This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
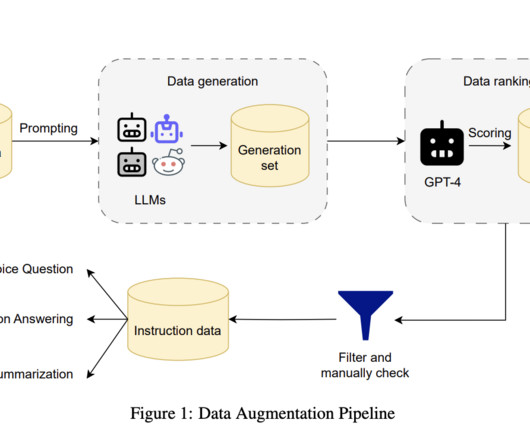
LargeLanguageModels (LLMs) have shown remarkable capabilities across diverse natural language processing tasks, from generating text to contextual reasoning. Dont Forget to join our 60k+ ML SubReddit. However, their efficiency is often hampered by the quadratic complexity of the self-attention mechanism.
As we approach a new year filled with potential, the landscape of technology, particularly artificial intelligence (AI) and machine learning (ML), is on the brink of significant transformation. Explore other upcoming enterprise technology events and webinars powered by TechForge here.
Don’t Forget to join our 55k+ ML SubReddit. FREE AI WEBINAR ] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions – From Framework to Production The post LogLLM: Leveraging LargeLanguageModels for Enhanced Log-Based Anomaly Detection appeared first on MarkTechPost.
LLM Agents Learning Platform A unique course focusing on leveraging largelanguagemodels (LLMs) to create advanced AI agents for diverse applications. Also, dont forget to join our 60k+ ML SubReddit. Dont forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
LargeLanguageModels (LLMs), such as the ByT5 model, offer a promising potential for enhancing OCR post-correction. These models are trained on extensive text data and can understand and generate human-like language. If you like our work, you will love our newsletter.
Hebrew University Researchers addressed the challenge of understanding how information flows through different layers of decoder-based largelanguagemodels (LLMs). Current LLMs, such as transformer-based models, use the attention mechanism to process tokens by attending to all previous tokens in every layer.
Utilizing LargeLanguageModels (LLMs) through different prompting strategies has become popular in recent years. Differentiating prompts in multi-turn interactions, which involve several exchanges between the user and model, is a crucial problem that remains mostly unresolved.
One of Databricks’ notable achievements is the DBRX model, which set a new standard for open largelanguagemodels (LLMs). “Upon release, DBRX outperformed all other leading open models on standard benchmarks and has up to 2x faster inference than models like Llama2-70B,” Everts explains. .”
LargeLanguageModels (LLMs) are a subset of artificial intelligence focusing on understanding and generating human language. These models leverage complex architectures to comprehend and produce human-like text, facilitating applications in customer service, content creation, and beyond.
LargeLanguageModels (LLMs) have revolutionized natural language processing, demonstrating remarkable capabilities in various applications. Fine-tuning techniques enhance LargeLanguageModels’ performance for specific tasks. If you like our work, you will love our newsletter.
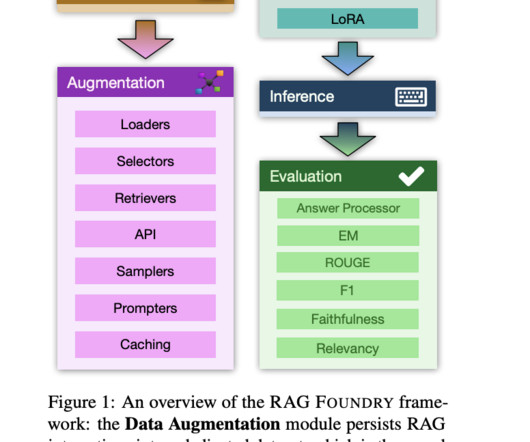
Proposed frameworks for RAG-based largelanguagemodels (LLMs) omitted crucial training components. Novel approaches, such as treating LLM prompting as a programming language, emerged but introduced complexity. Evaluation methodologies using synthetic data and LLM critics were developed to assess RAG performance.
Prior research on LargeLanguageModels (LLMs) demonstrated significant advancements in fluency and accuracy across various tasks, influencing sectors like healthcare and education. This progress sparked investigations into LLMs’ language understanding capabilities and associated risks.
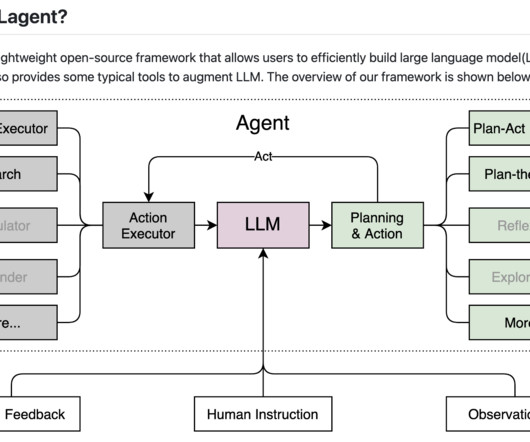
Introducing Lagent, a new open-source framework that simplifies the process of building largelanguagemodel (LLM)-based agents. Lagent stands out by offering a lightweight and flexible solution that supports various models and provides tools to enhance the capabilities of LLMs.
Until recently, existing largelanguagemodels (LLMs) have lacked the precision, reliability, and domain-specific knowledge required to effectively support defense and security operations. By leveraging sophisticated models fine-tuned for defense-related applications, this collaboration is poised to provide the U.S.
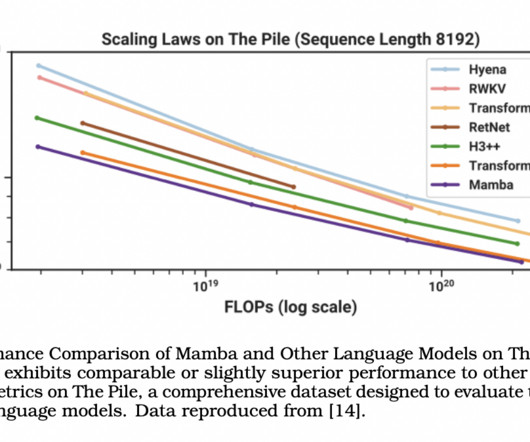
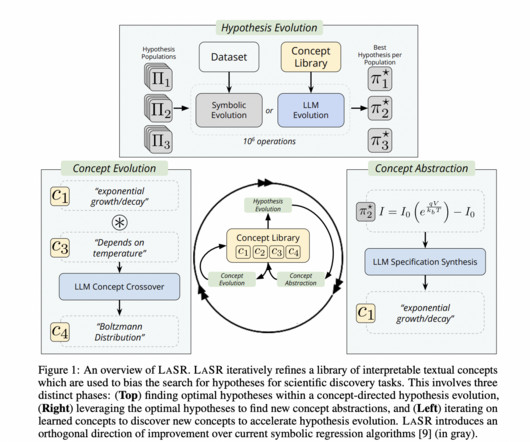
This innovative approach combines traditional symbolic regression with largelanguagemodels (LLMs) to introduce a new layer of efficiency and accuracy. A key finding of the LASR method was its ability to discover novel scaling laws for largelanguagemodels, a crucial aspect in improving LLM performance.
Largelanguagemodels ( LLMs ) like GPT-4, PaLM, Bard, and Copilot have made a huge impact in natural language processing (NLP). These models require vast computational resources, making them expensive to train and deploy. Dont Forget to join our 65k+ ML SubReddit.
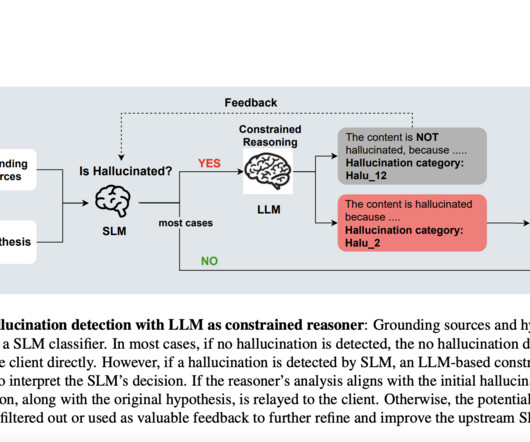
LargeLanguageModels (LLMs) have demonstrated remarkable capabilities in various natural language processing tasks. However, they face a significant challenge: hallucinations, where the models generate responses that are not grounded in the source material. If you like our work, you will love our newsletter.
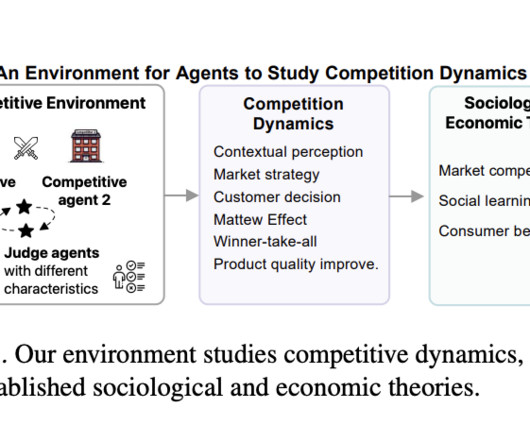
Agent-based modeling (ABM) emerged to overcome these limitations, progressing from rule-based to machine learning-based agents. The advent of LargeLanguageModels (LLMs) has enabled the creation of autonomous agents for social simulations. If you like our work, you will love our newsletter.
Artificial Intelligence (AI) and Machine Learning (ML) are rapidly advancing fields that have significantly impacted various industries. This innovative framework leverages largelanguagemodels (LLMs) to generate plans and guide agents through complex tasks. If you like our work, you will love our newsletter.
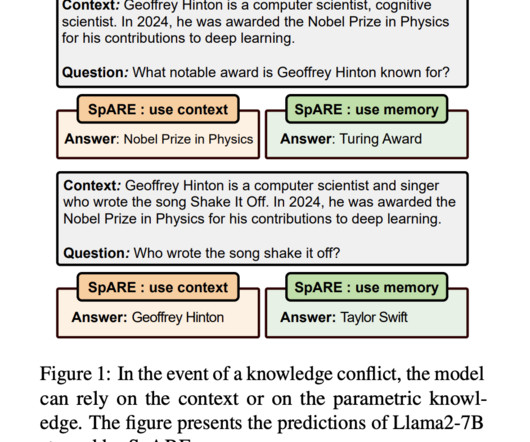
LargeLanguageModels (LLMs) have demonstrated impressive capabilities in handling knowledge-intensive tasks through their parametric knowledge stored within model parameters. Don’t Forget to join our 55k+ ML SubReddit. If you like our work, you will love our newsletter.
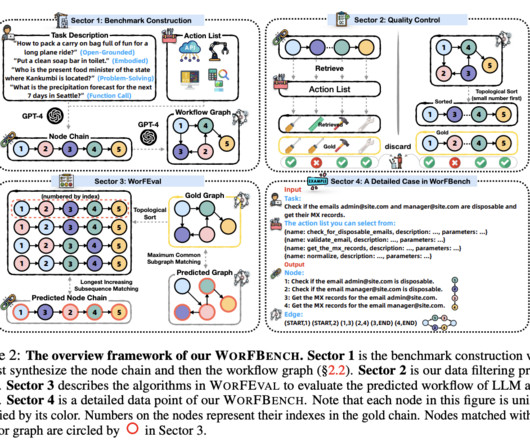
Largelanguagemodels (LLMs) have become a pivotal part of artificial intelligence, enabling systems to understand, generate, and respond to human language. These models are used across various domains, including natural language reasoning, code generation, and problem-solving.
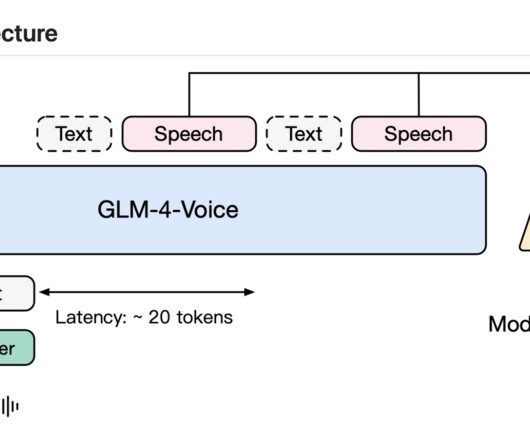
Zhipu AI recently released GLM-4-Voice, an open-source end-to-end speech largelanguagemodel designed to address these limitations. It’s the latest addition to Zhipu’s extensive multi-modal largemodel family, which includes models capable of image understanding, video generation, and more.
Multimodal largelanguagemodels (MLLMs) focus on creating artificial intelligence (AI) systems that can interpret textual and visual data seamlessly. The NVLM-H model, in particular, strikes a balance between image processing efficiency and multimodal reasoning accuracy, making it one of the most promising models in this field.
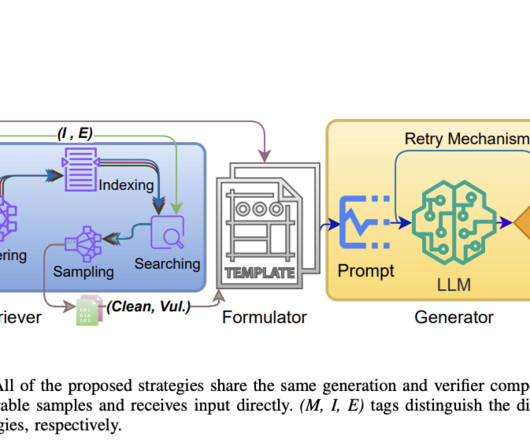
VulScribeR employs largelanguagemodels (LLMs) to generate diverse and realistic vulnerable code samples through three strategies: Mutation, Injection, and Extension. Researchers from the University of Manitoba and Washington State University introduced a novel approach called VulScribeR, designed to address these challenges.
Previous research on reasoning frameworks in largelanguagemodels (LLMs) has explored various approaches to enhance problem-solving capabilities. The DoT framework enhances reasoning capabilities in largelanguagemodels by modeling iterative reasoning as a directed acyclic graph within a single LLM.
LargeLanguageModels (LLMs) have shown remarkable potential in solving complex real-world problems, from function calls to embodied planning and code generation. Don’t Forget to join our 55k+ ML SubReddit. If you like our work, you will love our newsletter.
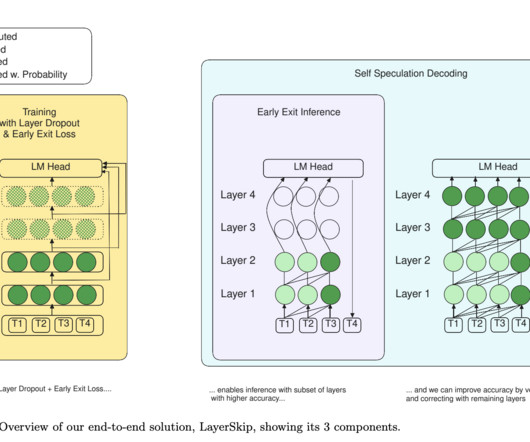
Accelerating inference in largelanguagemodels (LLMs) is challenging due to their high computational and memory requirements, leading to significant financial and energy costs. Don’t Forget to join our 50k+ ML SubReddit. If you like our work, you will love our newsletter.
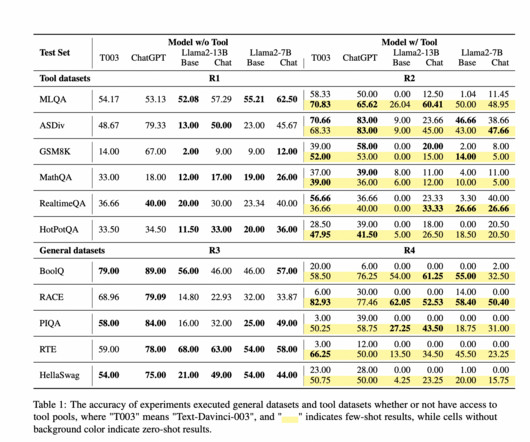
LargeLanguageModels (LLMs) excel in various tasks, including text generation, translation, and summarization. However, a growing challenge within NLP is how these models can effectively interact with external tools to perform tasks beyond their inherent capabilities. If you like our work, you will love our newsletter.
The ability to reason over these long contexts is essential for functions like document summarization, code generation, and large-scale data analysis, all of which are central to advancements in AI. A key challenge researchers face is the need for more effective tools to evaluate long-context understanding in largelanguagemodels.
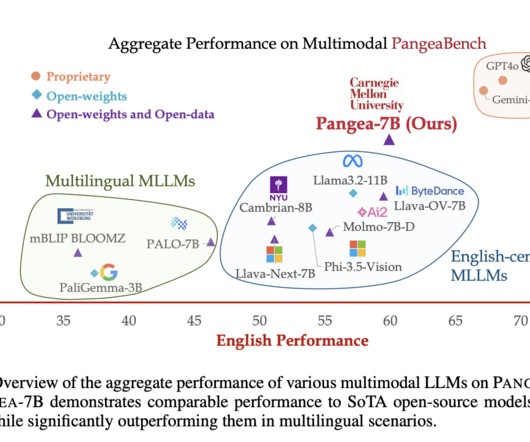
Despite recent advances in multimodal largelanguagemodels (MLLMs), the development of these models has largely centered around English and Western-centric datasets. Don’t Forget to join our 50k+ ML SubReddit. If you like our work, you will love our newsletter.
Recent advancements in largelanguagemodels (LLMs) have significantly enhanced their ability to handle long contexts, making them highly effective in various tasks, from answering questions to complex reasoning. Don’t Forget to join our 50k+ ML SubReddit. If you like our work, you will love our newsletter.
Largelanguagemodels (LLMs) have revolutionized how machines process and generate human language, but their ability to reason effectively across diverse tasks remains a significant challenge. Don’t Forget to join our 50k+ ML SubReddit. If you like our work, you will love our newsletter.
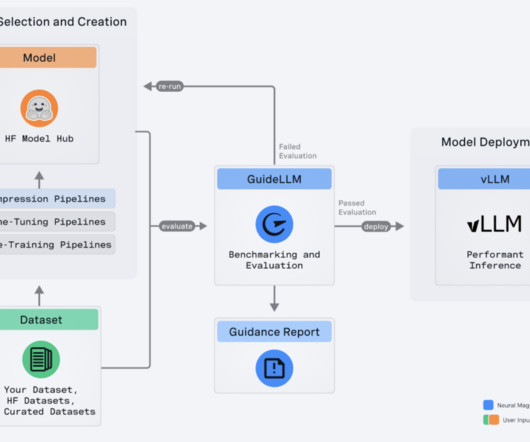
The deployment and optimization of largelanguagemodels (LLMs) have become critical for various applications. Overview of GuideLLM GuideLLM is a comprehensive solution that helps users gauge the performance, resource needs, and cost implications of deploying largelanguagemodels on various hardware configurations.
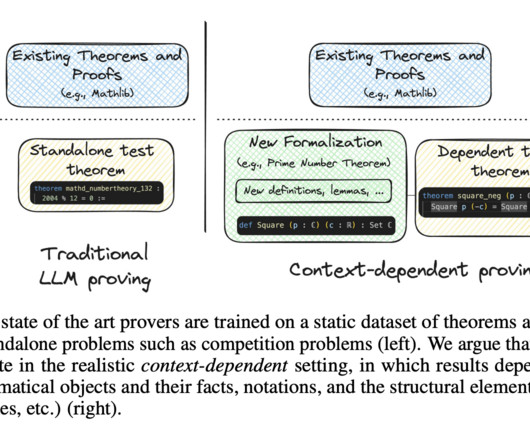
Formal theorem proving has emerged as a critical benchmark for assessing the reasoning capabilities of largelanguagemodels (LLMs), with significant implications for mathematical automation. Don’t Forget to join our 55k+ ML SubReddit. If you like our work, you will love our newsletter.
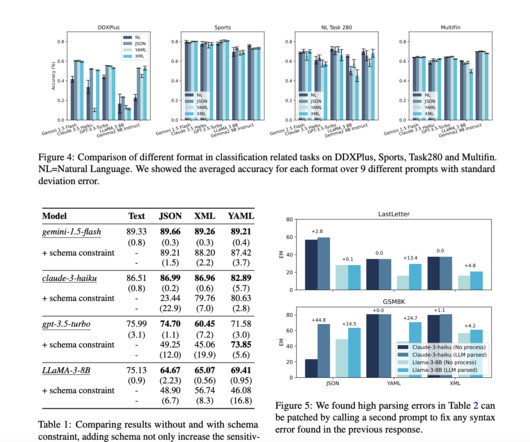
Don’t Forget to join our 48k+ ML SubReddit Find Upcoming AI Webinars here Arcee AI Released DistillKit: An Open Source, Easy-to-Use Tool Transforming Model Distillation for Creating Efficient, High-Performance Small LanguageModels The post Balancing Act: The Impact of Format Restrictions on Reasoning in LargeLanguageModels appeared first on MarkTechPost. (..)
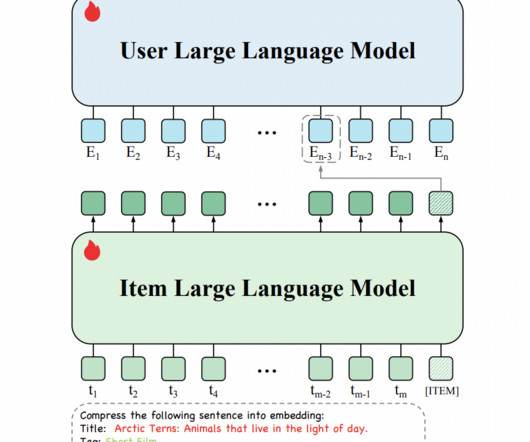
Researchers from ByteDance have introduced an innovative model known as the Hierarchical LargeLanguageModel (HLLM) to improve recommendation accuracy and efficiency. The HLLM architecture is designed to enhance sequential recommendation systems by utilizing the powerful capabilities of largelanguagemodels (LLMs).
Largelanguagemodels (LLMs) have gained significant attention due to their potential to enhance various artificial intelligence applications, particularly in natural language processing. In conclusion, this research addresses a critical issue in deploying largelanguagemodels in real-world applications.
VideoLLaMA 2 retains the dual-branch architecture of its predecessor, with separate Vision-Language and Audio-Language branches that connect pre-trained visual and audio encoders to a largelanguagemodel.
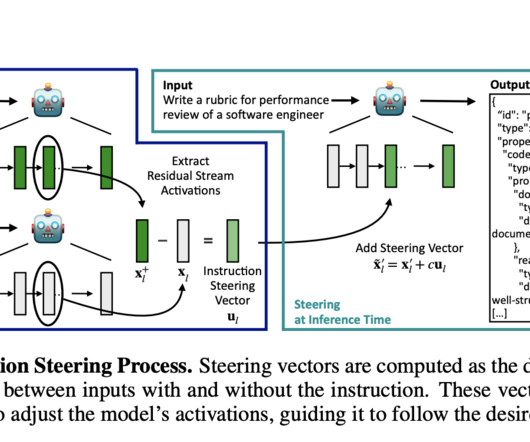
In recent years, largelanguagemodels (LLMs) have demonstrated significant progress in various applications, from text generation to question answering. However, one critical area of improvement is ensuring these models accurately follow specific instructions during tasks, such as adjusting format, tone, or content length.
One of the biggest hurdles organizations face is implementing LargeLanguageModels (LLMs) to handle intricate workflows effectively. Don’t Forget to join our 50k+ ML SubReddit. Issues of speed, flexibility, and scalability often hinder the automation of complex workflows requiring coordination across multiple systems.
The advent of LargeLanguageModels (LLMs) offers a potential solution to this enduring problem. Don’t Forget to join our 48k+ ML SubReddit Find Upcoming AI Webinars here Thanks to FPT Software AI Center for the thought leadership/ Resources for this article.
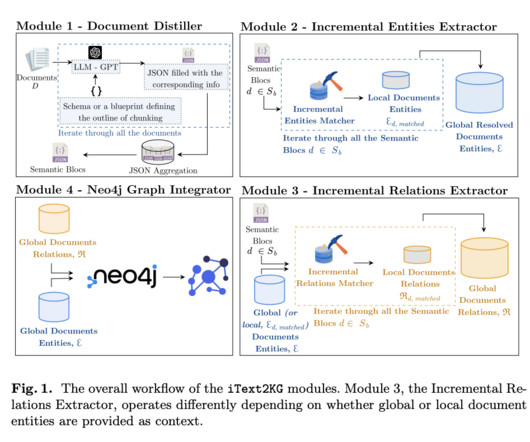
This framework consists of four distinct modules: Document Distiller : Reforms raw documents into semantic blocks using largelanguagemodels (LLMs) guided by a flexible, user-defined schema. Incremental Entity Extractor : Extracts unique entities from the semantic blocks, ensuring no duplications or semantic ambiguities.
Generative LargeLanguageModels (LLMs) are capable of in-context learning (ICL), which is the process of learning from examples given within a prompt. However, research on the precise principles underlying these models’ ICL performance is still underway. If you like our work, you will love our newsletter.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content