This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Last year, the DeepSeek LLM made waves with its impressive 67 billion parameters, meticulously trained on an expansive dataset of 2 trillion tokens in English and Chinese comprehension. Setting new benchmarks for research collaboration, DeepSeek ingrained the AI community by open-sourcing both its 7B/67B Base and Chat models.
It proposes a system that can automatically intervene to protect users from submitting personal or sensitive information into a message when they are having a conversation with a Large Language Model (LLM) such as ChatGPT. Remember Me? Three IBM-based reformulations that balance utility against data privacy.
Sonnet LLM, it’s here to shake the world of generative AI even more. Sonnet vs Grok 3: Which LLM is Better at Coding? Since last June, Anthropic has ruled over the coding benchmarks with its Claude 3.5 Today with its latest Claude 3.7 Both […] The post Claude 3.7 appeared first on Analytics Vidhya.
Speaker: Christophe Louvion, Chief Product & Technology Officer of NRC Health and Tony Karrer, CTO at Aggregage
In this exclusive webinar, Christophe will cover key aspects of his journey, including: LLM Development & Quick Wins 🤖 Understand how LLMs differ from traditional software, identifying opportunities for rapid development and deployment.
The LLM-as-a-Judge framework is a scalable, automated alternative to human evaluations, which are often costly, slow, and limited by the volume of responses they can feasibly assess. Here, the LLM-as-a-Judge approach stands out: it allows for nuanced evaluations on complex qualities like tone, helpfulness, and conversational coherence.
While others spend millions, NovaSky is proving […] The post Sky-T1: The $450 LLM Challenging GPT-4o & DeepSeek V3 appeared first on Analytics Vidhya. MeetSky-T1-32B-Previewa model that delivers top-tier performance for atraining cost of less than $450. Thats not a typo.
This breakdown will look into some of the tools that enable running LLMs locally, examining their features, strengths, and weaknesses to help you make informed decisions based on your specific needs. AnythingLLM AnythingLLM is an open-source AI application that puts local LLM power right on your desktop.
Integrating LLM agents into an organization requires thoughtful planning and […] The post Step-by-Step Guide to Integrate LLM Agents in an Organization appeared first on Analytics Vidhya. Organizations across sectors are now leveraging GenAI to streamline processes and increase the efficiency of their workforce.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation metrics for at-scale production guardrails.
Here, LLM benchmarks take center stage, providing systematic evaluations to measure a model’s skill in tasks like language […] The post 14 Popular LLM Benchmarks to Know in 2025 appeared first on Analytics Vidhya.
Gemini 2.0 – Which LLM to Use and When appeared first on Analytics Vidhya. With new models constantly emerging – each promising to outperform the last – its easy to feel overwhelmed. Dont worry, we are here to help you. This blog dives into three of the most […] The post GPT-4o, Claude 3.5,
Among these models, two different methods of language processing are represented by Base LLM and Instruction-Tuned LLM. This article examines the main distinctions between these two categories of models, as well as their training processes, […] The post Base LLM vs Instruction-Tuned LLM appeared first on Analytics Vidhya.
As LLMs continue to evolve, robust evaluation methodologies are crucial […] The post A Guide on Effective LLM Assessment with DeepEval appeared first on Analytics Vidhya.
Greg Loughnane and Chris Alexiuk in this exciting webinar to learn all about: How to design and implement production-ready systems with guardrails, active monitoring of key evaluation metrics beyond latency and token count, managing prompts, and understanding the process for continuous improvement Best practices for setting up the proper mix of open- (..)
In this article, we will examine how […] The post Fine-tuning an LLM to Write Like You on OpenAI Platform vs Google AI Studio appeared first on Analytics Vidhya. OpenAI and Google AI Studio are two major platforms offering tools for this purpose, each with distinct features and workflows.
model, demonstrating how cutting-edge AI technologies can streamline and enhance […] The post Build Production-Grade LLM-Powered Applications with PydanticAI appeared first on Analytics Vidhya.
Understanding LLM Evaluation Metrics is crucial for maximizing the potential of large language models. LLM evaluation Metrics help measure a models accuracy, relevance, and overall effectiveness using various benchmarks and criteria.
In this blog, we’ll explore exciting, new, and lesser-known features of the CrewAI framework by building […] The post Build LLM Agents on the Fly Without Code With CrewAI appeared first on Analytics Vidhya.
Speaker: Shreya Rajpal, Co-Founder and CEO at Guardrails AI & Travis Addair, Co-Founder and CTO at Predibase
Join Travis Addair, CTO of Predibase, and Shreya Rajpal, Co-Founder and CEO at Guardrails AI, in this exclusive webinar to learn: How guardrails can be used to mitigate risks and enhance the safety and efficiency of LLMs, delving into specific techniques and advanced control mechanisms that enable developers to optimize model performance effectively (..)
The full rollout for the Grok-2 and Grok-2 mini models is anticipated soon, promising enhancements in performance and efficiency […] The post How to Create a Social Media Writer Using xAI’s Grok LLM? appeared first on Analytics Vidhya.
The scale of LLM model sizes goes beyond mere technicality; it is an intrinsic property that determines what these AIs can do, how they will behave, and, in the end, how they will be useful to us.
With the apps, you can run various LLM models on your computer directly. Once the app is installed, youll download the LLM of your choice into it from an in-app menu. I chose to run DeepSeeks R1 model, but the apps support myriad open-source LLMs. But there are additional benefits to running LLMs locally on your computer, too.
Today, as discussions around Model Context Protocols (MCP) intensify, LLMs.txt is in the spotlight as a proven, AI-first documentation […] The post LLMs.txt Explained: The Web’s New LLM-Ready Content Standard appeared first on Analytics Vidhya.
Learn how you can bring your own LLM or SLM and enhance your application with embedded analytics and BI powered by Logi Symphony. Imagine having an AI tool that answers your user’s questions with a deep understanding of the context in their business and applications, nuances of their industry, and unique challenges they face.
However, a large amount of work has to be delivered to access the potential benefits of LLMs and build reliable products on top of these models. This work is not performed by machine learning engineers or software developers; it is performed by LLM developers by combining the elements of both with a new, unique skill set.
Ease of Integration : Groq offers both Python and OpenAI client SDKs, making it straightforward to integrate with frameworks like LangChain and LlamaIndex for building advanced LLM applications and chatbots. Real-Time Streaming : Enables streaming of LLM outputs, minimizing perceived latency and enhancing user experience.
For AI and large language model (LLM) engineers , design patterns help build robust, scalable, and maintainable systems that handle complex workflows efficiently. This article dives into design patterns in Python, focusing on their relevance in AI and LLM -based systems. BERT, GPT, or T5) based on the task.
The rapid adoption of Large Language Models (LLMs) in various industries calls for a robust framework to ensure their secure, ethical, and reliable deployment. Lets look at 20 essential guardrails designed to uphold security, privacy, relevance, quality, and functionality in LLM applications.
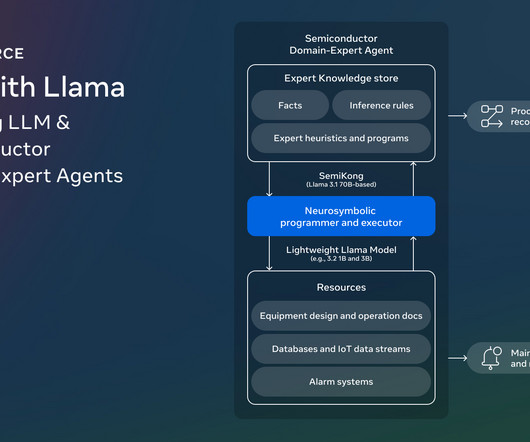
SemiKong represents the worlds first semiconductor-focused large language model (LLM), designed using the Llama 3.1 The post Meet SemiKong: The Worlds First Open-Source Semiconductor-Focused LLM appeared first on MarkTechPost. Trending: LG AI Research Releases EXAONE 3.5:
Multi-agent workflows allow you to split these tasks among different […] The post Multi-Agent LLM Workflow with LlamaIndex for Research & Writing appeared first on Analytics Vidhya. drafting vs. reviewing).
High Maintenance Costs: The current LLM improvement approach involves extensive human intervention, requiring manual oversight and costly retraining cycles. Enhanced Accuracy: A self-reflection mechanism can refine LLMs understanding over time. Reduced Training Costs: Self-reflecting AI can automate the LLM learning process.
The post Reducing AI Hallucinations with MoME: How Memory Experts Enhance LLM Accuracy appeared first on Unite.AI. With ongoing improvements and careful implementation, MoME has the potential to redefine how AI systems operate, paving the way for smarter, more efficient, and trustworthy AI solutions across industries.
Similar to how a customer service team maintains a bank of carefully crafted answers to frequently asked questions (FAQs), our solution first checks if a users question matches curated and verified responses before letting the LLM generate a new answer. No LLM invocation needed, response in less than 1 second.
So, there is a need for unified visualization solutions that can effectively illustrate diverse reasoning methodologies across the growing ecosystem of LLM providers and models. It supports sequential and tree-based reasoning methods while seamlessly integrating with major LLM providers and over fifty state-of-the-art models.
Evaluating large language models (LLMs) is crucial as LLM-based systems become increasingly powerful and relevant in our society. Rigorous testing allows us to understand an LLMs capabilities, limitations, and potential biases, and provide actionable feedback to identify and mitigate risk.
As these discoveries continue coming to light, the need to address LLM challenges only increases. How to Mitigate Common LLM Concerns Bias One of the most commonly discussed issues among LLMs is bias and fairness. In LLMs, bias is caused by data selection, creator demographics, and language or cultural skew.
Current memory systems for large language model (LLM) agents often struggle with rigidity and a lack of dynamic organization. In A-MEM, each interaction is recorded as a detailed note that includes not only the content and timestamp, but also keywords, tags, and contextual descriptions generated by the LLM itself.
Imagery Credit: Google Cloud ) See also: Alibaba Marco-o1: Advancing LLM reasoning capabilities Want to learn more about AI and big data from industry leaders? Check out AI & Big Data Expo taking place in Amsterdam, California, and London.
In this blog post, we explore a real-world scenario where a fictional retail store, AnyCompany Pet Supplies, leverages LLMs to enhance their customer experience. We will provide a brief introduction to guardrails and the Nemo Guardrails framework for managing LLM interactions. What is Nemo Guardrails?
Enter Chronos , a cutting-edge family of time series models that uses the power of large language model ( LLM ) architectures to break through these hurdles. Conclusion In this blog post, weve demonstrated how to use Amazon SageMaker AIOps features to deploy Chronos, a powerful time series forecasting model based on LLM architectures.
Avi Perez, CTO of Pyramid Analytics, explained that his business intelligence software’s AI infrastructure was deliberately built to keep data away from the LLM , sharing only metadata that describes the problem and interfacing with the LLM as the best way for locally-hosted engines to run analysis.”There’s
Fine-tuning involves training LLMs with domain-specific data, but this process is time-intensive and requires significant computational resources. Retrieval-augmented generation ( RAG ) retrieves external knowledge to guide LLM outputs, but it does not fully address challenges related to structured problem-solving.
OpenAI, a leading AI company, offers API keys for developers to interact with its platform and utilize its LLM models in various projects. In this article, you’ll learn how to create your own OpenAI API Key, updated as of 2024.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content