This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The programme includes the joint development of Managed LargeLanguageModel Services with service partners, leveraging the company’s generative AI capabilities. Photo by Hannah Busing ) See also: Alibaba Marco-o1: Advancing LLM reasoning capabilities Want to learn more about AI and big data from industry leaders?
A new study from the AI Disclosures Project has raised questions about the data OpenAI uses to train its largelanguagemodels (LLMs). The research indicates the GPT-4o model from OpenAI demonstrates a “strong recognition” of paywalled and copyrighted data from O’Reilly Media books.
LargeLanguageModels (LLMs) have shown remarkable capabilities across diverse natural language processing tasks, from generating text to contextual reasoning. These challenges have driven researchers to seek more efficient ways to enhance LLM performance while minimizing resource demands.
SK Telecom and Deutsche Telekom have officially inked a Letter of Intent (LOI) to collaborate on developing a specialised LLM (LargeLanguageModel) tailored for telecommunication companies. Explore other upcoming enterprise technology events and webinars powered by TechForge here.
Speaker: Shreya Rajpal, Co-Founder and CEO at Guardrails AI & Travis Addair, Co-Founder and CTO at Predibase
LargeLanguageModels (LLMs) such as ChatGPT offer unprecedented potential for complex enterprise applications. However, productionizing LLMs comes with a unique set of challenges such as model brittleness, total cost of ownership, data governance and privacy, and the need for consistent, accurate outputs.
Researchers at Amazon have trained a new largelanguagemodel (LLM) for text-to-speech that they claim exhibits “emergent” abilities. The 980 million parameter model, called BASE TTS, is the largest text-to-speech model yet created.
Amazon is reportedly making substantial investments in the development of a largelanguagemodel (LLM) named Olympus. According to Reuters , the tech giant is pouring millions into this project to create a model with a staggering two trillion parameters.
Mistral AI, a France-based startup, has introduced a new largelanguagemodel (LLM) called Mistral Large that it claims can compete with several top AI systems on the market. Explore other upcoming enterprise technology events and webinars powered by TechForge here.
Meta has introduced Llama 3 , the next generation of its state-of-the-art open source largelanguagemodel (LLM). The tech giant claims Llama 3 establishes new performance benchmarks, surpassing previous industry-leading models like GPT-3.5 in real-world scenarios.
It employs disaggregated serving, a technique that separates the processing and generation phases of largelanguagemodels (LLMs) onto distinct GPUs. “To enable a future of custom reasoning AI, NVIDIA Dynamo helps serve these models at scale, driving cost savings and efficiencies across AI factories.”
Derivative works, such as using DeepSeek-R1 to train other largelanguagemodels (LLMs), are permitted. However, users of specific distilled models should ensure compliance with the licences of the original base models, such as Apache 2.0 and Llama3 licences.
As you look to secure a LLM, the important thing to note is the model changes. And when we talk about model change, it’s not like it’s a revision this week maybe [developers are] using Anthropic, next week they may be using Gemini. The post Cisco: Securing enterprises in the AI era appeared first on AI News.
The neural network architecture of largelanguagemodels makes them black boxes. Neither data scientists nor developers can tell you how any individual model weight impacts its output; they often cant reliably predict how small changes in the input will change the output. They use a process called LLM alignment.
However, traditional deep learning methods often struggle to interpret the semantic details in log data, typically in natural language. LLMs, like GPT-4 and Llama 3, have shown promise in handling such tasks due to their advanced language comprehension. If you like our work, you will love our newsletter.
The latest release of MLPerf Inference introduces new LLM and recommendation benchmarks, marking a leap forward in the realm of AI testing. An updated recommender benchmark – refined to align more closely with industry practices – employs the DLRM-DCNv2 reference model and larger datasets, attracting nine submissions.
Until recently, existing largelanguagemodels (LLMs) have lacked the precision, reliability, and domain-specific knowledge required to effectively support defense and security operations. By leveraging sophisticated models fine-tuned for defense-related applications, this collaboration is poised to provide the U.S.
According to Meta’s claims, these models “outperform open source chat models on most benchmarks we tested.” ” The release of Llama 2 marks a turning point in the LLM (largelanguagemodel) market and has already caught the attention of industry experts and enthusiasts alike.
Databricks has announced the launch of DBRX, a powerful new open-source largelanguagemodel that it claims sets a new bar for open models by outperforming established options like GPT-3.5 It even outperforms Anthropic’s closed-source model Claude on certain benchmarks. on industry benchmarks.
Inflection , an AI startup aiming to create “personal AI for everyone”, has announced a new largelanguagemodel dubbed Inflection-2 that beats Google’s PaLM 2. However, early benchmarks show Inflection-2 outperforming Google’s model on tests of reasoning ability, factual knowledge, and stylistic prowess.
This new tool, LLM Suite, is being hailed as a game-changer and is capable of performing tasks traditionally assigned to research analysts. According to an internal memo obtained by the Financial Times , JPMorgan has granted employees in its asset and wealth management division access to this largelanguagemodel platform.
Sony Research and AI Singapore (AISG) will collaborate on research for the SEA-LION family of largelanguagemodels (LLMs). SEA-LION, which stands for Southeast Asian Languages In One Network, aims to improve the accuracy and capability of AI models when processing languages from the region.
” The lawsuit is the latest legal action taken against Microsoft and OpenAI over their alleged misuse of copyrighted content to build largelanguagemodels (LLMs) that power AI technologies like ChatGPT. Explore other upcoming enterprise technology events and webinars powered by TechForge here.
Anthropic will use the chips to efficiently scale its powerful Claude largelanguagemodel, which ranks only behind GPT-4 in many benchmarks. Photo by charlesdeluvio on Unsplash ) See also: Amazon is building a LLM to rival OpenAI and Google Want to learn more about AI and big data from industry leaders?
Photo by Brett Jordan on Unsplash ) See also: Amazon trains 980M parameter LLM with ’emergent abilities’ Want to learn more about AI and big data from industry leaders? Explore other upcoming enterprise technology events and webinars powered by TechForge here.
LLM Agents Learning Platform A unique course focusing on leveraging largelanguagemodels (LLMs) to create advanced AI agents for diverse applications. AI Agents in LangGraph A deep dive into integrating AI agents within LangGraph, emphasizing scalability and robustness in AI solutions.
In addition to these measures, the advisory orders all intermediaries or platforms to ensure that any AI model product – including largelanguagemodels (LLM) – does not permit bias, discrimination, or threaten the integrity of the electoral process.
Utilizing LargeLanguageModels (LLMs) through different prompting strategies has become popular in recent years. Differentiating prompts in multi-turn interactions, which involve several exchanges between the user and model, is a crucial problem that remains mostly unresolved.
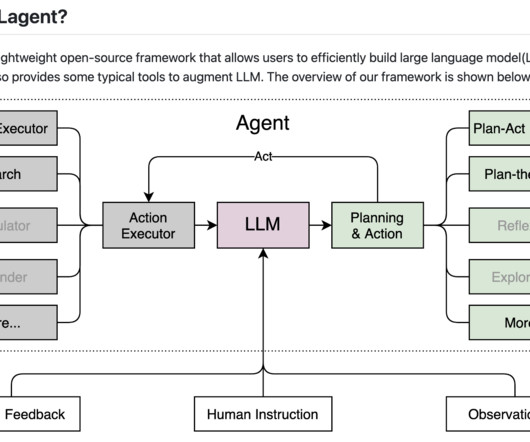
Introducing Lagent, a new open-source framework that simplifies the process of building largelanguagemodel (LLM)-based agents. Lagent stands out by offering a lightweight and flexible solution that supports various models and provides tools to enhance the capabilities of LLMs.
Last year, SK Telecom invested $100 million in AI startup Anthropic to develop a largelanguagemodel (LLM) specifically for telcos. Photo by Natalie Pedigo ) See also: Meta raises the bar with open source Llama 3 LLM Want to learn more about AI and big data from industry leaders? billion globally.
Researchers have introduced a novel approach called natural language embedded programs (NLEPs) to improve the numerical and symbolic reasoning capabilities of largelanguagemodels (LLMs). Explore other upcoming enterprise technology events and webinars powered by TechForge here.
OpenAI has announced that its GPT Store, a platform where users can sell and share custom AI agents created using OpenAI’s GPT-4 largelanguagemodel, will finally launch next week. Explore other upcoming enterprise technology events and webinars powered by TechForge here.
While this is still too large for a single GPU, it can be easily deployed on a server with four to eight GPUs without resorting to quantisation – a feat not necessarily achievable with larger models like GPT-4 or Llama 3.1 In practical terms, this means ML2 can generate responses faster than larger models on the same hardware.
NVIDIA has announced its next-generation Blackwell GPU architecture, designed to usher in a new era of accelerated computing and enable organisations to build and run real-time generative AI on trillion-parameter largelanguagemodels. Explore other upcoming enterprise technology events and webinars powered by TechForge here.
LargeLanguageModels (LLMs), such as the ByT5 model, offer a promising potential for enhancing OCR post-correction. These models are trained on extensive text data and can understand and generate human-like language. If you like our work, you will love our newsletter.
LargeLanguageModels (LLMs) have revolutionized natural language processing, demonstrating remarkable capabilities in various applications. ” These limitations have spurred researchers to explore innovative solutions that can enhance LLM performance without the need for extensive retraining.
Amdocs has partnered with NVIDIA and Microsoft Azure to build custom LargeLanguageModels (LLMs) for the $1.7 Explore other upcoming enterprise technology events and webinars powered by TechForge here. The post Amdocs, NVIDIA and Microsoft Azure build custom LLMs for telcos appeared first on AI News.
He outlined key attributes of neural networks, embeddings, and transformers, focusing on largelanguagemodels as a shared foundation. However, Craven highlighted that largelanguagemodels (LLMs) are powerful summarising engines for research.
In today’s market, the consumption of models is primarily focused on largelanguagemodels (LLMs) for generative AI. In reality, LLMs are a very small part of the modelling needs of real-world production deployments of AI and decision making for businesses.
A breakthrough approach in enhancing the reasoning abilities of largelanguagemodels (LLMs) has been unveiled by researchers from Google DeepMind and the University of Southern California. Explore other upcoming enterprise technology events and webinars powered by TechForge here.
Prior research on LargeLanguageModels (LLMs) demonstrated significant advancements in fluency and accuracy across various tasks, influencing sectors like healthcare and education. This progress sparked investigations into LLMs’ language understanding capabilities and associated risks.
LargeLanguageModels (LLMs) are a subset of artificial intelligence focusing on understanding and generating human language. These models leverage complex architectures to comprehend and produce human-like text, facilitating applications in customer service, content creation, and beyond.
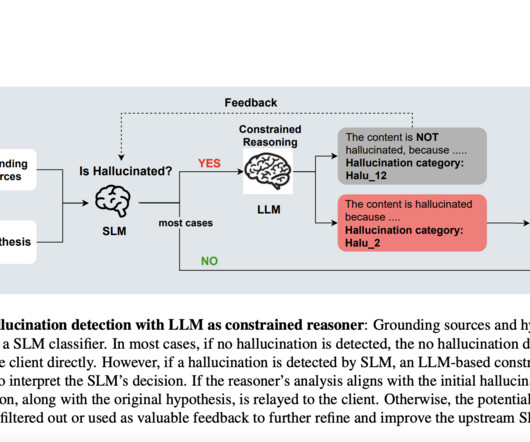
LargeLanguageModels (LLMs) have demonstrated remarkable capabilities in various natural language processing tasks. However, they face a significant challenge: hallucinations, where the models generate responses that are not grounded in the source material.
Stay ahead in the rapidly evolving world of artificial intelligence with our curated selection of webinars this week. Explore the latest advancements in machine learning and largelanguagemodels (LLMs), and discover their practical applications across various industries.
Largelanguagemodels ( LLMs ) like GPT-4, PaLM, Bard, and Copilot have made a huge impact in natural language processing (NLP). These models require vast computational resources, making them expensive to train and deploy. The post What are Small LanguageModels (SLMs)?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content