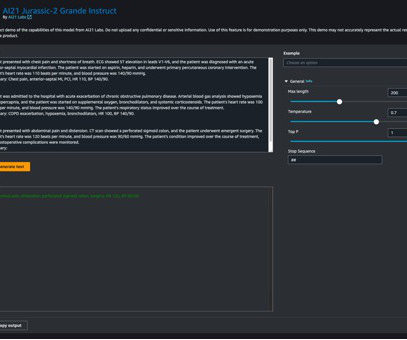
Jurassic-2 Grande Instruct is a large language model (LLM) by AI21 Labs, optimized for natural language instructions and applicable to various language tasks. By fine-tuning the model with your domain-specific data, you can optimize its performance for your particular use case, such as text summarization or any other NLP task.
We hope that you will enjoy watching the videos and learning more about the impact of LLMs on the world. Closing Keynote: LLMOps: Making LLM Applications Production-Grade Large language models are fluent text generators, but they struggle at generating factual, correct content.
Snorkel Foundry will allow customers to programmatically curate unstructured data to pre-train an LLM for a specific domain. Leveraging Data-centric AI for Document Intelligence and PDF Extraction Snorkel AI MLEngineer Ashwini Ramamoorthy highlighted the challenges of extracting entities from semi-structured documents.
Snorkel Foundry will allow customers to programmatically curate unstructured data to pre-train an LLM for a specific domain. Leveraging Data-centric AI for Document Intelligence and PDF Extraction Snorkel AI MLEngineer Ashwini Ramamoorthy highlighted the challenges of extracting entities from semi-structured documents.
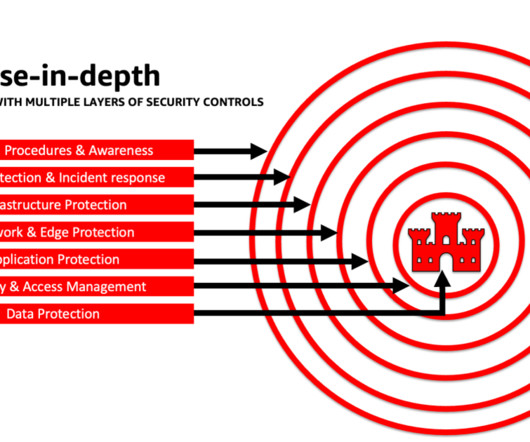
Understanding and addressing LLM vulnerabilities, threats, and risks during the design and architecture phases helps teams focus on maximizing the economic and productivity benefits generative AI can bring. This post provides three guided steps to architect risk management strategies while developing generative AI applications using LLMs.
Available in SageMaker AI and SageMaker Unified Studio (preview) Data scientists and MLengineers can access these applications from Amazon SageMaker AI (formerly known as Amazon SageMaker) and from SageMaker Unified Studio. Deepchecks Deepchecks specializes in LLM evaluation.
Amazon SageMaker helps data scientists and machine learning (ML) engineers build FMs from scratch, evaluate and customize FMs with advanced techniques, and deploy FMs with fine-grain controls for generative AI use cases that have stringent requirements on accuracy, latency, and cost. Of the six challenges, the LLM met only one.
The second script shows how to query those embeddings with an LLM for RAG-based Q&A. This quick workflow lets you maintain a powerful, scalable knowledge base for any LLM-powered application. He brings deep expertise in building and training models for applications like NLP, data visualization, and real-time analytics.
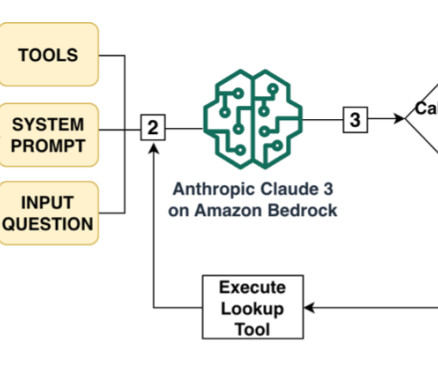
This post dives deep into Amazon Bedrock Knowledge Bases , which helps with the storage and retrieval of data in vector databases for RAG-based workflows, with the objective to improve large language model (LLM) responses for inference involving an organization’s datasets. The LLM response is passed back to the agent.
To give the LLM access to these codes without overwhelming the main prompt, we created lookup tools that the LLM can use to look up for sex, race, and state codes. Because data analysts need to filter on complex combinations of factors, this list can get too long to be reliably rewritten by the LLM in the SQL query.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content