This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
LargeLanguageModels (LLMs) have shown remarkable capabilities across diverse naturallanguageprocessing tasks, from generating text to contextual reasoning. The post SepLLM: A Practical AI Approach to Efficient Sparse Attention in LargeLanguageModels appeared first on MarkTechPost.
Recent benchmarks from Hugging Face, a leading collaborative machine-learning platform, position Qwen at the forefront of open-source largelanguagemodels (LLMs). The technical edge of Qwen AI Qwen AI is attractive to Apple in China because of the former’s proven capabilities in the open-source AI ecosystem.
Researchers at Amazon have trained a new largelanguagemodel (LLM) for text-to-speech that they claim exhibits “emergent” abilities. The 980 million parameter model, called BASE TTS, is the largest text-to-speech model yet created.
Largelanguagemodels ( LLMs ) like GPT-4, PaLM, Bard, and Copilot have made a huge impact in naturallanguageprocessing (NLP). These models require vast computational resources, making them expensive to train and deploy. The post What are Small LanguageModels (SLMs)?
LargeLanguageModels (LLMs) have revolutionized naturallanguageprocessing, demonstrating remarkable capabilities in various applications. Transformer architecture has emerged as a major leap in naturallanguageprocessing, significantly outperforming earlier recurrent neural networks.
Prior research on LargeLanguageModels (LLMs) demonstrated significant advancements in fluency and accuracy across various tasks, influencing sectors like healthcare and education. This progress sparked investigations into LLMs’ language understanding capabilities and associated risks.
Largelanguagemodels’ (LLMs) training pipelines are the source of inspiration for this method in the field of naturallanguageprocessing (NLP). Tokenizing input is a crucial part of LLM training, and it’s commonly accomplished using byte pair encoding (BPE).
LargeLanguageModels (LLMs) have demonstrated remarkable capabilities in various naturallanguageprocessing tasks. However, they face a significant challenge: hallucinations, where the models generate responses that are not grounded in the source material.
Multimodal largelanguagemodels (MLLMs) focus on creating artificial intelligence (AI) systems that can interpret textual and visual data seamlessly. The NVLM-H model, in particular, strikes a balance between image processing efficiency and multimodal reasoning accuracy, making it one of the most promising models in this field.
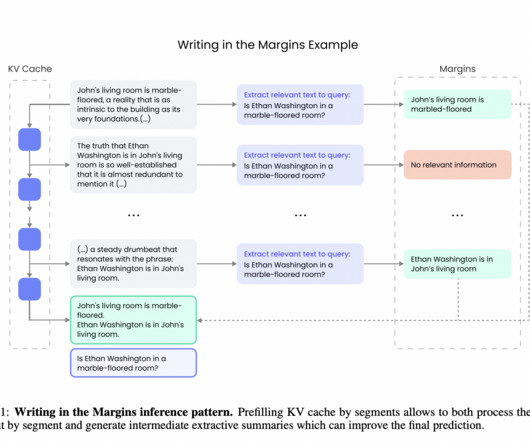
In artificial intelligence and naturallanguageprocessing, long-context reasoning has emerged as a crucial area of research. As the volume of information that needs to be processed grows, machines must be able to synthesize and extract relevant data from massive datasets efficiently.
Largelanguagemodels (LLMs) have gained significant attention due to their potential to enhance various artificial intelligence applications, particularly in naturallanguageprocessing. In conclusion, this research addresses a critical issue in deploying largelanguagemodels in real-world applications.
Decentralised AI systems built on blockchains can help to democratise access to essential AI resources like computing power, data, and largelanguagemodels. They are sorely needed too; as AI models become more powerful, their thirst for data and computing power grows, increasing the barrier of entry to the industry.
The field of naturallanguageprocessing (NLP) has grown rapidly in recent years, creating a pressing need for better datasets to train largelanguagemodels (LLMs). Existing resources like CC-100, mC4, CulturaX, and HPLT provide useful starting points but come with notable drawbacks.
The effectiveness of RAG heavily depends on the quality of context provided to the largelanguagemodel (LLM), which is typically retrieved from vector stores based on user queries. The relevance of this context directly impacts the model’s ability to generate accurate and contextually appropriate responses.
Recent advancements in LargeLanguageModels (LLMs) have reshaped the Artificial intelligence (AI)landscape, paving the way for the creation of Multimodal LargeLanguageModels (MLLMs). If you like our work, you will love our newsletter. Don’t Forget to join our 50k+ ML SubReddit.
Sarcasm detection is a critical challenge in naturallanguageprocessing (NLP) because of sarcastic statements’ nuanced and often contradictory nature. Unlike straightforward language, sarcasm involves saying something that appears to convey one sentiment while implying the opposite.
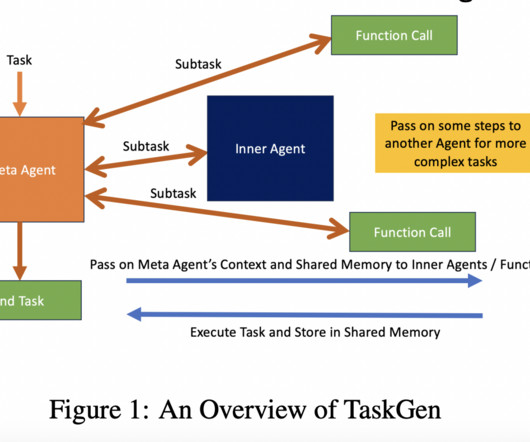
Largelanguagemodels (LLMs) have revolutionized naturallanguageprocessing by offering sophisticated abilities for a range of applications. However, these models face significant challenges. Modulizing LLMs into functional bricks optimizes computational efficiency, scalability, and flexibility.
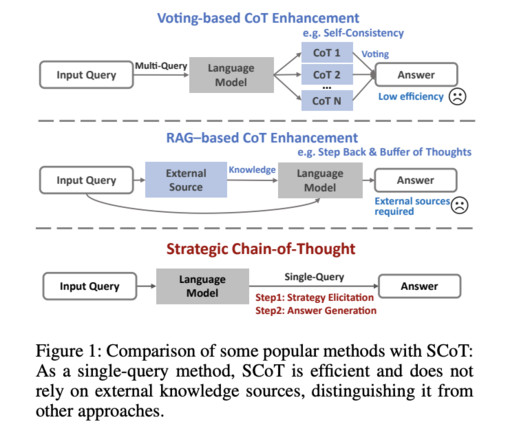
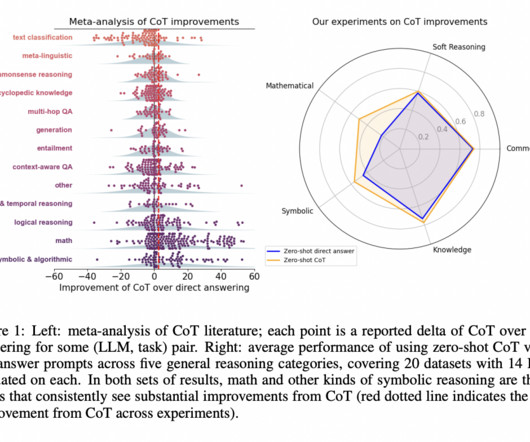
One important tactic for improving largelanguagemodels’ (LLMs’) capacity for reasoning is the Chain-of-Thought (CoT) paradigm. By encouraging models to divide tasks into intermediate steps, much like humans methodically approach complex problems, CoT improves the problem-solving process.
Artificial intelligence (AI) and naturallanguageprocessing (NLP) have seen significant advancements in recent years, particularly in the development and deployment of largelanguagemodels (LLMs). If you like our work, you will love our newsletter.
The recent development of largelanguagemodels (LLMs) has transformed the field of NaturalLanguageProcessing (NLP). LLMs show human-level performance in many professional and academic fields, showing a great understanding of language rules and patterns.
In the rapidly evolving field of naturallanguageprocessing (NLP), integrating external knowledge bases through Retrieval-Augmented Generation (RAG) systems represents a significant leap forward. Don’t Forget to join our 47k+ ML SubReddit Find Upcoming AI Webinars here The post Is the Future of Agentic AI Personal?
70b by Mobius Labs, boasting 70 billion parameters, has been designed to enhance the capabilities in naturallanguageprocessing (NLP), image recognition, and data analysis. Mobius Labs, known for its cutting-edge innovations, has positioned this model as a cornerstone in the next generation of AI technologies.
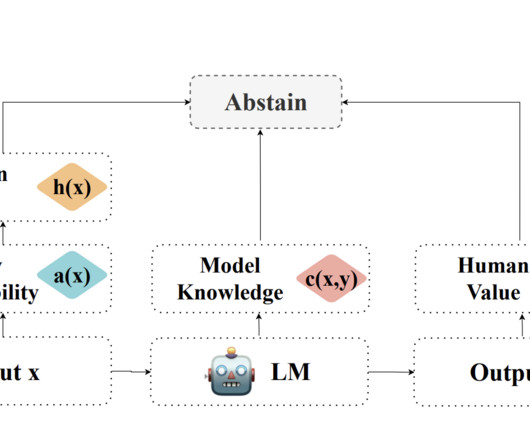
Prior work on abstention in largelanguagemodels (LLMs) has made significant strides in query processing, answerability assessment, and handling misaligned queries. They present a framework analyzing abstention from the query, model, and human value perspectives.
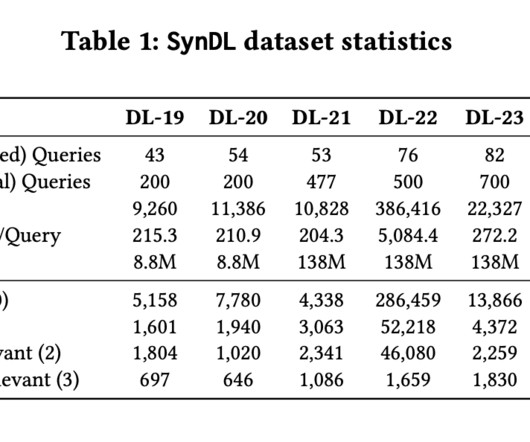
Recent developments in machine learning, particularly in naturallanguageprocessing (NLP), have significantly enhanced the capabilities of IR systems. This significant imbalance highlights the difficulty in capturing the full complexity of query-document relationships, particularly in large datasets.
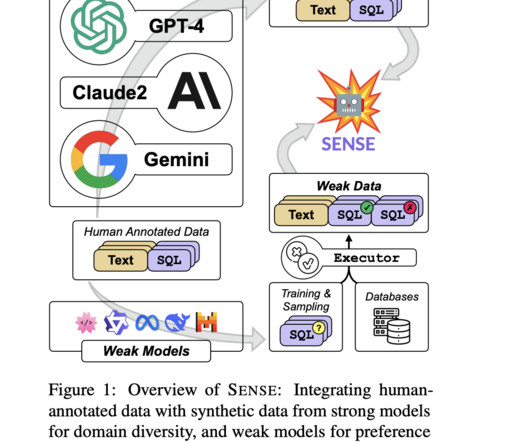
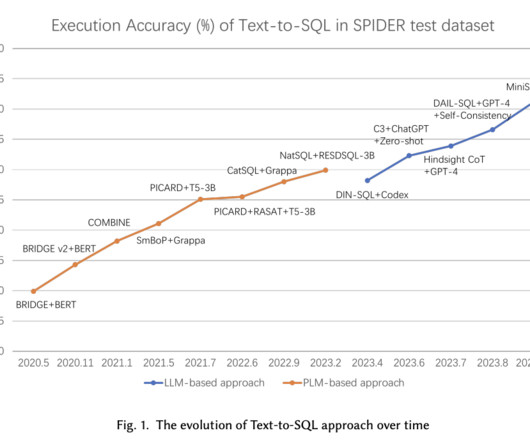
Recent studies have highlighted significant achievements in powerful closed-source largelanguagemodels (LLMs) like GPT-4, which use advanced prompting techniques. This method enhances domain generalization in text-to-SQL models and explores the potential of using weak data supervision through preference learning.
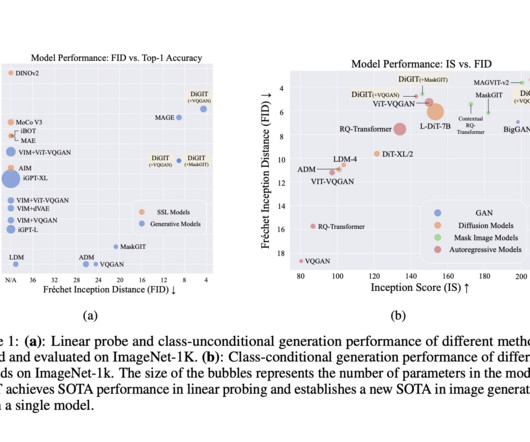
Considering the major influence of autoregressive ( AR ) generative models, such as LargeLanguageModels in naturallanguageprocessing ( NLP ), it’s interesting to explore whether similar approaches can work for images. If you like our work, you will love our newsletter.
The rise of Transformer-based models has significantly advanced the field of naturallanguageprocessing. However, the training of these models is often computationally intensive, requiring substantial resources and time. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
This research paper addresses the limitations of existing agentic frameworks in naturallanguageprocessing (NLP) tasks, particularly the inefficiencies in handling dynamic and complex queries that require context refinement and interactive problem-solving. If you like our work, you will love our newsletter.
Chain-of-thought (CoT) prompting has emerged as a popular technique to enhance largelanguagemodels’ (LLMs) problem-solving abilities by generating intermediate steps. Despite its better performance in mathematical reasoning, CoT’s effectiveness in other domains remains questionable. Check out the Paper.
These models, enhanced by pre-trained languagemodels (PLMs), set the state-of-the-art in the field, benefiting from large-scale corpora to improve their linguistic capabilities. These LLMs, with their substantial number of parameters, can capture complex patterns in data, making them well-suited for the Text-to-SQL task.
Thomson Reuters Labs, the company’s dedicated innovation team, has been integral to its pioneering work in AI and naturallanguageprocessing (NLP). A key milestone was the launch of Westlaw Is Natural (WIN) in 1992. This technology was one of the first of its kind, using NLP for more efficient and natural legal research.
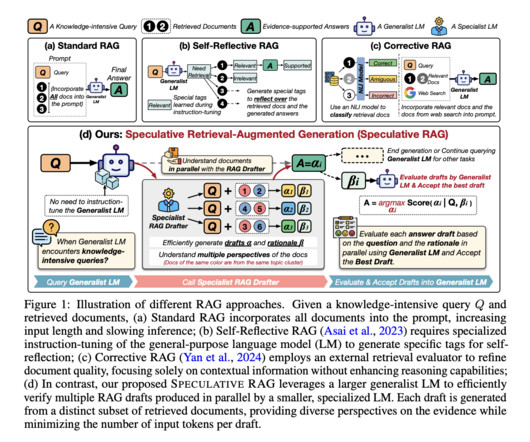
The field of naturallanguageprocessing has made substantial strides with the advent of LargeLanguageModels (LLMs), which have shown remarkable proficiency in tasks such as question answering. However, despite their success, LLMs need help dealing with knowledge-intensive queries.
LargeLanguageModels (LLMs), like ChatGPT and GPT-4 from OpenAI, are advancing significantly and transforming the field of NaturalLanguageProcessing (NLP) and NaturalLanguage Generation (NLG), thus paving the way for the creation of a plethora of Artificial Intelligence (AI) applications indispensable to daily life.
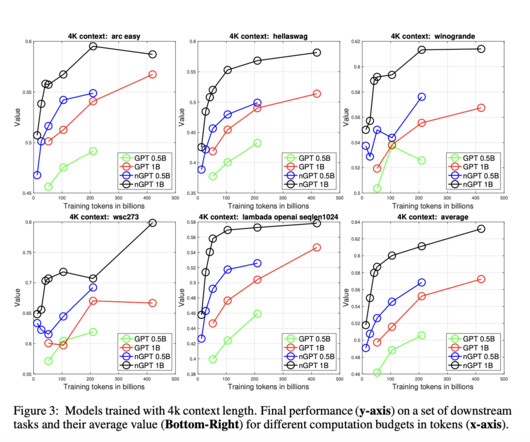
In naturallanguageprocessing (NLP), handling long text sequences effectively is a critical challenge. Traditional transformer models, widely used in largelanguagemodels (LLMs), excel in many tasks but must be improved when processing lengthy inputs. Check out the Paper.
Largelanguagemodels (LLMs) are used in various applications, such as machine translation, summarization, and content creation. These hallucinations can manifest as incorrect facts or misrepresentations, impacting the model’s utility in sensitive applications. If you like our work, you will love our newsletter.
Largelanguagemodels (LLMs) like GPT-4, Gemini, and Llama 3 have revolutionized naturallanguageprocessing through extensive pre-training and supervised fine-tuning (SFT). However, these models come with high computational costs for training and inference.
LargeLanguageModels (LLMs) have achieved remarkable progress in the ever-expanding realm of artificial intelligence, revolutionizing naturallanguageprocessing and interaction. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
Recent advances in Artificial Intelligence and Machine Learning have made tremendous progress in handling many computing jobs possible, especially with the introduction of LargeLanguageModels (LLMs). Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
AI models are built upon largelanguagemodels (LLMs), designed specifically for enterprise AI applications. These include 8B and 2B parameter-dense decoder-only models, which outperformed similarly sized Llama-3.1 2B and 8B AI Models for AI Enterprises appeared first on MarkTechPost.
Largelanguagemodels (LLMs) have made significant leaps in naturallanguageprocessing, demonstrating remarkable generalization capabilities across diverse tasks. This study introduces Sketch , a significant advancement in simplifying and optimizing the applications of largelanguagemodels.
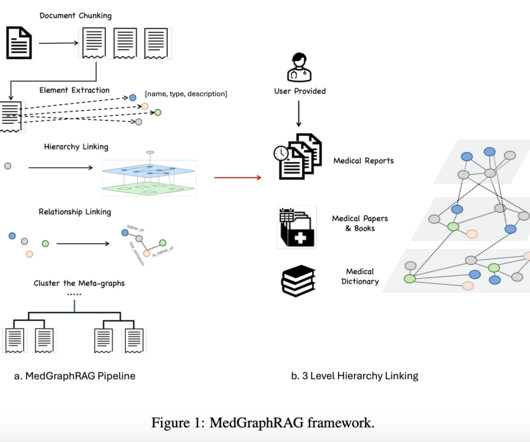
These graphs map entities and their relationships in a structured form, which is useful for applications like reasoning, information retrieval, and naturallanguageprocessing. On the other hand, neural systems, particularly LargeLanguageModels (LLMs), offer expansive knowledge through deep learning.
Generative Artificial Intelligence (GenAI), particularly largelanguagemodels (LLMs) like ChatGPT, has revolutionized the field of naturallanguageprocessing (NLP). Their ability to generate human-like text stems from training on vast datasets and leveraging deep learning architectures.
Question answering (QA) is a crucial area in naturallanguageprocessing (NLP), focusing on developing systems that can accurately retrieve and generate responses to user queries from extensive data sources. This limitation hampers evaluating how well LLMs can generalize across different domains.
These findings highlight the impact of model size on RAG performance and provide valuable insights for naturallanguageprocessing research. By providing a standardized approach for assessment and a platform for innovation, RAGLAB is poised to become an essential tool for naturallanguageprocessing researchers.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content