This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In-context learning has emerged as an alternative, prioritizing the crafting of inputs and prompts to provide the LLM with the necessary context for generating accurate outputs. But the drawback for this is its reliance on the skill and expertise of the user in promptengineering.
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
Large language models (LLMs) have achieved remarkable success in various natural language processing (NLP) tasks, but they may not always generalize well to specific domains or tasks. You may need to customize an LLM to adapt to your unique use case, improving its performance on your specific dataset or task.
However, the industry is seeing enough potential to consider LLMs as a valuable option. The following are a few potential benefits: Improved accuracy and consistency LLMs can benefit from the high-quality translations stored in TMs, which can help improve the overall accuracy and consistency of the translations produced by the LLM.
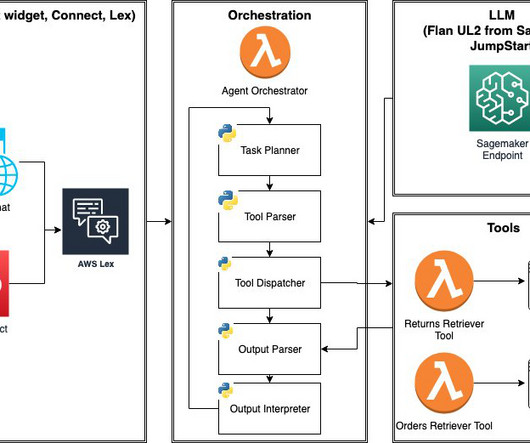
Large language model (LLM) agents are programs that extend the capabilities of standalone LLMs with 1) access to external tools (APIs, functions, webhooks, plugins, and so on), and 2) the ability to plan and execute tasks in a self-directed fashion. We conclude the post with items to consider before deploying LLM agents to production.
Evaluating large language models (LLMs) is crucial as LLM-based systems become increasingly powerful and relevant in our society. Rigorous testing allows us to understand an LLMs capabilities, limitations, and potential biases, and provide actionable feedback to identify and mitigate risk.
Introduction PromptEngineering is arguably the most critical aspect in harnessing the power of Large Language Models (LLMs) like ChatGPT. However; current promptengineering workflows are incredibly tedious and cumbersome. Logging prompts and their outputs to .csv First install the package via pip.
They used the metadata layer (schema information) over their data lake consisting of views (tables) and models (relationships) from their data reporting tool, Looker , as the source of truth. Refine your existing application using strategic methods such as promptengineering , optimizing inference parameters and other LookML content.
The personalization of LLM applications can be achieved by incorporating up-to-date user information, which typically involves integrating several components. Another essential component is an orchestration tool suitable for promptengineering and managing different type of subtasks. A feature store maintains user profile data.
Contrast that with Scope 4/5 applications, where not only do you build and secure the generative AI application yourself, but you are also responsible for fine-tuning and training the underlying large language model (LLM). LLM and LLM agent The LLM provides the core generative AI capability to the assistant.
Introduction to Large Language Models Difficulty Level: Beginner This course covers large language models (LLMs), their use cases, and how to enhance their performance with prompt tuning. It includes over 20 hands-on projects to gain practical experience in LLMOps, such as deploying models, creating prompts, and building chatbots.
Customizable Uses promptengineering , which enables customization and iterative refinement of the prompts used to drive the large language model (LLM), allowing for refining and continuous enhancement of the assessment process. Metadata filtering is used to improve retrieval accuracy.
The following are some of the experiments that were conducted by the team, along with the challenges identified and lessons learned: Pre-training – Q4 understood the complexity and challenges that come with pre-training an LLM using its own dataset. The context is finally used to augment the input prompt for a summarization step.
RAG enables LLMs to generate more relevant, accurate, and contextual responses by cross-referencing an organization’s internal knowledge base or specific domains, without the need to retrain the model. The embedding representations of text chunks along with related metadata are indexed in OpenSearch Service.
Evolving Trends in PromptEngineering for Large Language Models (LLMs) with Built-in Responsible AI Practices Editor’s note: Jayachandran Ramachandran and Rohit Sroch are speakers for ODSC APAC this August 22–23. Various prompting techniques, such as Zero/Few Shot, Chain-of-Thought (CoT)/Self-Consistency, ReAct, etc.
Operational efficiency Uses promptengineering, reducing the need for extensive fine-tuning when new categories are introduced. The raw data is processed by an LLM using a preconfigured user prompt. The LLM generates output based on the user prompt. The Step Functions workflow starts.
Large language models (LLMs) have exploded in popularity over the last few years, revolutionizing natural language processing and AI. From chatbots to search engines to creative writing aids, LLMs are powering cutting-edge applications across industries. Promptengineering is crucial to steering LLMs effectively.
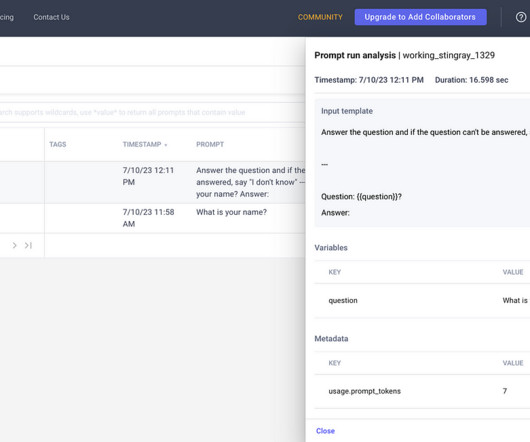
As promptengineering is fundamentally different from training machine learning models, Comet has released a new SDK tailored for this use case comet-llm. In this article you will learn how to log the YOLOPandas prompts with comet-llm, keep track of the number of tokens used in USD($), and log your metadata.
Inspect Rich Documents with Gemini Multimodality and Multimodal RAG This course covers using multimodal prompts to extract information from text and visual data and generate video descriptions with Gemini. Prompt Design in Vertex AI This course covers promptengineering, image analysis, and multimodal generative techniques in Vertex AI.
This post walks through examples of building information extraction use cases by combining LLMs with promptengineering and frameworks such as LangChain. We also examine the uplift from fine-tuning an LLM for a specific extractive task.
However, when the article is complete, supporting information and metadata must be defined, such as an article summary, categories, tags, and related articles. While these tasks can feel like a chore, they are critical to search engine optimization (SEO) and therefore the audience reach of the article.
TL;DR LangChain provides composable building blocks to create LLM-powered applications, making it an ideal framework for building RAG systems. makes it easy for RAG developers to track evaluation metrics and metadata, enabling them to analyze and compare different system configurations. Source What is LangChain? langchain-openai== 0.0.6
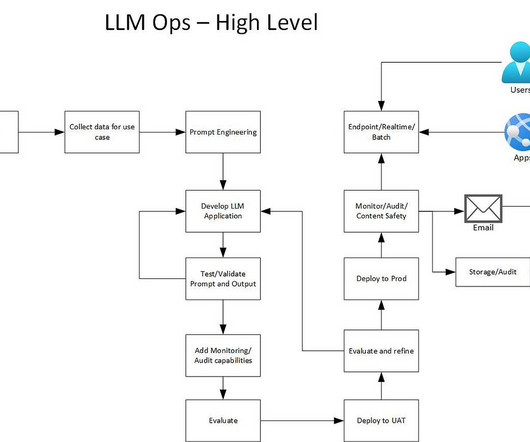
High level process and flow LLM Ops is people, process and technology. LLM Ops flow — Architecture Architecture explained. PromptEngineering — this is where figuring out what is the right prompt to use for the problem. Develop the LLM application using existing models or train a new model.
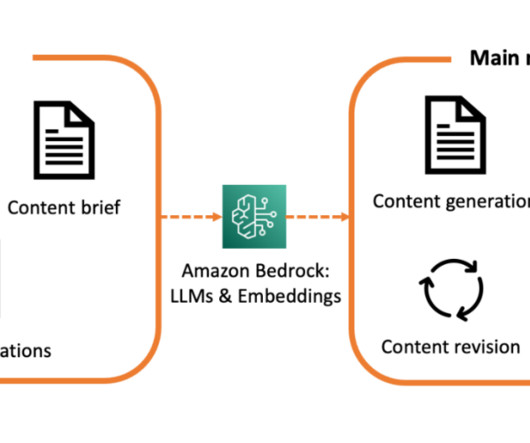
The system is built upon Amazon Bedrock and leverages LLM capabilities to generate curated medical content for disease awareness. This is accomplished through an automated revision functionality, which allows the user to interact and send instructions and comments directly to the LLM via an interactive feedback loop.
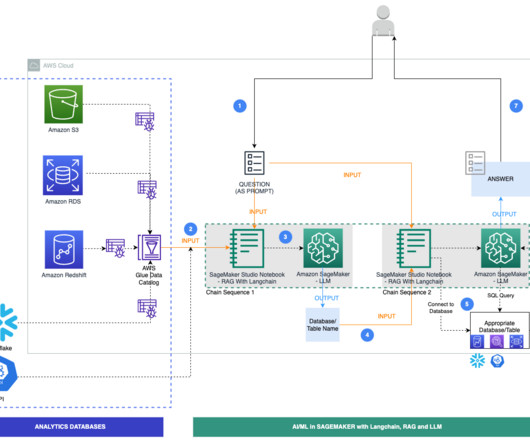
An AWS Glue crawler is scheduled to run at frequent intervals to extract metadata from databases and create table definitions in the AWS Glue Data Catalog. LangChain, a tool to work with LLMs and prompts, is used in Studio notebooks. LangChain requires an LLM to be defined.
Model training is only a small part of a typical machine learning project (source: own study) Of course, in the context of Large Language Models, we often talk about just fine tuning, few-shot learning or just promptengineering instead of a full training procedure. Why are these elements so important? monitoring and automation).
You can use LLMs in one or all phases of IDP depending on the use case and desired outcome. In this architecture, LLMs are used to perform specific tasks within the IDP workflow. Document classification – In addition to using Amazon Comprehend , you can use an LLM to classify documents using few-shot prompting.
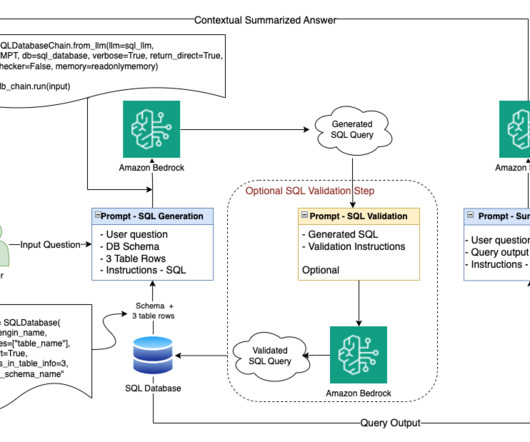
The workflow for NLQ consists of the following steps: A Lambda function writes schema JSON and table metadata CSV to an S3 bucket. The wrapper function reads the table metadata from the S3 bucket. The wrapper function creates a dynamic prompt template and gets relevant tables using Amazon Bedrock and LangChain.
Instead, Vitech opted for Retrieval Augmented Generation (RAG), in which the LLM can use vector embeddings to perform a semantic search and provide a more relevant answer to users when interacting with the chatbot. PromptengineeringPromptengineering is crucial for the knowledge retrieval system.
Used alongside other techniques such as promptengineering, RAG, and contextual grounding checks, Automated Reasoning checks add a more rigorous and verifiable approach to enhancing the accuracy of LLM-generated outputs. These methods, though fast, didnt provide a strong correlation with human evaluators.
It allows LLMs to reference authoritative knowledge bases or internal repositories before generating responses, producing output tailored to specific domains or contexts while providing relevance, accuracy, and efficiency. Generation is the process of generating the final response from the LLM.
It’s built on diverse data sources and a robust infrastructure layer for data retrieval, prompting, and LLM management. The following diagram illustrates the prompting framework for Account Summaries, which begins by gathering data from various sources. Role context – Start each prompt with a clear role definition.
LLMs don’t have straightforward automatic evaluation techniques. Therefore, human evaluation was required for insights generated by the LLM. Workflow details After the user inputs a query, a prompt is automatically created and then fed into a QA chatbot in which a response is outputted.
Articles Vgel wrote a blog post on the representation engineering, focusing on the control vector in LLMs. If you are interested and want to learn about AI safety and how to customize an already trained LLM, this post goes over couple of different ways of doing so. This is where metadata comes in.
You can use metadata filtering to narrow down search results by specifying inclusion and exclusion criteria. For a demonstration on how you can use a RAG evaluation framework in Amazon Bedrock to compute RAG quality metrics, refer to New RAG evaluation and LLM-as-a-judge capabilities in Amazon Bedrock.
The platform also offers features for hyperparameter optimization, automating model training workflows, model management, promptengineering, and no-code ML app development. When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support.
This article will discuss navigating the Comet LLMOps tool, the new LLM SDK, and much more. Comet LLMOps Comet’s LLMOps tools allow users to leverage the latest advancements in Prompt Management and query models in Comet to iterate quicker, identify performance bottlenecks, and visualize the internal state of the Prompt Chains.
.” – Carlos Rodriguez Abellan, Lead NLP Engineer at Fujitsu “The main obstacles to applying LLMs in my current projects include the cost of training and deploying LLM models, lack of data for some tasks, and the difficulty of interpreting and explaining the results of LLM models.” Unstructured.IO
This process creates a knowledge library that the LLM can understand. Post-Retrieval Next, the RAG model augments the user input (or prompts) by adding the relevant retrieved data in context (query + context). This step uses promptengineering techniques to communicate effectively with the LLM.
TL;DR LLMOps involves managing the entire lifecycle of Large Language Models (LLMs), including data and prompt management, model fine-tuning and evaluation, pipeline orchestration, and LLM deployment. Prompt-response management: Refining LLM-backed applications through continuous prompt-response optimization and quality control.
You’ll also be introduced to promptengineering, a crucial skill for optimizing AI interactions. You’ll explore data ingestion from multiple sources, preprocessing unstructured data into a normalized format that facilitates uniform chunking across various file types, and metadata extraction.
The recent rise of Large Language Models (LLMs) has been a game changer for the ChatBot industry. These LLM-based bots have found various applications in various industries and have become the go-to information source for many people. The most basic chain is the LLMChain, which combines the LLM, prompt, and optionally an output parser.
In this experiment, I’ll use Comet LLM to record prompts, responses, and metadata for each memory type for performance optimization purposes. Comet LLM provides additional features such as UI visualization, detailed chain execution logs, automatic tracking with OpenAI chat model, and user feedback analysis. .
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content