This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Similar to how a customer service team maintains a bank of carefully crafted answers to frequently asked questions (FAQs), our solution first checks if a users question matches curated and verified responses before letting the LLM generate a new answer. No LLM invocation needed, response in less than 1 second.
However, traditional machine learning approaches often require extensive data-specific tuning and model customization, resulting in lengthy and resource-heavy development. Enter Chronos , a cutting-edge family of time series models that uses the power of large language model ( LLM ) architectures to break through these hurdles.
Consider a softwaredevelopment use case AI agents can generate, evaluate, and improve code, shifting software engineers focus from routine coding to more complex design challenges. Agentic systems, on the other hand, are designed to bridge this gap by combining the flexibility of context-aware systems with domain knowledge.
However, the industry is seeing enough potential to consider LLMs as a valuable option. The following are a few potential benefits: Improved accuracy and consistency LLMs can benefit from the high-quality translations stored in TMs, which can help improve the overall accuracy and consistency of the translations produced by the LLM.
For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security. The role information is also used to configure metadata filtering in the knowledge bases to generate relevant responses.
With this LLM, CreditAI was now able to respond better to broader, industry-wide queries than before. It also enables economies of scale with development velocity given that over 75 engineers at Octus already use AWS services for application development.
To scale ground truth generation and curation, you can apply a risk-based approach in conjunction with a prompt-based strategy using LLMs. Its important to note that LLM-generated ground truth isnt a substitute for use case SME involvement. To convert the source document excerpt into ground truth, we provide a base LLM prompt template.
It automatically keeps track of model artifacts, hyperparameters, and metadata, helping you to reproduce and audit model versions. The solution has three main steps: Write Python code to preprocess, train, and test an LLM in Amazon Bedrock. This streamlines the process and provides consistency across different stages of the pipeline.
This enables the Amazon Q large language model (LLM) to provide accurate, well-written answers by drawing from the consolidated data and information. Additionally, they want access to metadata, timestamps, and access control lists (ACLs) for the indexed documents. The following diagram shows a flowchart of a sync run job.
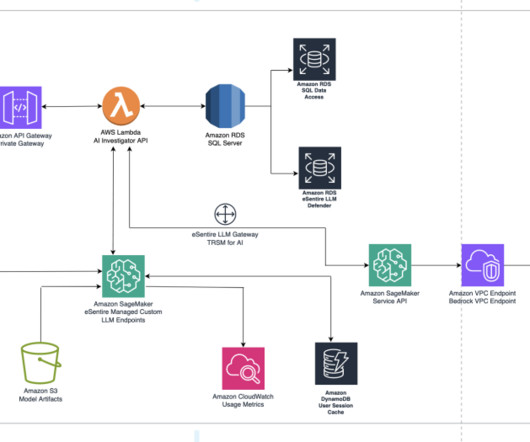
The LLM models augment SOC investigations with knowledge from eSentire’s security experts and security data, enabling higher-quality investigation outcomes while also reducing time to investigate. Therefore, eSentire decided to build their own LLM using Llama 1 and Llama 2 foundational models.
This approach is as important for fine-tuning Large Language Models internally as for projects where you only use LLM-as-a-service for the inference part (think of, e.g., using OpenAI API for calling GPT models). During training, we log all the model metrics and metadata automatically. Why are these elements so important?
The core work of developing a news story revolves around researching, writing, and editing the article. However, when the article is complete, supporting information and metadata must be defined, such as an article summary, categories, tags, and related articles. Storm CMS also gives journalists suggestions for article metadata.
Next, you need to index this data to make it available for a Retrieval Augmented Generation (RAG) approach, where relevant passages are delivered with high accuracy to a large language model (LLM). Amazon Q supports the crawling and indexing of these custom objects and custom metadata.
It’s developed by BAAI and is designed to enhance retrieval capabilities within large language models (LLMs). The model supports three retrieval methods: Dense retrieval (BGE-M3) Lexical retrieval (LLM Embedder) Multi-vector retrieval (BGE Embedding Reranker). The LLM processes the request and generates an appropriate response.
Training large language models (LLMs) models has become a significant expense for businesses. For many use cases, companies are looking to use LLM foundation models (FM) with their domain-specific data. However, companies are discovering that performing full fine tuning for these models with their data isnt cost effective.
The following are some of the experiments that were conducted by the team, along with the challenges identified and lessons learned: Pre-training – Q4 understood the complexity and challenges that come with pre-training an LLM using its own dataset. In addition to the effort involved, it would be cost prohibitive.
Next you need to index the data to make it available for a Retrieval Augmented Generation (RAG) approach where relevant passages are delivered with high accuracy to a large language model (LLM). In this example, metadata files including the ACLs are in a folder named Meta. For Frequency under Sync run schedule , choose Run on demand.
Prompt chaining – Generative AI developers often use prompt chaining techniques to break complex tasks into subtasks before sending them to an LLM. A centralized service that exposes APIs for common prompt-chaining architectures to your tenants can accelerate development.
Solution overview The LMA sample solution captures speaker audio and metadata from your browser-based meeting app (as of this writing, Zoom and Chime are supported), or audio only from any other browser-based meeting app, softphone, or audio source. You can also create your own custom prompts and corresponding options.
When the automated content processing steps are complete, you can use the output for downstream tasks, such as to invoke different components in a customer service backend application, or to insert the generated tags into metadata of each document for product recommendation. The LLM generates output based on the user prompt.
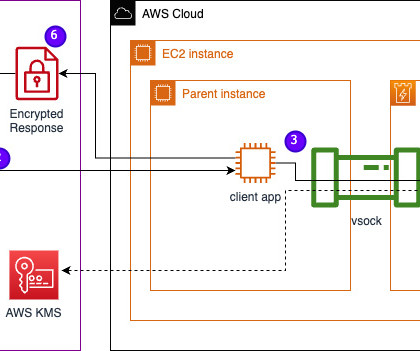
In this post, we discuss how Leidos worked with AWS to develop an approach to privacy-preserving large language model (LLM) inference using AWS Nitro Enclaves. LLMs are designed to understand and generate human-like language, and are used in many industries, including government, healthcare, financial, and intellectual property.
Large Language Models (LLMs) , another component of Speech AI, are powerful AI models that have a robust understanding of general-purpose language and communication. They are made even more accessible through LLM frameworks like LeMUR , which allow companies to easily build Generative AI audio analysis tools on top of spoken data.
The large machine learning (ML) model development lifecycle requires a scalable model release process similar to that of softwaredevelopment. Model developers often work together in developing ML models and require a robust MLOps platform to work in. ML Engineer at Tiger Analytics.
It’s built on diverse data sources and a robust infrastructure layer for data retrieval, prompting, and LLM management. This information is used to build a prompt with relevant context and then fed into an LLM, which generates a response. The final output is a response tailored to the input data and refined through iteration.
Next, you need to index this data to make it available for a Retrieval Augmented Generation (RAG) approach where relevant passages are delivered with high accuracy to a large language model (LLM). Amazon Q supports the crawling and indexing of these custom objects and custom metadata.
Gen AI in SoftwareDevelopment. Mabel Geronimo | Senior Solutions Engineer | GitHub Dive into the exciting world of AI-assisted development tools to explore the valuable lessons learned and common use cases observed by customers around the globe. What should you be looking for?
We have included a sample project to quickly deploy an Amazon Lex bot that consumes a pre-trained open-source LLM. This mechanism allows an LLM to recall previous interactions to keep the conversation’s context and pace. We also use LangChain, a popular framework that simplifies LLM-powered applications.
That being said, I humbly acknowledge that creating a software application is a very complex process and me not being a softwaredeveloper have only explored this at a surface level. All nuances of softwaredevelopment remain unexplored. Storing the data and metadata correctly is critical.
Next, you need to index this data to make it available for a Retrieval Augmented Generation (RAG) approach, where relevant passages are delivered with high accuracy to a large language model (LLM). Lakshmi Dogiparti is a is a SoftwareDevelopment Engineer at Amazon Web Services.
There is an increased demand in the job market for developers who are capable of adopting AI tools and willing to do so, with employers valuing the higher efficiency and enriched skill set that these individuals bring to the table. Instead of retreating to a corner, take the proactive route to understanding how these developing tools work.
This enables the Amazon Q large language model (LLM) to provide accurate, well-written answers by drawing from the consolidated data and information. Neelam Rana is a SoftwareDevelopment Engineer on the Amazon Q and Amazon Kendra engineering team. Outside of work, he enjoys running, playing tennis, and cooking.
These applications can generate answers based on your data or a large language model (LLM) knowledge. Each document has its own attributes, also known as metadata. Metadata can be mapped to fields in your Amazon Q Business index. The following table lists webpage metadata indexed by the Amazon Q Web Crawler connector.
Our paper reinforces the growing consensus that LLM-based AI tools such as ChatGPT and GitHub Copilot can now solve many of the small self-contained programming problems that are found in introductory classes. In sum, this is me trying to simulate the experience of relying as much as possible on ChatGPT to get this project done.
The resulting learned embeddings and associated metadata as features is then inputted to a survival model for predicting 10-year incidence of major adverse cardiac events. vLLM is a fast and easy-to-use library for LLM inference and serving. vLLM is a fast and easy-to-use library for LLM inference and serving.
This solution is also deployed by using the AWS Cloud Development Kit (AWS CDK), which is an open-source softwaredevelopment framework that defines cloud infrastructure in modern programming languages and provisions it through AWS CloudFormation.
of the SageMaker ACK Operators adds support for inference components , which until now were only available through the SageMaker API and the AWS SoftwareDevelopment Kits (SDKs). These controllers allow Kubernetes users to provision AWS resources like buckets, databases, or message queues simply by using the Kubernetes API.
While single models are suitable in some scenarios, acting as co-pilots, agentic architectures open the door for LLMs to become active components of business process automation. As such, enterprises should consider leveraging LLM-based multi-agent (LLM-MA) systems to streamline complex business processes and improve ROI.
This use case highlights how large language models (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning.
Sovereign Cloud, Generative AI Complying with regulations governing how data and metadata can be stored in cloud computing is critical. As a regional CSP, Scaleway also provides sovereign infrastructure that ensures access and compliance with EU data protection laws — critical to businesses with a European footprint.
For example, input images for an object detection use case might need to be resized or cropped before being served to a computer vision model, or tokenization of text inputs before being used in an LLM. The TargetModel parameter is what differentiates MMEs from single-model endpoints and enables us to direct the request to the right model.
In this blog post, we provide an introduction to preparing your own dataset for LLM training. Whether your goal is to fine-tune a pre-trained modIn this blog post, we provide an introduction to preparing your own dataset for LLM training. nAnswer: He is a softwaredeveloper, investor, and entrepreneur.
Requested information is intelligently fetched from multiple sources such as company product metadata, sales transactions, OEM reports, and more to generate meaningful responses. Vehicle specification data Amazon DynamoDB is used to store the vehicle metadata (its features and specifications).
As enterprises adopt generative AI, many are developing intelligent assistants powered by Retrieval Augmented Generation (RAG) to take advantage of information and knowledge from their enterprise data repositories. This approach combines a retriever with an LLM to generate responses.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content