This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
LargeLanguageModels (LLMs) have shown remarkable capabilities across diverse natural language processing tasks, from generating text to contextual reasoning. Its sparse attention mechanism strikes a balance between computational demands and performance, making it an attractive solution for modern NLP tasks.
Evaluating NLPmodels has become increasingly complex due to issues like benchmark saturation, data contamination, and the variability in test quality. As interest in language generation grows, standard model benchmarking faces challenges from rapidly saturated evaluation datasets, where top models reach near-human performance levels.
Largelanguagemodels ( LLMs ) like GPT-4, PaLM, Bard, and Copilot have made a huge impact in natural language processing (NLP). These models require vast computational resources, making them expensive to train and deploy. The post What are Small LanguageModels (SLMs)?
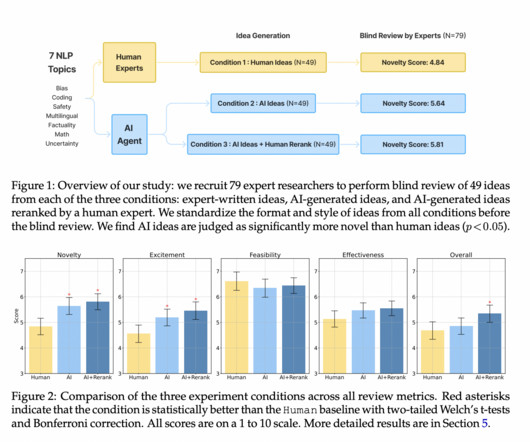
Largelanguagemodels (LLMs) have been applied to various research tasks, including experiment execution, automatic review generation, and related work curation. The experimental design compares an LLM ideation agent with expert NLP researchers, recruiting over 100 participants for idea generation and blind reviews.
The field of natural language processing (NLP) has grown rapidly in recent years, creating a pressing need for better datasets to train largelanguagemodels (LLMs). license, FineWeb 2 is accessible for both research and commercial applications, making it a versatile resource for the NLP community.
LargeLanguageModels (LLMs) excel in various tasks, including text generation, translation, and summarization. However, a growing challenge within NLP is how these models can effectively interact with external tools to perform tasks beyond their inherent capabilities.
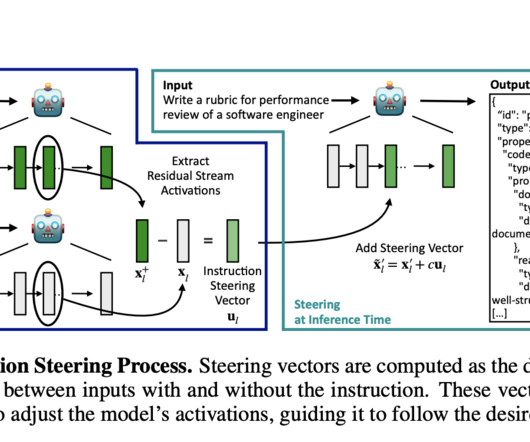
In recent years, largelanguagemodels (LLMs) have demonstrated significant progress in various applications, from text generation to question answering. However, one critical area of improvement is ensuring these models accurately follow specific instructions during tasks, such as adjusting format, tone, or content length.
Sarcasm detection is a critical challenge in natural language processing (NLP) because of sarcastic statements’ nuanced and often contradictory nature. Unlike straightforward language, sarcasm involves saying something that appears to convey one sentiment while implying the opposite.
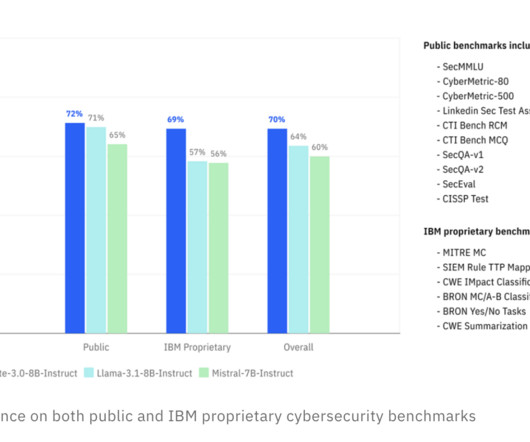
Largelanguagemodels (LLMs) have revolutionized natural language processing by offering sophisticated abilities for a range of applications. However, these models face significant challenges. The empirical analysis performed on two models—Llama-3-8B-Instruct and Mistral-7B-Instruct-v0.3—demonstrates
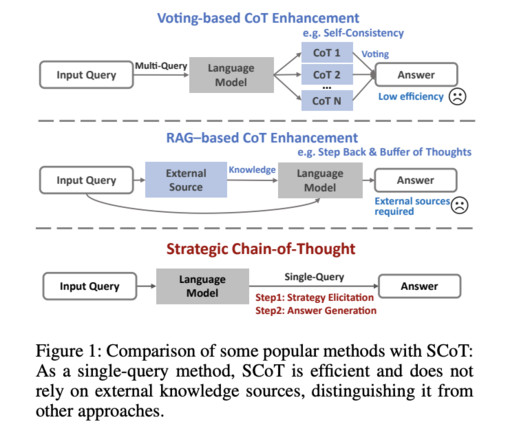
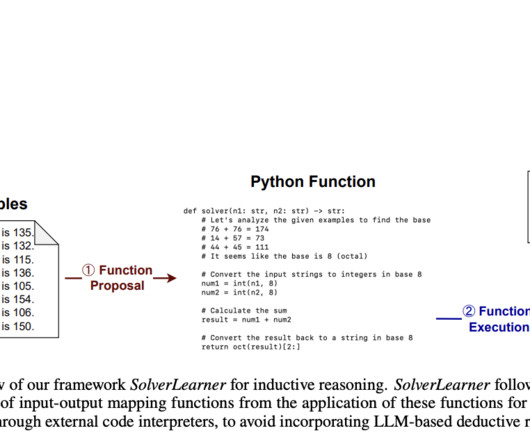
One important tactic for improving largelanguagemodels’ (LLMs’) capacity for reasoning is the Chain-of-Thought (CoT) paradigm. By encouraging models to divide tasks into intermediate steps, much like humans methodically approach complex problems, CoT improves the problem-solving process.
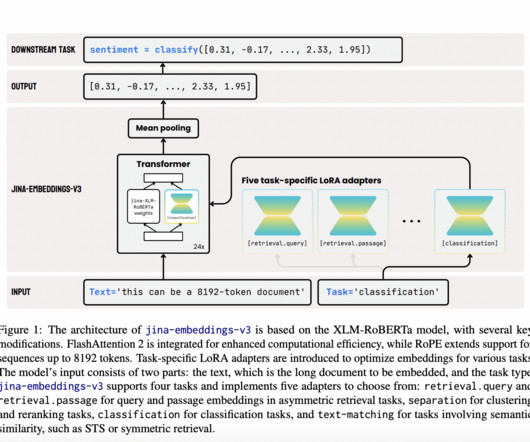
Text embedding models have become foundational in natural language processing (NLP). These models convert text into high-dimensional vectors that capture semantic relationships, enabling tasks like document retrieval, classification, clustering, and more. Check out the Paper and Model Card on HF.
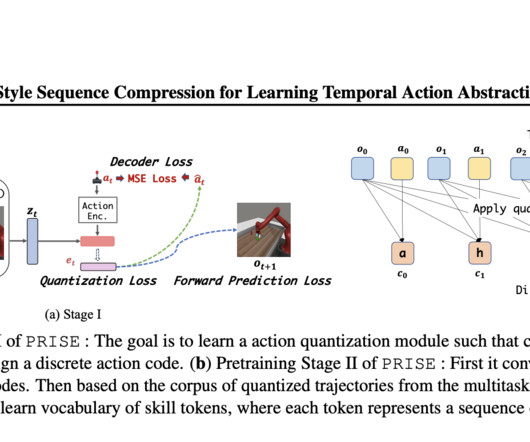
Largelanguagemodels’ (LLMs) training pipelines are the source of inspiration for this method in the field of natural language processing (NLP). This research suggests adapting BPE, which is commonly utilized in NLP, to the task of learning variable timespan abilities in continuous control domains.
Artificial intelligence (AI) and natural language processing (NLP) have seen significant advancements in recent years, particularly in the development and deployment of largelanguagemodels (LLMs). If you like our work, you will love our newsletter.
NuMind is an innovative tool designed to facilitate creation of custom natural language processing (NLP) models through an interactive teaching process. NuMind supports various NLP tasks, including classification, multilabel classification, named entity recognition (NER), and, soon, structured extraction.
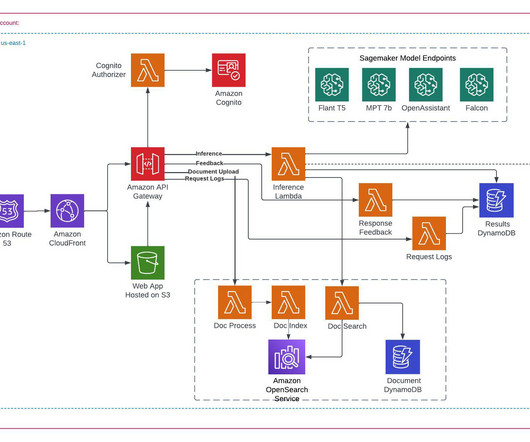
John Snow Labs , the award-winning Healthcare AI and NLP company, announced the latest major release of its Spark NLP library – Spark NLP 5 – featuring the highly anticipated support for the ONNX runtime. State-of-the-Art Accuracy, 100% Open Source The Spark NLPModels Hub now includes over 500 ONYX-optimized models.
Advancements in NLP have led to the development of largelanguagemodels (LLMs) capable of performing complex language-related tasks with high accuracy. A significant problem in NLP is the reliance on human annotations for model evaluation. The final model achieved 88.3 Check out the Paper.
Don’t Forget to join our 49k+ ML SubReddit Find Upcoming AI Webinars here The post RAGLAB: A Comprehensive AI Framework for Transparent and Modular Evaluation of Retrieval-Augmented Generation Algorithms in NLP Research appeared first on MarkTechPost. If you like our work, you will love our newsletter.
Largelanguagemodels (LLMs) have made significant leaps in natural language processing, demonstrating remarkable generalization capabilities across diverse tasks. However, due to inconsistent adherence to instructions, these models face a critical challenge in generating accurately formatted outputs, such as JSON.
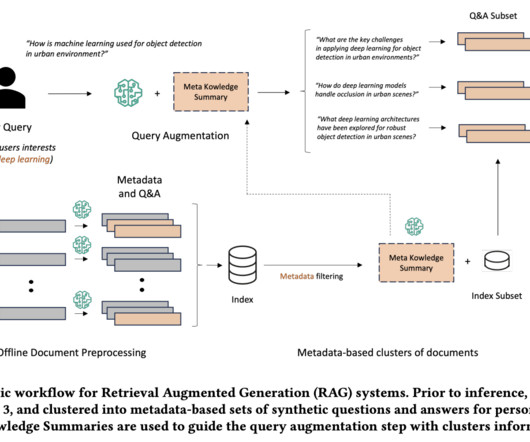
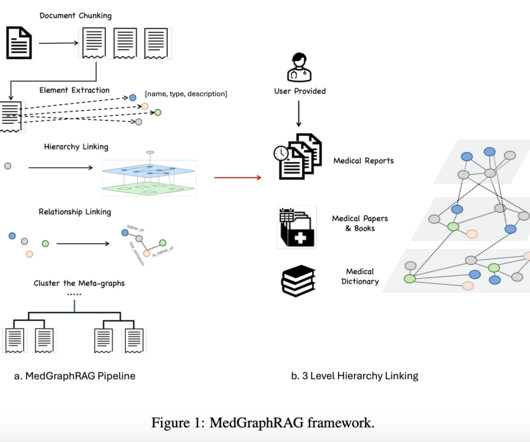
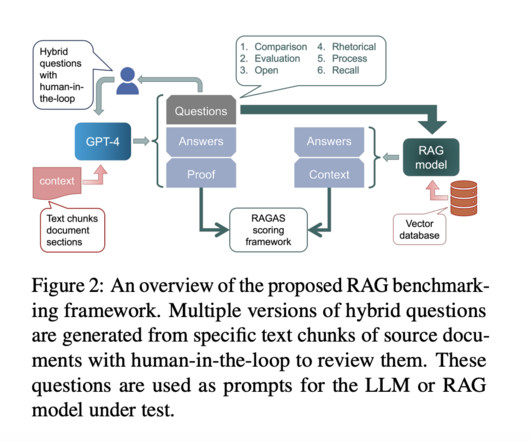
Retrieval Augmented Generation (RAG) represents a cutting-edge advancement in Artificial Intelligence, particularly in NLP and Information Retrieval (IR). This integration allows LLMs to perform more accurately and effectively in knowledge-intensive tasks, especially where proprietary or up-to-date information is crucial.
The recent development of largelanguagemodels (LLMs) has transformed the field of Natural Language Processing (NLP). LLMs show human-level performance in many professional and academic fields, showing a great understanding of language rules and patterns. If you like our work, you will love our newsletter.
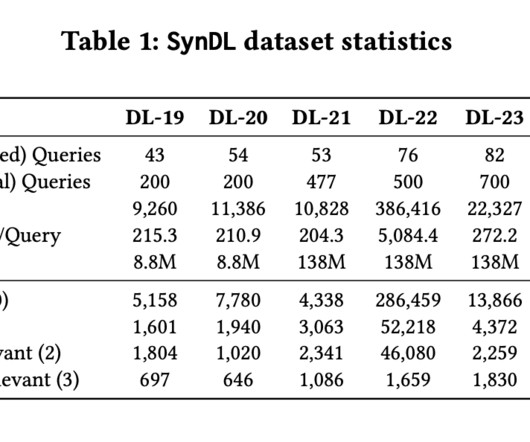
Recent developments in machine learning, particularly in natural language processing (NLP), have significantly enhanced the capabilities of IR systems. This significant imbalance highlights the difficulty in capturing the full complexity of query-document relationships, particularly in large datasets.
Thomson Reuters Labs, the company’s dedicated innovation team, has been integral to its pioneering work in AI and natural language processing (NLP). This technology was one of the first of its kind, using NLP for more efficient and natural legal research. A key milestone was the launch of Westlaw Is Natural (WIN) in 1992.
70b by Mobius Labs, boasting 70 billion parameters, has been designed to enhance the capabilities in natural language processing (NLP), image recognition, and data analysis. Mobius Labs, known for its cutting-edge innovations, has positioned this model as a cornerstone in the next generation of AI technologies. HQQ Llama-3.1-70b
In the rapidly evolving field of natural language processing (NLP), integrating external knowledge bases through Retrieval-Augmented Generation (RAG) systems represents a significant leap forward. These systems leverage dense retrievers to pull relevant information, which largelanguagemodels (LLMs) then utilize to generate responses.
This approach not only aids those directly involved in NLP research but also democratizes access to tools for large-scale model training, providing a valuable resource for those looking to experiment without overwhelming technical barriers. If you like our work, you will love our newsletter.
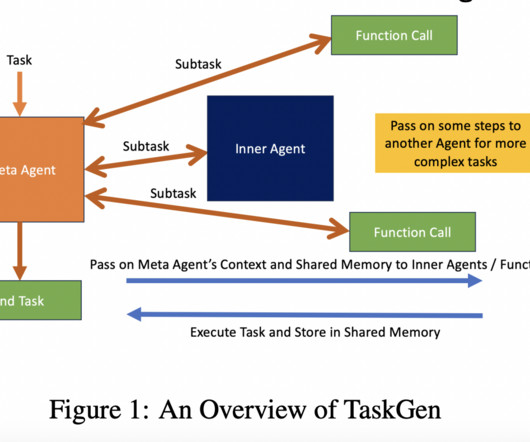
This research paper addresses the limitations of existing agentic frameworks in natural language processing (NLP) tasks, particularly the inefficiencies in handling dynamic and complex queries that require context refinement and interactive problem-solving. If you like our work, you will love our newsletter.
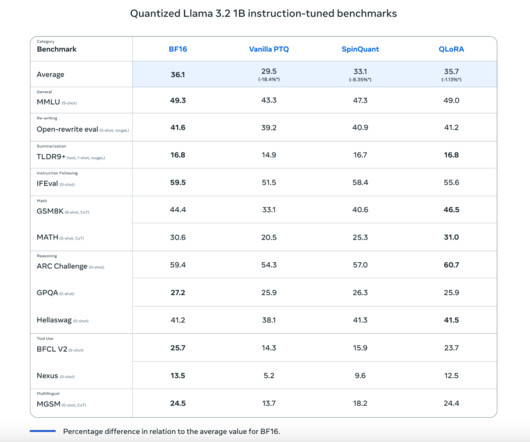
The rapid growth of largelanguagemodels (LLMs) has brought significant advancements across various sectors, but it has also presented considerable challenges. performs at approximately 95% of the full Llama 3 model’s effectiveness on key NLP benchmarks but with a reduction in memory usage by nearly 60%.
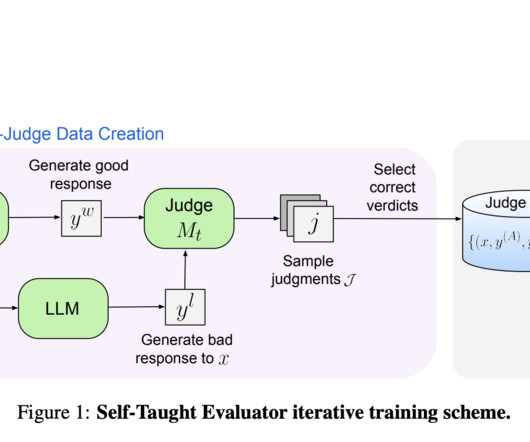
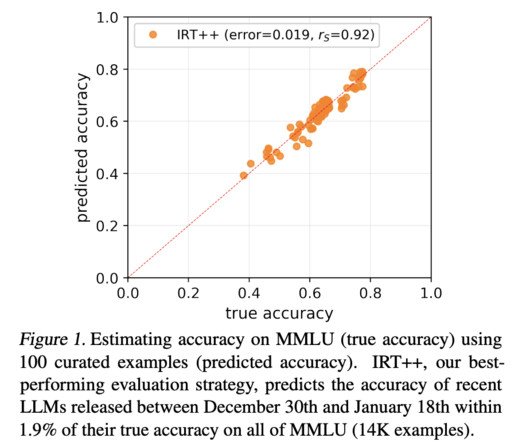
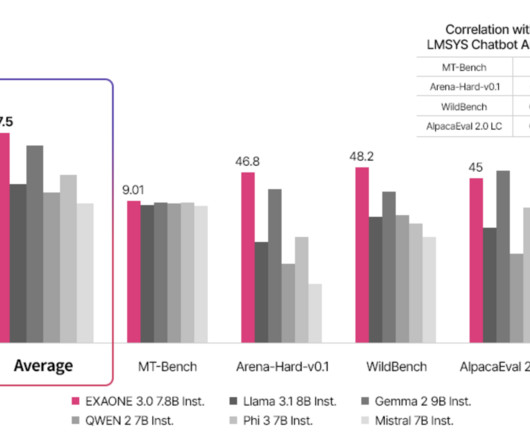
Largelanguagemodels (LLMs) have shown remarkable capabilities in NLP, performing tasks such as translation, summarization, and question-answering. The research provides a practical solution for frequent and efficient evaluation of LLMs, enabling continuous improvement in NLP technologies.
AI models are built upon largelanguagemodels (LLMs), designed specifically for enterprise AI applications. These include 8B and 2B parameter-dense decoder-only models, which outperformed similarly sized Llama-3.1 delivers powerful NLP features in a secure and transparent manner.
OpenAI’s decision to introduce the MMMLU dataset addresses this challenge by offering a robust, multilingual, and multitask dataset designed to assess the performance of largelanguagemodels (LLMs) on various tasks. MMMLU, in this regard, serves as a crucial benchmark for evaluating the real-world applicability of these models.
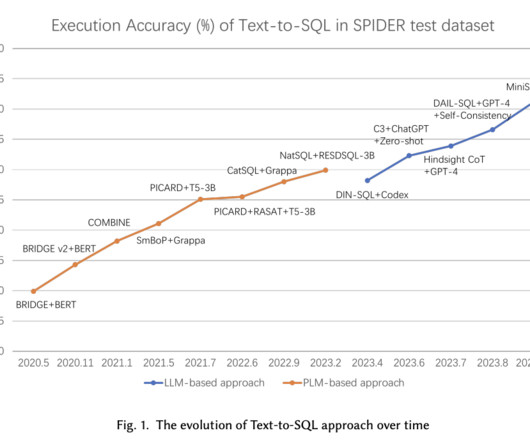
These models, enhanced by pre-trained languagemodels (PLMs), set the state-of-the-art in the field, benefiting from large-scale corpora to improve their linguistic capabilities. These LLMs, with their substantial number of parameters, can capture complex patterns in data, making them well-suited for the Text-to-SQL task.
Largelanguagemodels require large datasets of prompts paired with particular user requests and correct responses for training purposes. Conversely, unlike other languages, mainly Arabic, immense efforts have been made to develop such datasets in English. If you like our work, you will love our newsletter.
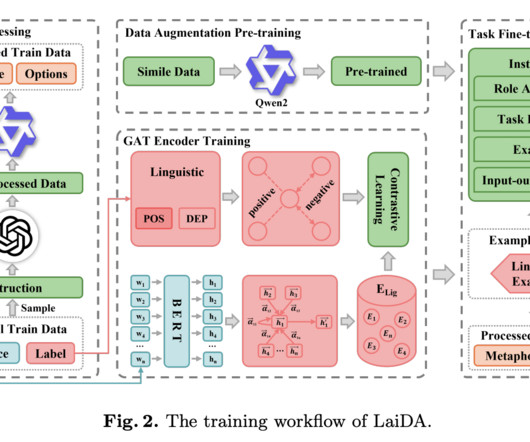
Metaphor Components Identification (MCI) is an essential aspect of natural language processing (NLP) that involves identifying and interpreting metaphorical elements such as tenor, vehicle, and ground. This framework leverages the power of largelanguagemodels (LLMs) like ChatGPT to improve the accuracy and efficiency of MCI.
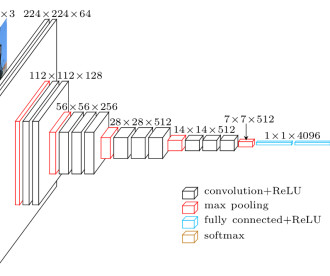
Largelanguagemodels (LLMs) have seen remarkable success in natural language processing (NLP). Large-scale deep learning models, especially transformer-based architectures, have grown exponentially in size and complexity, reaching billions to trillions of parameters.
LargeLanguageModels (LLMs), like ChatGPT and GPT-4 from OpenAI, are advancing significantly and transforming the field of Natural Language Processing (NLP) and Natural Language Generation (NLG), thus paving the way for the creation of a plethora of Artificial Intelligence (AI) applications indispensable to daily life.
Question answering (QA) is a crucial area in natural language processing (NLP), focusing on developing systems that can accurately retrieve and generate responses to user queries from extensive data sources. This limitation hampers evaluating how well LLMs can generalize across different domains. Check out the Paper.
Natural Language Processing (NLP) has seen remarkable advancements, particularly in text generation techniques. As NLP continues to evolve, integrating RAG has become increasingly important for generating reliable and contextually accurate outputs in these complex domains. If you like our work, you will love our newsletter.
The release as an open-source largelanguagemodel is unique to the current version with great results and 7.8B introduces advanced natural language processing (NLP) capabilities. The AI’s ability to identify patterns and trends in large datasets can provide financial institutions with deeper insights.
The Top LargeLanguageModels of 2023, 8 Python Libraries You Should be Using, and Why You Need an Observability Platform The Top LargeLanguageModels Going Into 2024 Let’s explore the top largelanguagemodels that made waves in 2023, and see why you should be using these LLMs in 2024.
With the development of huge LargeLanguageModels (LLMs), such as GPT-3 and GPT-4, Natural Language Processing (NLP) has developed incredibly in recent years. Based on their unusual reasoning capabilities, these models can understand and generate human-like text. Check out the Paper.
Largelanguagemodels (LLMs) have become the backbone of many AI systems, contributing significantly to advancements in natural language processing (NLP), computer vision, and even scientific research. However, these models come with their own set of challenges. 70B and LLama3.1-405B.
Text embedding, a central focus within natural language processing (NLP), transforms text into numerical vectors capturing the essential meaning of words or phrases. These embeddings enable machines to process language tasks like classification, clustering, retrieval, and summarization. in classification tasks, 49.3
Considering the major influence of autoregressive ( AR ) generative models, such as LargeLanguageModels in natural language processing ( NLP ), it’s interesting to explore whether similar approaches can work for images. If you like our work, you will love our newsletter.
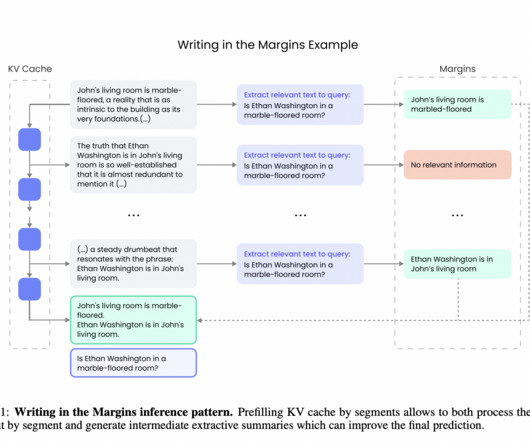
In natural language processing (NLP), handling long text sequences effectively is a critical challenge. Traditional transformer models, widely used in largelanguagemodels (LLMs), excel in many tasks but must be improved when processing lengthy inputs. If you like our work, you will love our newsletter.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















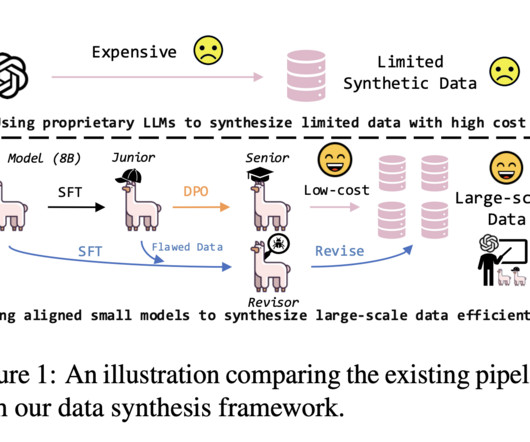
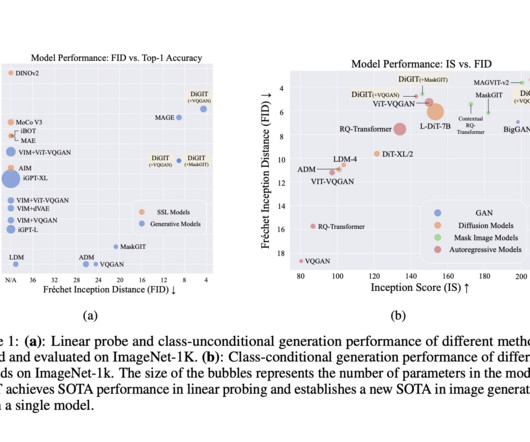
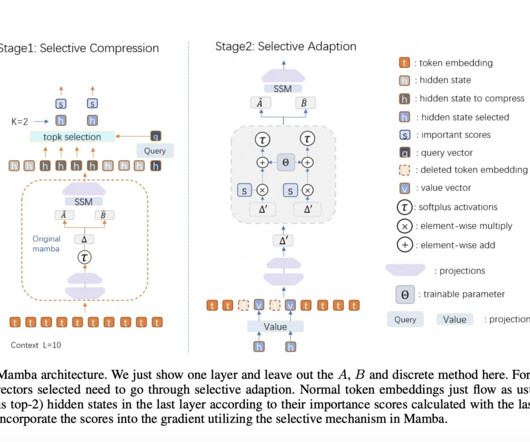






Let's personalize your content