This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Video data analysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.
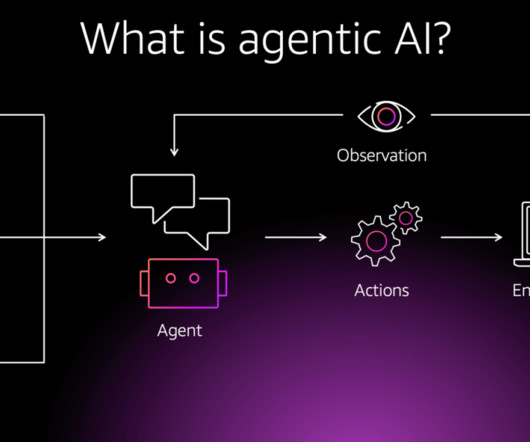
The growth of autonomous agents by foundation models (FMs) like Large Language Models (LLMs) has reform how we solve complex, multi-step problems. These agents perform tasks ranging from customer support to softwareengineering, navigating intricate workflows that combine reasoning, tool use, and memory. What is AgentOps?
Evaluating large language models (LLMs) is crucial as LLM-based systems become increasingly powerful and relevant in our society. Rigorous testing allows us to understand an LLMs capabilities, limitations, and potential biases, and provide actionable feedback to identify and mitigate risk.
Consider a software development use case AI agents can generate, evaluate, and improve code, shifting softwareengineers focus from routine coding to more complex design challenges. Agentic systems, on the other hand, are designed to bridge this gap by combining the flexibility of context-aware systems with domain knowledge.
I don’t need any other information for now We get the following response from the LLM: Based on the image provided, the class of this document appears to be an ID card or identification document. The LLM has filled in the table based on the graph and its own knowledge about the capital of each country.
With this LLM, CreditAI was now able to respond better to broader, industry-wide queries than before. It also enables economies of scale with development velocity given that over 75 engineers at Octus already use AWS services for application development.
We discuss the solution components to build a multimodal knowledge base, drive agentic workflow, use metadata to address hallucinations, and also share the lessons learned through the solution development using multiple large language models (LLMs) and Amazon Bedrock Knowledge Bases.
For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security. The role information is also used to configure metadata filtering in the knowledge bases to generate relevant responses.
They can also introduce context and memory into LLMs by connecting and chaining LLM prompts to solve for varying use cases. Getting recommendations along with metadata makes it more convenient to provide additional context to LLMs. We are excited to launch LangChain integration.
RAG enables LLMs to generate more relevant, accurate, and contextual responses by cross-referencing an organization’s internal knowledge base or specific domains, without the need to retrain the model. The embedding representations of text chunks along with related metadata are indexed in OpenSearch Service.
To create AI assistants that are capable of having discussions grounded in specialized enterprise knowledge, we need to connect these powerful but generic LLMs to internal knowledge bases of documents. The search precision can also be improved with metadata filtering.
You can use metadata filtering to narrow down search results by specifying inclusion and exclusion criteria. For a demonstration on how you can use a RAG evaluation framework in Amazon Bedrock to compute RAG quality metrics, refer to New RAG evaluation and LLM-as-a-judge capabilities in Amazon Bedrock. Nitin Eusebius is a Sr.
In this first step, the AI model, in this case an LLM, is acting as an interpreter and user experience interface between your natural language input and the structured information needed by the travel planning system. The broker agent determines where to send each message based on its content or metadata, making routing decisions at runtime.
To scale ground truth generation and curation, you can apply a risk-based approach in conjunction with a prompt-based strategy using LLMs. Its important to note that LLM-generated ground truth isnt a substitute for use case SME involvement. To convert the source document excerpt into ground truth, we provide a base LLM prompt template.
Fine Tuning Strategies for Language Models and Large Language Models Kevin Noel | AI Lead at Uzabase Speeda | Uzabase Japan-US Language Models (LM) and Large Language Models (LLM) have proven to have applications across many industries. This talk provides a comprehensive framework for securing LLM applications.
They guide the LLM to generate text in a specific tone, style, or adhering to a logical reasoning pattern, etc. For example, an LLM trained on predominantly European data might overrepresent those perspectives, unintentionally narrowing the scope of information or viewpoints it offers. Lets see how to use them in a simple example.
In recent times, the rapid advancement of AI technologies like ChatGPT and other Large Language Models (LLMs) have sparked growing panic among the softwareengineering community. Don’t give up on being a developer According to a 2019 report by the UK Office for National Statistics, softwareengineers face a 27.4%
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Can you compare images?
This means companies need loose coupling between app clients (model consumers) and model inference endpoints, which ensures easy switch among large language model (LLM), vision, or multi-modal endpoints if needed. This table will hold the endpoint, metadata, and configuration parameters for the model.
Topics Include: Advanced ML Algorithms & EnsembleMethods Hyperparameter Tuning & Model Optimization AutoML & Real-Time MLSystems Explainable AI & EthicalAI Time Series Forecasting & NLP Techniques Who Should Attend: ML Engineers, Data Scientists, and Technical Practitioners working on production-level ML solutions.
Administrators can check the metadata of a specific model using the hub.describe_model(model_name= ) command. model_id, version = "huggingface-llm-phi-2", "1.0.0" Bhaskar Pratap is a Senior SoftwareEngineer with the Amazon SageMaker team. client('sagemaker') sm_runtime_client = boto3.client('sagemaker-runtime')
MLOps , or Machine Learning Operations, is a multidisciplinary field that combines the principles of ML, softwareengineering, and DevOps practices to streamline the deployment, monitoring, and maintenance of ML models in production environments. What is MLOps?
Google built a new system called DIDACT (Dynamic Integrated Developer ACTivity), that trains a LLM for all of the software development activities. Libraries This repository includes datasets written by language models, used in their paper on "Discovering Language Model Behaviors with Model-Written Evaluations."
required=True, ) }, ), ] ), After the Amazon Bedrock agent determines the API operation that it needs to invoke in an action group, it sends information alongside relevant metadata as an input event to the Lambda function. With a softwareengineering background, he embraces infrastructure as code and is passionate about all things security.
Text to SQL: Using natural language to enhance query authoring SQL is a complex language that requires an understanding of databases, tables, syntaxes, and metadata. This adaptation is facilitated through the use of LLM prompts. To host your LLM as a SageMaker endpoint, you generate several artifacts.
Ali Arsanjani, director of cloud partner engineering at Google Cloud , presented a talk entitled “Challenges and Ethics of DLM and LLM Adoption in the Enterprise” at Snorkel AI’s recent Foundation Model Virtual Summit. Below follows a transcript of his talk, lightly edited for readability.
Ali Arsanjani, director of cloud partner engineering at Google Cloud , presented a talk entitled “Challenges and Ethics of DLM and LLM Adoption in the Enterprise” at Snorkel AI’s recent Foundation Model Virtual Summit. Below follows a transcript of his talk, lightly edited for readability.
This solution is also deployed by using the AWS Cloud Development Kit (AWS CDK), which is an open-source software development framework that defines cloud infrastructure in modern programming languages and provisions it through AWS CloudFormation. Domain-scoped agents enable code reuse across multiple agents.
Anthropic, an AI safety and research lab that builds reliable, interpretable, and steerable AI systems, is one of the leading AI companies that offers access to their state-of-the art LLM, Claude, on Amazon Bedrock. in SoftwareEngineering from the University of the West of England in Bristol, UK. Sandeep holds an MSc.
In this blog post, we provide an introduction to preparing your own dataset for LLM training. Whether your goal is to fine-tune a pre-trained modIn this blog post, we provide an introduction to preparing your own dataset for LLM training. The next step is to filter low quality or desirable documents.
This approach combines a retriever with an LLM to generate responses. Customers seek to build comprehensive generative AI systems that use this approach with their choice of index, LLMs, and other components. A retriever is responsible for finding relevant documents based on the user query.
The second script shows how to query those embeddings with an LLM for RAG-based Q&A. This quick workflow lets you maintain a powerful, scalable knowledge base for any LLM-powered application. The first script ingests text data, chunks it, creates embeddings, and writes them to Neo4j. This is for demonstration purposesonly! . """
This post explores how 123RF used Amazon Bedrock, Anthropic’s Claude 3 Haiku, and a vector store to efficiently translate content metadata, significantly reduce costs, and improve their global content discovery capabilities. Metadata such as the content type, domain, and any relevant tags. The corresponding translation chunk.
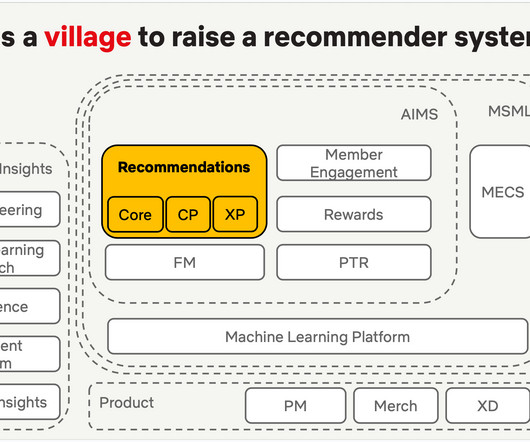
Industry is moving towards LLM as recsys rather than LLM for recsys and in the future, it is very possible that we might be using LLM as a recommender system overall. The ultimate goal is to make the world a happier and more fulfilling place through personalized recommendations.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content