This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
Largelanguagemodels (LLMs) have demonstrated promising capabilities in machine translation (MT) tasks. Depending on the use case, they are able to compete with neural translation models such as Amazon Translate. The solution proposed in this post relies on LLMs context learning capabilities and promptengineering.
LargeLanguageModels (LLMs) have revolutionized AI with their ability to understand and generate human-like text. Learning about LLMs is essential to harness their potential for solving complex language tasks and staying ahead in the evolving AI landscape.
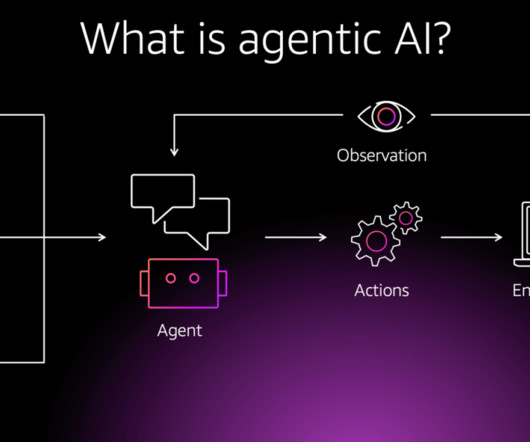
The growth of autonomous agents by foundation models (FMs) like LargeLanguageModels (LLMs) has reform how we solve complex, multi-step problems. These agents perform tasks ranging from customer support to software engineering, navigating intricate workflows that combine reasoning, tool use, and memory.
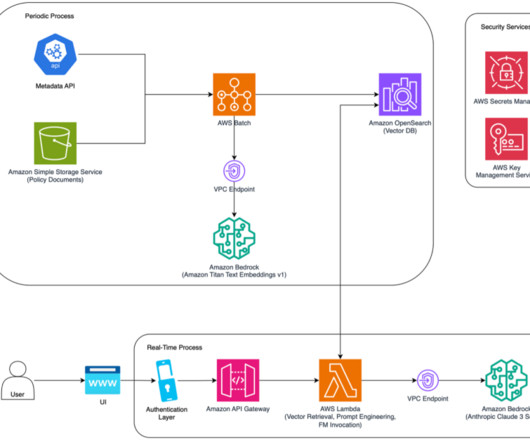
An AWS Batch job reads these documents, chunks them into smaller slices, then creates embeddings of the text chunks using the Amazon Titan Text Embeddings model through Amazon Bedrock and stores them in an Amazon OpenSearch Service vector database.
Customizable Uses promptengineering , which enables customization and iterative refinement of the prompts used to drive the largelanguagemodel (LLM), allowing for refining and continuous enhancement of the assessment process. Metadata filtering is used to improve retrieval accuracy.
Largelanguagemodels (LLMs) have exploded in popularity over the last few years, revolutionizing natural language processing and AI. From chatbots to search engines to creative writing aids, LLMs are powering cutting-edge applications across industries. What are LargeLanguageModels and Why are They Important?
Largelanguagemodels (LLMs) like OpenAI's GPT series have been trained on a diverse range of publicly accessible data, demonstrating remarkable capabilities in text generation, summarization, question answering, and planning. But the drawback for this is its reliance on the skill and expertise of the user in promptengineering.
In this post, we show you an example of a generative AI assistant application and demonstrate how to assess its security posture using the OWASP Top 10 for LargeLanguageModel Applications , as well as how to apply mitigations for common threats. This can lead to privacy and confidentiality violations.
Additionally, largelanguagemodel (LLM)-based analysis is applied to derive further insights, such as video summaries and classifications. These analytics are implemented with either Amazon Comprehend , or separate promptengineering with FMs.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
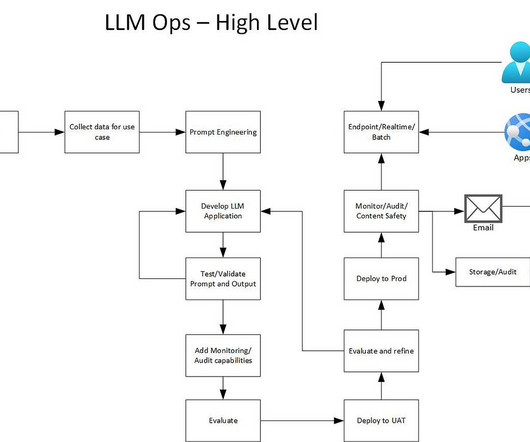
To start simply, you could think of LLMOps ( LargeLanguageModel Operations) as a way to make machine learning work better in the real world over a long period of time. As previously mentioned: model training is only part of what machine learning teams deal with. What is LLMOps? Why are these elements so important?
This post was co-written with Vishal Singh, Data Engineering Leader at Data & Analytics team of GoDaddy Generative AI solutions have the potential to transform businesses by boosting productivity and improving customer experiences, and using largelanguagemodels (LLMs) in these solutions has become increasingly popular.
Evolving Trends in PromptEngineering for LargeLanguageModels (LLMs) with Built-in Responsible AI Practices Editor’s note: Jayachandran Ramachandran and Rohit Sroch are speakers for ODSC APAC this August 22–23. This trainable custom model can then be progressively improved through a feedback loop as shown above.
Evaluating largelanguagemodels (LLMs) is crucial as LLM-based systems become increasingly powerful and relevant in our society. Furthermore, evaluation processes are important not only for LLMs, but are becoming essential for assessing prompt template quality, input data quality, and ultimately, the entire application stack.
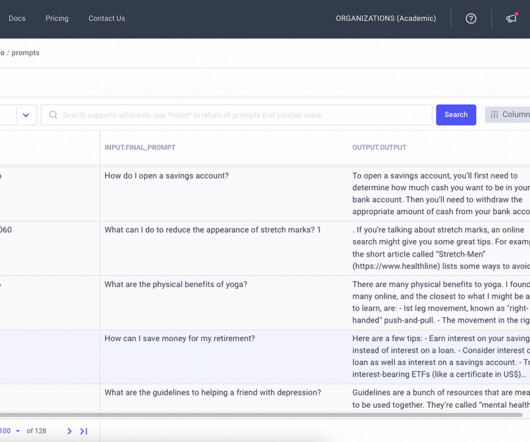
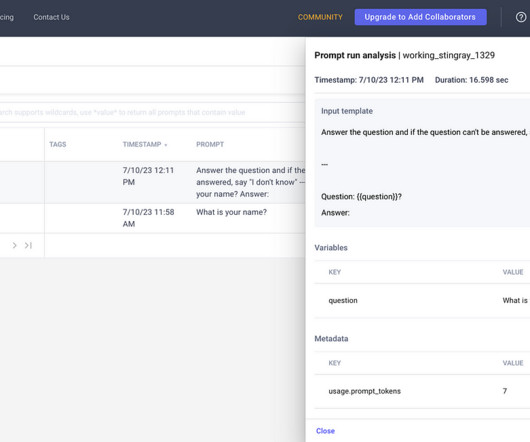
Introduction PromptEngineering is arguably the most critical aspect in harnessing the power of LargeLanguageModels (LLMs) like ChatGPT. However; current promptengineering workflows are incredibly tedious and cumbersome. Logging prompts and their outputs to .csv
Agentic design An AI agent is an autonomous, intelligent system that uses largelanguagemodels (LLMs) and other AI capabilities to perform complex tasks with minimal human oversight. Amazon Bedrock manages promptengineering, memory, monitoring, encryption, user permissions, and API invocation.
PromptEngineering — this is where figuring out what is the right prompt to use for the problem. Develop the LLM application using existing models or train a new model. Storage all prompts and completions in a data lake for future use and also metadata about api, configurations etc.
Inspect Rich Documents with Gemini Multimodality and Multimodal RAG This course covers using multimodal prompts to extract information from text and visual data and generate video descriptions with Gemini. TensorFlow on Google Cloud This course covers designing TensorFlow input data pipelines and building ML models with TensorFlow and Keras.
I’m so excited to talk to you about LanguageModels! They’re these incredible creations called LargeLanguageModels (LLMs) that have the power to understand and generate human-like text. Comet’s LLMOps tool provides an intuitive and responsive view of our prompt history. Image by Author Hey there!
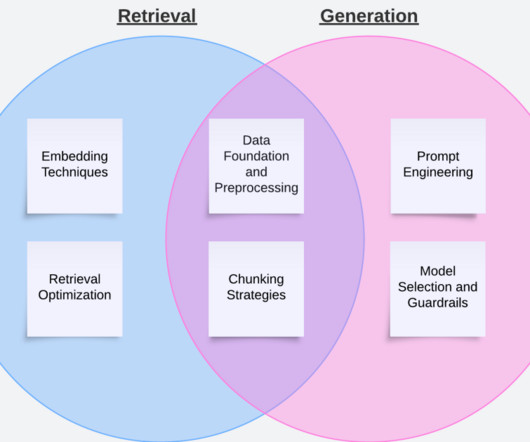
Implement metadata filtering , adding contextual layers to chunk retrieval. For code samples for metadata filtering using Amazon Bedrock Knowledge Bases, refer to the following GitHub repo. Success comes from methodically using techniques like promptengineering and chunking to improve both the retrieval and generation stages of RAG.
The performance and quality of the models also improved drastically with the number of parameters. These models span tasks like text-to-text, text-to-image, text-to-embedding, and more. You can use largelanguagemodels (LLMs), more specifically, for tasks including summarization, metadata extraction, and question answering.
LargeLanguageModels (LLMs) are becoming integral to modern technology, driving agentic systems that interact dynamically with external environments. Despite their impressive capabilities, LLMs are highly vulnerable to prompt injection attacks. The overhead primarily manifests in token usage, with approximately a 2.82
The recent NLP Summit served as a vibrant platform for experts to delve into the many opportunities and also challenges presented by largelanguagemodels (LLMs). Implementation Hurdles: For these top performers, 24% see the models and tools as their primary challenge, followed by talent acquisition (20%) and scaling (19%).
Largelanguagemodels (LLMs) have unlocked new possibilities for extracting information from unstructured text data. This post walks through examples of building information extraction use cases by combining LLMs with promptengineering and frameworks such as LangChain.
Largelanguagemodels (LLMs) are revolutionizing fields like search engines, natural language processing (NLP), healthcare, robotics, and code generation. Another essential component is an orchestration tool suitable for promptengineering and managing different type of subtasks.
.” Sean Im, CEO, Samsung SDS America “In the field of generative AI and foundation models, watsonx is a platform that will enable us to meet our customers’ requirements in terms of optimization and security, while allowing them to benefit from the dynamism and innovations of the open-source community.”
Prompt catalog – Crafting effective prompts is important for guiding largelanguagemodels (LLMs) to generate the desired outputs. Promptengineering is typically an iterative process, and teams experiment with different techniques and prompt structures until they reach their target outcomes.
This post highlights how Twilio enabled natural language-driven data exploration of business intelligence (BI) data with RAG and Amazon Bedrock. They used the metadata layer (schema information) over their data lake consisting of views (tables) and models (relationships) from their data reporting tool, Looker , as the source of truth.
Hosting largelanguagemodels Vitech explored the option of hosting LargeLanguageModels (LLMs) models using Amazon Sagemaker. Vitech needed a fully managed and secure experience to host LLMs and eliminate the undifferentiated heavy lifting associated with hosting 3P models.
Generative AI and transformer-based largelanguagemodels (LLMs) have been in the top headlines recently. These models demonstrate impressive performance in question answering, text summarization, code, and text generation. We use promptengineering to send our summarization instructions to the LLM.
Retrieval Augmented Generation (RAG) has emerged as a leading method for using the power of largelanguagemodels (LLMs) to interact with documents in natural language. The text embedding model processes the text chunks and generates embedding vectors for each text chunk.
With the advent of generative AI, and in particular largelanguagemodels (LLMs), we have now adopted an AI by design strategy, evaluating the application of AI for every new technology product we develop. We use a single-shot prompt with the full article text in context to generate the summary.
Largelanguagemodels (LLMs) have transformed the way we engage with and process natural language. These powerful models can understand, generate, and analyze text, unlocking a wide range of possibilities across various domains and industries.
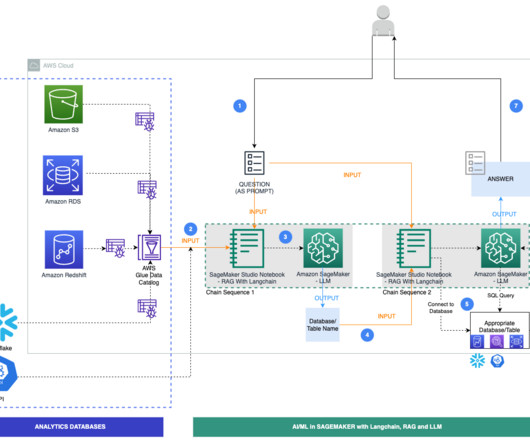
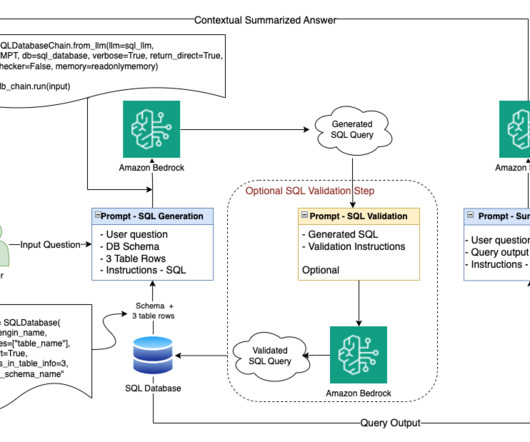
The workflow for NLQ consists of the following steps: A Lambda function writes schema JSON and table metadata CSV to an S3 bucket. The wrapper function reads the table metadata from the S3 bucket. The wrapper function creates a dynamic prompt template and gets relevant tables using Amazon Bedrock and LangChain.
W&B (Weights & Biases) W&B is a machine learning platform for your data science teams to track experiments, version and iterate on datasets, evaluate model performance, reproduce models, visualize results, spot regressions, and share findings with colleagues. Can you find experiments and models easily?
The latest offering for generative AI from AWS is Amazon Bedrock , which is a fully managed service and the easiest way to build and scale generative AI applications with foundation models. AWS also offers foundation models through Amazon SageMaker JumpStart as Amazon SageMaker endpoints. LangChain requires an LLM to be defined.
Experimentation and challenges It was clear from the beginning that to understand a human language question and generate accurate answers, Q4 would need to use largelanguagemodels (LLMs). Further performance optimization involved fine-tuning the query generation process using efficient promptengineering techniques.
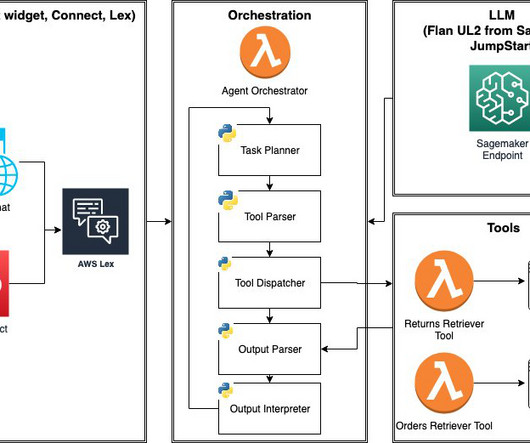
Largelanguagemodel (LLM) agents are programs that extend the capabilities of standalone LLMs with 1) access to external tools (APIs, functions, webhooks, plugins, and so on), and 2) the ability to plan and execute tasks in a self-directed fashion. We use promptengineering only and Flan-UL2 model as-is without fine-tuning.
Conclusion In this post, we shared how the AWS GenAIIC team used Anthropic’s Claude on Amazon Bedrock to extract and summarize insights from Vidmob’s performance data using zero-shot promptengineering. He specializes in building ML pipelines using LargeLanguageModels, primarily through Amazon Bedrock and other AWS Cloud services.
As promptengineering is fundamentally different from training machine learning models, Comet has released a new SDK tailored for this use case comet-llm. In this article you will learn how to log the YOLOPandas prompts with comet-llm, keep track of the number of tokens used in USD($), and log your metadata.
Nowadays, the majority of our customers is excited about largelanguagemodels (LLMs) and thinking how generative AI could transform their business. However, bringing such solutions and models to the business-as-usual operations is not an easy task. Only promptengineering is necessary for better results.
The latest advances in generative artificial intelligence (AI) allow for new automated approaches to effectively analyze large volumes of customer feedback and distill the key themes and highlights. This post explores an innovative application of largelanguagemodels (LLMs) to automate the process of customer review analysis.
Image source: Seven Failure Points When Engineering a Retrieval Augmented Generation System I’ll discuss various optimization techniques sourced from different research papers. The majority of these techniques will be based on a research paper I particularly enjoyed, titled “ Retrieval-Augmented Generation for LargeLanguageModels: A Survey.”
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content