This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
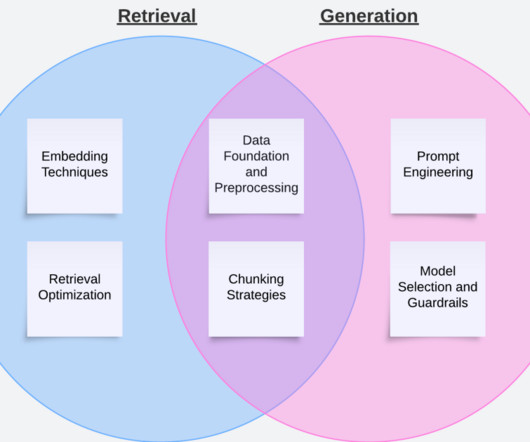
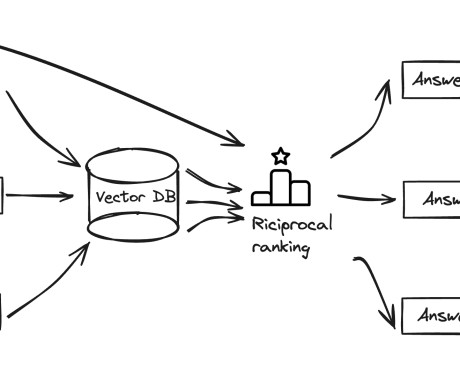
The effectiveness of RAG heavily depends on the quality of context provided to the largelanguagemodel (LLM), which is typically retrieved from vector stores based on user queries. The relevance of this context directly impacts the model’s ability to generate accurate and contextually appropriate responses.
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Video data analysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.
At the forefront of using generative AI in the insurance industry, Verisks generative AI-powered solutions, like Mozart, remain rooted in ethical and responsibleAI use. For the generative AI description of change, Verisk wanted to capture the essence of the change instead of merely highlighting the differences.
Instead of solely focusing on whos building the most advanced models, businesses need to start investing in robust, flexible, and secure infrastructure that enables them to work effectively with any AImodel, adapt to technological advancements, and safeguard their data. AI governance manages three things.
Largelanguagemodels (LLMs) have exploded in popularity over the last few years, revolutionizing natural language processing and AI. What are LargeLanguageModels and Why are They Important? Hybrid retrieval combines dense embeddings and sparse keyword metadata for improved recall.
Amazon Bedrock also allows you to choose various models for different use cases, making it an obvious choice for the solution due to its flexibility. Using Amazon Bedrock allows for iteration of the solution using knowledge bases for simple storage and access of call transcripts as well as guardrails for building responsibleAI applications.
The benefits of using Amazon Bedrock Data Automation Amazon Bedrock Data Automation provides a single, unified API that automates the processing of unstructured multi-modal content, minimizing the complexity of orchestrating multiple models, fine-tuning prompts, and stitching outputs together.
You can directly use the FMEval wherever you run your workloads, as a Python package or via the open-source code repository, which is made available in GitHub for transparency and as a contribution to the ResponsibleAI community. In the case your dataset already has model inference, you do not need to configure a Model Runner.
Participants learn to build metadata for documents containing text and images, retrieve relevant text chunks, and print citations using Multimodal RAG with Gemini. TensorFlow on Google Cloud This course covers designing TensorFlow input data pipelines and building ML models with TensorFlow and Keras.
Evolving Trends in Prompt Engineering for LargeLanguageModels (LLMs) with Built-in ResponsibleAI Practices Editor’s note: Jayachandran Ramachandran and Rohit Sroch are speakers for ODSC APAC this August 22–23. As LLMs become integral to AI applications, ethical considerations take center stage.
Largelanguagemodels (LLMs) have come a long way from being able to read only text to now being able to read and understand graphs, diagrams, tables, and images. It also provides a broad set of capabilities to build generative AI applications with security, privacy, and responsibleAI.
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. Today, generative AI can help bridge this knowledge gap for nontechnical users to generate SQL queries by using a text-to-SQL application. The FM generates the SQL query based on the final input.
Evaluating largelanguagemodels (LLMs) is crucial as LLM-based systems become increasingly powerful and relevant in our society. By investing in robust evaluation practices, companies can maximize the benefits of LLMs while maintaining responsibleAI implementation and minimizing potential drawbacks.
AI governance refers to the practice of directing, managing and monitoring an organization’s AI activities. It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. Generative AI chatbots have been known to insult customers and make up facts.
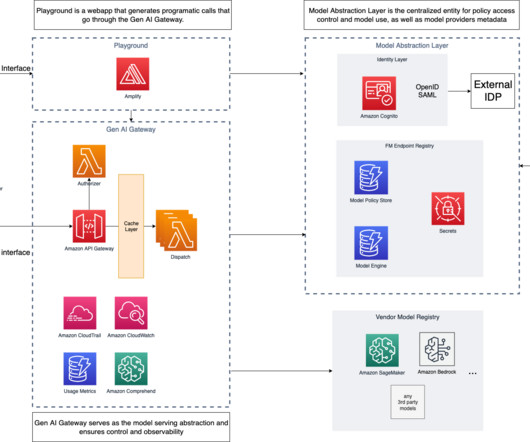
In this second part, we expand the solution and show to further accelerate innovation by centralizing common Generative AI components. We also dive deeper into access patterns, governance, responsibleAI, observability, and common solution designs like Retrieval Augmented Generation. They’re illustrated in the following figure.
Add ResponsibleAI to LLM’s Add Abuse detection to LLM’s. Storage all prompts and completions in a data lake for future use and also metadata about api, configurations etc. at main · balakreshnan/Samples2023 · GitHub BECOME a WRITER at MLearning.ai // invisible ML // 800+ AI tools Mlearning.ai
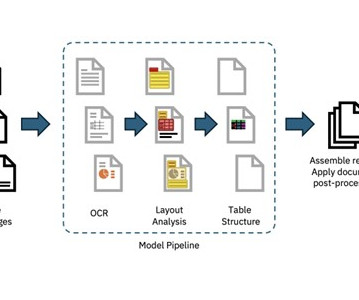
Each text, including the rotated text on the left of the page, is identified and extracted as a stand-alone text element with coordinates and other metadata that makes it possible to render a document very close to the original PDF but from a structured JSONformat.
Backed by its powerful largelanguagemodels (LLMs), users can query their notes and documents with ChatRTX, which can quickly generate relevant responses, while running locally on the user’s device. Users can also interact with image data thanks to support for Contrastive Language-Image Pre-training from OpenAI.
The Amazon Bedrock evaluation tool provides a comprehensive assessment framework with eight metrics that cover both response quality and responsibleAI considerations. Implement metadata filtering , adding contextual layers to chunk retrieval. For example, prioritizing recent information in time-sensitive scenarios.
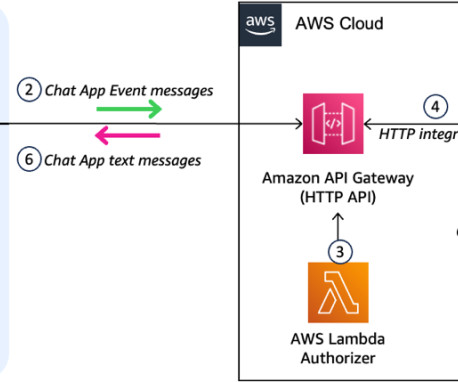
This post shows how you can implement an AI-powered business assistant, such as a custom Google Chat app, using the power of Amazon Bedrock. This request contains the user’s message and relevant metadata. The custom Google Chat app, configured for HTTP integration, sends an HTTP request to an API Gateway endpoint.
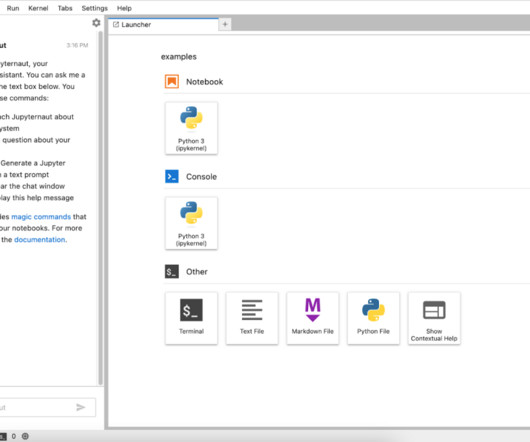
It allows users to explain and generate code, fix errors, summarize content, and even generate entire notebooks from natural language prompts. The tool connects Jupyter with largelanguagemodels (LLMs) from various providers, including AI21, Anthropic, AWS, Cohere, and OpenAI, supported by LangChain.
Largelanguagemodels (LLMs) excel at generating human-like text but face a critical challenge: hallucinationproducing responses that sound convincing but are factually incorrect. About the Authors Dheer Toprani is a System Development Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team.
The award, totaling $299,208 for one year, will be used for research and development of LLMs for automated named entity recognition (NER), relation extraction, and ontology metadata enrichment from free-text clinical notes.
Building enhanced semantic search capabilities that analyze media contextually would lay the groundwork for creating AI-generated content, allowing customers to produce customized media more efficiently. With recent advances in largelanguagemodels (LLMs), Veritone has updated its platform with these powerful new AI capabilities.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsibleAI.
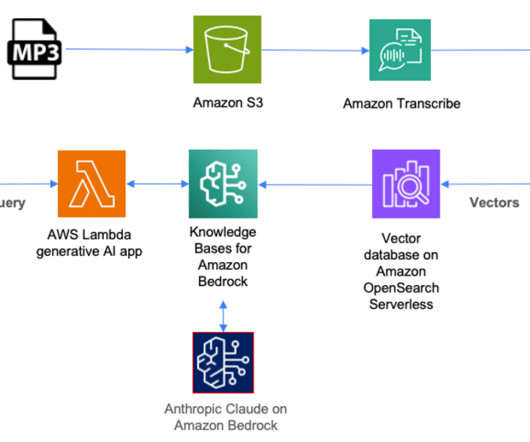
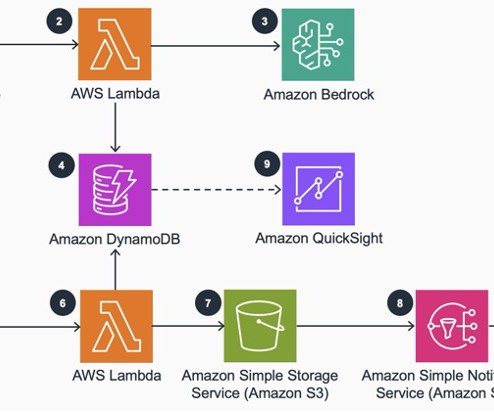
The image damage analysis notification agent is responsible for doing a preliminary analysis of the images uploaded for a damage. This agent invokes a Lambda function that internally calls the Anthropic Claude Sonnet largelanguagemodel (LLM) on Amazon Bedrock to perform preliminary analysis on the images.
client(service_name='bedrock-agent-runtime', region_name=CONFIG['aws']['region_name']) ) Configure : The config.yaml file specifies the model ID, Region, prompts for entity extraction, and the output file location for processing. Returns: Tuple[S3Client, BedrockRuntimeClient] """ return ( boto3.client('s3', endswith('.pdf'):
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support.
For example: The state-of-the-art (SOTA) of models, architectures, and best practices are constantly changing. This means companies need loose coupling between app clients (model consumers) and model inference endpoints, which ensures easy switch among largelanguagemodel (LLM), vision, or multi-modal endpoints if needed.
Retrieval Augmented Generation (RAG) has emerged as a leading method for using the power of largelanguagemodels (LLMs) to interact with documents in natural language. The text embedding model processes the text chunks and generates embedding vectors for each text chunk.
This post highlights how Twilio enabled natural language-driven data exploration of business intelligence (BI) data with RAG and Amazon Bedrock. Twilio’s use case Twilio wanted to provide an AI assistant to help their data analysts find data in their data lake. For information about model pricing, refer to Amazon Bedrock pricing.
It’s a convenient user interface built around one specific languagemodel, GPT-3.5, is one of a class of languagemodels that are sometimes called “largelanguagemodels” (LLMs)—though that term isn’t very helpful. The GPT-series LLMs are also called “foundation models.” GPT-2, 3, 3.5,
It’s a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like Anthropic, Cohere, Meta, Mistral AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsibleAI.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsibleAI.
For several years, we have been actively using machine learning and artificial intelligence (AI) to improve our digital publishing workflow and to deliver a relevant and personalized experience to our readers. This blog post outlines various use cases where we’re using generative AI to address digital publishing challenges.
Generative AI question-answering applications are pushing the boundaries of enterprise productivity. These assistants can be powered by various backend architectures including Retrieval Augmented Generation (RAG), agentic workflows, fine-tuned largelanguagemodels (LLMs), or a combination of these techniques.
Finding relevant content usually requires searching through text-based metadata such as timestamps, which need to be manually added to these files. Next, Knowledge Bases for Amazon Bedrock augments the user’s original query with these results to a prompt, which is sent to the largelanguagemodel (LLM).
As one of the most rapidly developing fields in AI, the capabilities for and applications of LargeLanguageModels (LLMs) are changing and growing continuously. It can be hard to keep on top of all the advancements. Check out a few of them below. This talk provides a comprehensive framework for securing LLM applications.
Topics Include: Agentic AI DesignPatterns LLMs & RAG forAgents Agent Architectures &Chaining Evaluating AI Agent Performance Building with LangChain and LlamaIndex Real-World Applications of Autonomous Agents Who Should Attend: Data Scientists, Developers, AI Architects, and ML Engineers seeking to build cutting-edge autonomous systems.
The solution intends to address these limitations for practical generative artificial intelligence (AI) assistant use cases. For tables, the system retrieves relevant table locations and metadata, and computes the cosine similarity between the multimodal embedding and the vectors representing the table and its summary.
The latest advances in generative artificial intelligence (AI) allow for new automated approaches to effectively analyze large volumes of customer feedback and distill the key themes and highlights. This post explores an innovative application of largelanguagemodels (LLMs) to automate the process of customer review analysis.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsibleAI.
9am PT Thursday, March 6: Automated DICOM Deidentification with AWS HealthImaging (AWS booth #4624) This talk will explore John Snow Labs turnkey, regulatory grade DICOM image de-identification on AWS HealthImaging, including both metadata and pixel-level PHI, integrated with AWS HealthImaging to support compliance and scale.
Anthropic has moved toward safer and more transparent AI usage, by introducing Clio. This is a new system designed to analyze real-world interactions with AI while preserving user privacy. Heres how itworks: Facet Extraction: Conversations are analyzed to extract metadata like topics or languageused.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content