This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Largelanguagemodels (LLMs) have demonstrated promising capabilities in machine translation (MT) tasks. Depending on the use case, they are able to compete with neural translation models such as Amazon Translate. When using the FAISS adapter, translation units are stored into a local FAISS index along with the metadata.
Now, Syngenta is advancing further by using largelanguagemodels (LLMs) and Amazon Bedrock Agents to implement Cropwise AI on AWS, marking a new era in agricultural technology. In this post, we discuss Syngenta’s journey in developing Cropwise AI.
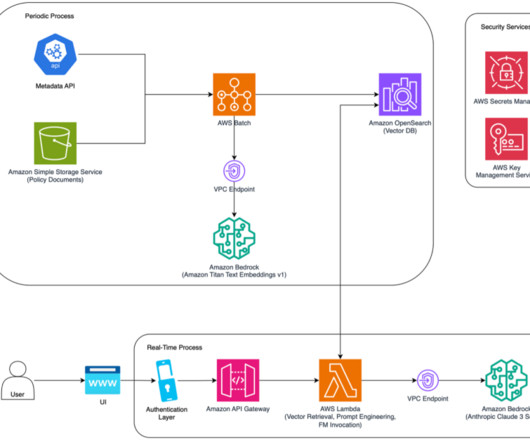
An AWS Batch job reads these documents, chunks them into smaller slices, then creates embeddings of the text chunks using the Amazon Titan Text Embeddings model through Amazon Bedrock and stores them in an Amazon OpenSearch Service vector database. You can create a decoupled architecture with reusable components. Tarik Makota is a Sr.
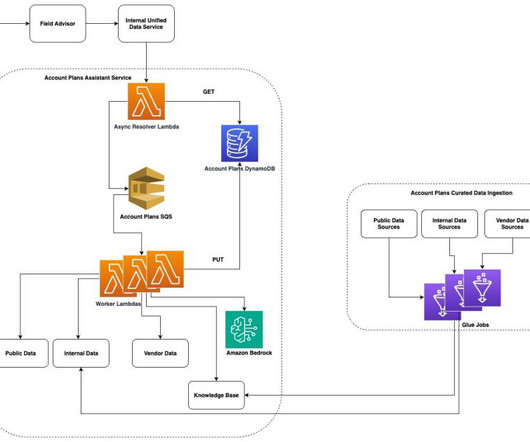
Mid-market Account Manager Amazon Q, Amazon Bedrock, and other AWS services underpin this experience, enabling us to use largelanguagemodels (LLMs) and knowledge bases (KBs) to generate relevant, data-driven content for APs. Its a game-changer for serving my full portfolio of accounts.
To start simply, you could think of LLMOps ( LargeLanguageModel Operations) as a way to make machine learning work better in the real world over a long period of time. As previously mentioned: model training is only part of what machine learning teams deal with. What is LLMOps? Why are these elements so important?
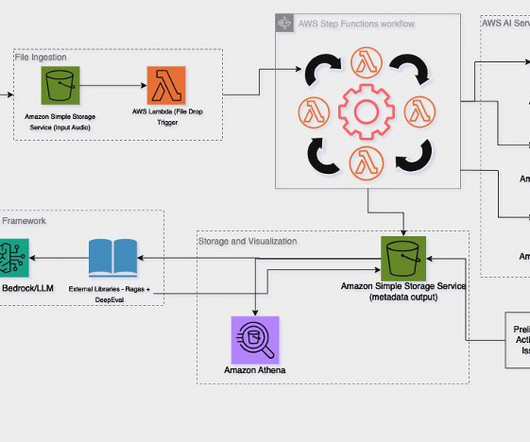
The evaluation framework, call metadata generation, and Amazon Q in QuickSight were new components introduced from the original PCA solution. Ragas and a human-in-the-loop UI (as described in the customer blogpost with Tealium) were used to evaluate the metadata generation and individual call Q&A portions.
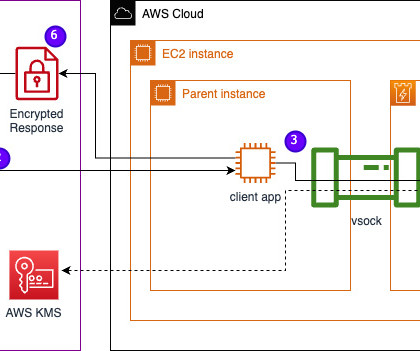
In this post, we discuss how Leidos worked with AWS to develop an approach to privacy-preserving largelanguagemodel (LLM) inference using AWS Nitro Enclaves. t “enclave_base” Save the LLM in the EC2 Instance We are using the open-source Bloom 560m LLM for natural language processing to generate responses.
For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security. The role information is also used to configure metadata filtering in the knowledge bases to generate relevant responses.
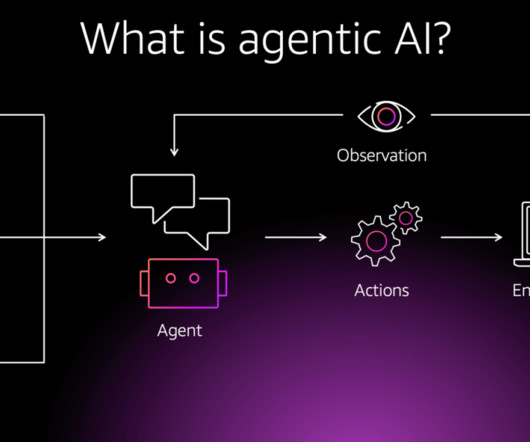
Agentic design An AI agent is an autonomous, intelligent system that uses largelanguagemodels (LLMs) and other AI capabilities to perform complex tasks with minimal human oversight. Agentic systems, on the other hand, are designed to bridge this gap by combining the flexibility of context-aware systems with domain knowledge.
However, traditional machine learning approaches often require extensive data-specific tuning and model customization, resulting in lengthy and resource-heavy development. Enter Chronos , a cutting-edge family of time series models that uses the power of largelanguagemodel ( LLM ) architectures to break through these hurdles.
Largelanguagemodels (LLMs) excel at generating human-like text but face a critical challenge: hallucinationproducing responses that sound convincing but are factually incorrect. About the Authors Dheer Toprani is a System Development Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team.
NVIDIA and cloud service provider (CSP) Scaleway are working together to deliver access to GPUs, NVIDIA AI Enterprise software, and services for turbocharging largelanguagemodels (LLMs) and generative AI development for European startups. When doing business in Europe, U.S.
This enables the Amazon Q largelanguagemodel (LLM) to provide accurate, well-written answers by drawing from the consolidated data and information. Additionally, they want access to metadata, timestamps, and access control lists (ACLs) for the indexed documents. The following diagram shows a flowchart of a sync run job.
Omniverse is a platform of application programming interfaces, softwaredevelopment kits and services that enable developers to easily integrate OpenUSD and NVIDIA RTX rendering technologies into existing software tools and simulation workflows.
It was built using a combination of in-house and external cloud services on Microsoft Azure for largelanguagemodels (LLMs), Pinecone for vectorized databases, and Amazon Elastic Compute Cloud (Amazon EC2) for embeddings. Opportunities for innovation CreditAI by Octus version 1.x x uses Retrieval Augmented Generation (RAG).
In summary, largelanguagemodels offer businesses the potential to automate and enhance customer interactions, improve operational efficiency, and gain deeper insights from their data. Repository Information**: Not shown in the provided excerpt, but likely contains metadata about the repository.
Most organizations today want to utilize largelanguagemodels (LLMs) and implement proof of concepts and artificial intelligence (AI) agents to optimize costs within their business processes and deliver new and creative user experiences. However, the majority of these implementations are ‘one-offs.’
Training largelanguagemodels (LLMs) models has become a significant expense for businesses. For many use cases, companies are looking to use LLM foundation models (FM) with their domain-specific data. First, create the Python file, touch consolidation.py and shell file, touch consolidation.sh
SageMaker Pipelines can handle model versioning and lineage tracking. It automatically keeps track of model artifacts, hyperparameters, and metadata, helping you to reproduce and audit model versions. Ashish has extensive experience in Enterprise IT architecture and softwaredevelopment including AI/ML and generative AI.
Next, you need to index this data to make it available for a Retrieval Augmented Generation (RAG) approach, where relevant passages are delivered with high accuracy to a largelanguagemodel (LLM). Amazon Q supports the crawling and indexing of these custom objects and custom metadata.
Prompt catalog – Crafting effective prompts is important for guiding largelanguagemodels (LLMs) to generate the desired outputs. Model deployment and rollback – To facilitate the deployment and usage of new model versions into production environments and the rollback to previous versions if necessary.
Softwaredevelopers and engineers, for instance, use several AI-powered tools to code more quickly, increasing productivity and reducing costs as AI takes over menial tasks. And beyond tedious work, gen AI can help prototype much faster because the largelanguagemodels can take over the refactoring and documentation of code.
With the advent of generative AI, and in particular largelanguagemodels (LLMs), we have now adopted an AI by design strategy, evaluating the application of AI for every new technology product we develop. The core work of developing a news story revolves around researching, writing, and editing the article.
Next you need to index the data to make it available for a Retrieval Augmented Generation (RAG) approach where relevant passages are delivered with high accuracy to a largelanguagemodel (LLM). In this example, metadata files including the ACLs are in a folder named Meta. How can I sync documents without ACLs?
Speech AI also includes Audio Intelligence models, which analyze and draw insights from audio data. These models can perform tasks like summarization, identifying topics, and PII redaction. 5 benefits of Speech AI for LMS platforms Learning management systems comprise a variety of functions and tools for users of all kinds.
Solution overview The LMA sample solution captures speaker audio and metadata from your browser-based meeting app (as of this writing, Zoom and Chime are supported), or audio only from any other browser-based meeting app, softphone, or audio source. You can also create your own custom prompts and corresponding options.
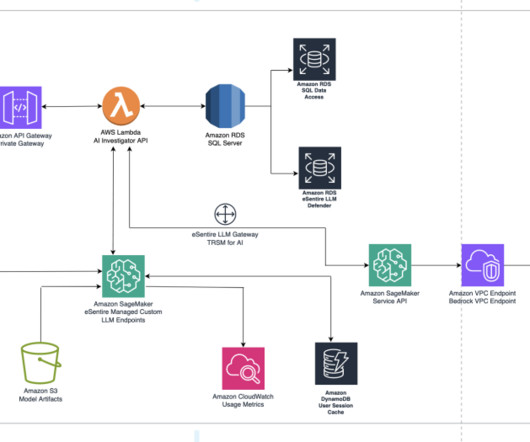
Solution overview eSentire customers expect rigorous security and privacy controls for their sensitive data, which requires an architecture that doesn’t share data with external largelanguagemodel (LLM) providers. Therefore, eSentire decided to build their own LLM using Llama 1 and Llama 2 foundational models.
Acting as a model hub, JumpStart provided a large selection of foundation models and the team quickly ran their benchmarks on candidate models. After selecting candidate largelanguagemodels (LLMs), the science teams can proceed with the remaining steps by adding more customization.
These assistants can be powered by various backend architectures including Retrieval Augmented Generation (RAG), agentic workflows, fine-tuned largelanguagemodels (LLMs), or a combination of these techniques. To learn more about FMEval, see Evaluate largelanguagemodels for quality and responsibility of LLMs.
Curiosity led me down an exciting path of discovery, and I stumbled upon a framework that I think is revolutionizing the world of app development in the context of LargeLanguageModels. All nuances of softwaredevelopment remain unexplored. We unleash the power of largelanguagemodels.
The large machine learning (ML) modeldevelopment lifecycle requires a scalable model release process similar to that of softwaredevelopment. Modeldevelopers often work together in developing ML models and require a robust MLOps platform to work in.
Amazon Q Business is a fully managed, generative AI-powered assistant that lets you build interactive chat applications using your enterprise data, generating answers based on your data or largelanguagemodel (LLM) knowledge. Guillermo has developed a keen interest in serverless architectures and generative AI applications.
Next, you need to index this data to make it available for a Retrieval Augmented Generation (RAG) approach where relevant passages are delivered with high accuracy to a largelanguagemodel (LLM). Amazon Q supports the crawling and indexing of these custom objects and custom metadata.
This Lambda function identifies CTR records and provides an additional processing step that outputs an enhanced transcript containing additional metadata such as queue and agent ID information, IVR identification and tagging, and how many agents (and IVRs) the customer was transferred to, all aggregated from the CTR records.
It enables teams to collaborate on softwaredevelopment projects, track changes, and manage code repositories. It allows you to create custom workflows that automate your softwaredevelopment lifecycle processes, such as building, testing, and deploying code.
In recent times, the rapid advancement of AI technologies like ChatGPT and other LargeLanguageModels (LLMs) have sparked growing panic among the software engineering community. Headlines warning of the looming robot takeover have fueled this unease, making developers question the future of their occupation.
BGE Large overview The embedding model BGE Large stands for BAAI general embedding large. It’s developed by BAAI and is designed to enhance retrieval capabilities within largelanguagemodels (LLMs). She has over 15 years of IT experience in softwaredevelopment, design and architecture.
Next, you need to index this data to make it available for a Retrieval Augmented Generation (RAG) approach, where relevant passages are delivered with high accuracy to a largelanguagemodel (LLM). Lakshmi Dogiparti is a is a SoftwareDevelopment Engineer at Amazon Web Services.
This enables the Amazon Q largelanguagemodel (LLM) to provide accurate, well-written answers by drawing from the consolidated data and information. Neelam Rana is a SoftwareDevelopment Engineer on the Amazon Q and Amazon Kendra engineering team. Outside of work, he enjoys running, playing tennis, and cooking.
These applications can generate answers based on your data or a largelanguagemodel (LLM) knowledge. Each document has its own attributes, also known as metadata. Metadata can be mapped to fields in your Amazon Q Business index. By creating index fields, you can boost results based on document attributes.
This use case highlights how largelanguagemodels (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning.
However, businesses can meet this challenge while providing personalized and efficient customer service with the advancements in generative artificial intelligence (generative AI) powered by largelanguagemodels (LLMs). A session stores metadata and application-specific data known as session attributes. Choose Delete.
Largelanguagemodels (LLMs) have transformed the way we engage with and process natural language. These powerful models can understand, generate, and analyze text, unlocking a wide range of possibilities across various domains and industries. This provides an automated deployment experience on your AWS account.
Generating embeddings of text and images using the same model helps you measure the distance between vectors to find semantic similarities. For example, you can embed all image metadata and additional text descriptions into the same vector space. Close vectors indicate that the images and text are semantically related.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content