This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One effective way to improve context relevance is through metadata filtering, which allows you to refine search results by pre-filtering the vector store based on custom metadata attributes. By combining the capabilities of LLM function calling and Pydantic data models, you can dynamically extract metadata from user queries.
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Video data analysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.
As generative AI continues to drive innovation across industries and our daily lives, the need for responsibleAI has become increasingly important. At AWS, we believe the long-term success of AI depends on the ability to inspire trust among users, customers, and society.
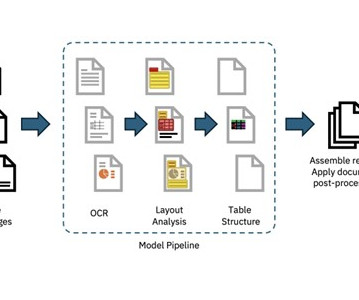
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data. Generate metadata for the page.
Verisk (Nasdaq: VRSK) is a leading strategic data analytics and technology partner to the global insurance industry, empowering clients to strengthen operating efficiency, improve underwriting and claims outcomes, combat fraud, and make informed decisions about global risks.
Database metadata can be expressed in various formats, including schema.org and DCAT. ML data has unique requirements, like combining and extracting data from structured and unstructured sources, having metadata allowing for responsible data use, or describing ML usage characteristics like training, test, and validation sets.
In a world whereaccording to Gartner over 80% of enterprise data is unstructured, enterprises need a better way to extract meaningful information to fuel innovation. With Amazon Bedrock Data Automation, enterprises can accelerate AI adoption and develop solutions that are secure, scalable, and responsible.
An AI-native data abstraction layer acts as a controlled gateway, ensuring your LLMs only access relevant information and follow proper security protocols. It can also enable consistent access to metadata and context no matter what models you are using. AI governance manages three things.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies such as AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsibleAI.
But the implementation of AI is only one piece of the puzzle. The tasks behind efficient, responsibleAI lifecycle management The continuous application of AI and the ability to benefit from its ongoing use require the persistent management of a dynamic and intricate AI lifecycle—and doing so efficiently and responsibly.
Building enhanced semantic search capabilities that analyze media contextually would lay the groundwork for creating AI-generated content, allowing customers to produce customized media more efficiently. With recent advances in large language models (LLMs), Veritone has updated its platform with these powerful new AI capabilities.
In this post, we discuss how to use LLMs from Amazon Bedrock to not only extract text, but also understand information available in images. It also provides a broad set of capabilities to build generative AI applications with security, privacy, and responsibleAI. 90B Vision model.
Weve also added new citation metrics for the already-powerful RAG evaluation suite, including citation precision and citation coverage, to help you better assess how accurately your RAG system uses retrieved information. When evaluating retrieval results from a knowledge base, we allow one knowledge base to be evaluated per evaluation job.
With robust security measures, data privacy safeguards, and a cost-effective pay-as-you-go model, Amazon Bedrock offers a secure, flexible, and cost-efficient service to harness generative AIs potential in enhancing customer service analytics, ultimately leading to improved customer experiences and operational efficiencies.
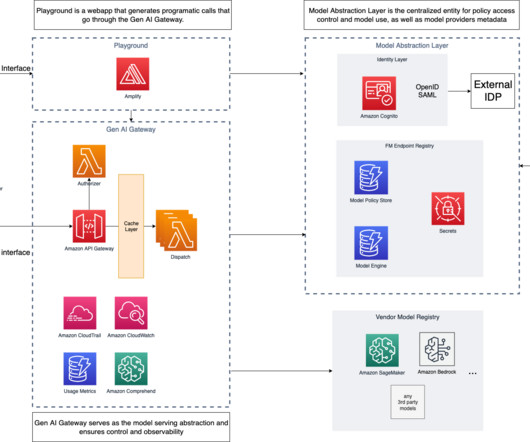
In this second part, we expand the solution and show to further accelerate innovation by centralizing common Generative AI components. We also dive deeper into access patterns, governance, responsibleAI, observability, and common solution designs like Retrieval Augmented Generation. This logic sits in a hybrid search component.
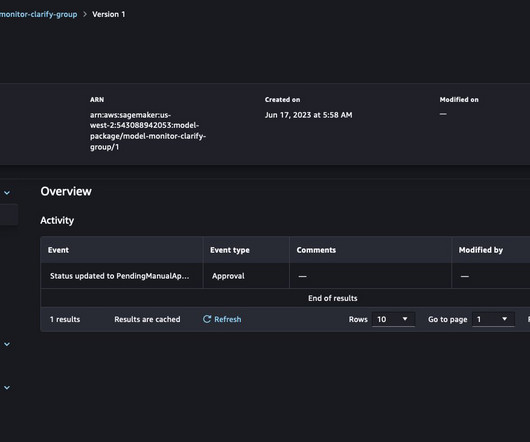
It stores information such as job ID, status, creation time, and other metadata. The following is a screenshot of the DynamoDB table where you can track the job status and other types of metadata related to the job. The invoked Lambda function creates new job entries in a DynamoDB table with the status as Pending.
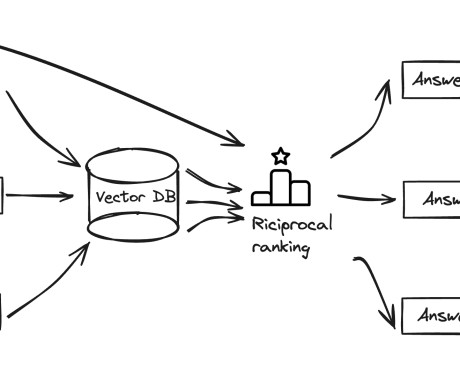
There are two metrics used to evaluate retrieval: Context relevance Evaluates whether the retrieved information directly addresses the querys intent. It requires ground truth texts for comparison to assess recall and completeness of retrieved information. It focuses on precision of the retrieval system.
By implementing this architectural pattern, organizations that use Google Workspace can empower their workforce to access groundbreaking AI solutions powered by Amazon Web Services (AWS) and make informed decisions without leaving their collaboration tool. This request contains the user’s message and relevant metadata.
When extracting the text to a simple format like Markdown, even when the text is identified, a lot of the contextual information is lost, making it difficult to determine the context of a text with high-accuracy for advanced NLPtasks. As the screenshot below shows, the context information derived from the original layout is completely lost.
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. Today, generative AI can help bridge this knowledge gap for nontechnical users to generate SQL queries by using a text-to-SQL application.
While these models are trained on vast amounts of generic data, they often lack the organization-specific context and up-to-date information needed for accurate responses in business settings. By implementing this technique, organizations can improve response accuracy, reduce response times, and lower costs.
You can use advanced parsing options supported by Amazon Bedrock Knowledge Bases for parsing non-textual information from documents using FMs. Some documents benefit from semantic chunking by preserving the contextual relationship in the chunks, helping make sure that the related information stays together in logical chunks.
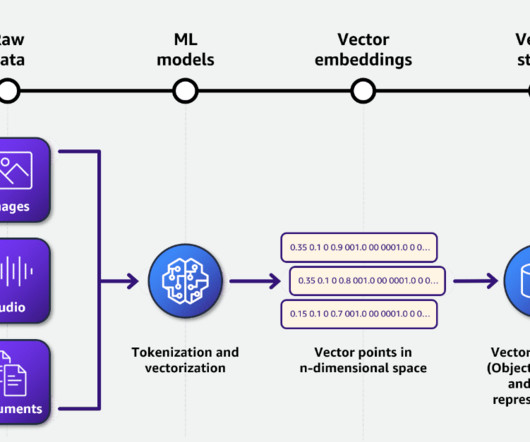
A reverse image search engine enables users to upload an image to find related information instead of using text-based queries. For more information on managing credentials securely, see the AWS Boto3 documentation. The closer vectors are to one another in this space, the more similar the information they represent is.
AI governance refers to the practice of directing, managing and monitoring an organization’s AI activities. It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. Generative AI chatbots have been known to insult customers and make up facts.
Regular interval evaluation also allows organizations to stay informed about the latest advancements, making informed decisions about upgrading or switching models. By investing in robust evaluation practices, companies can maximize the benefits of LLMs while maintaining responsibleAI implementation and minimizing potential drawbacks.
These meetings often involve exchanging information and discussing actions that one or more parties must take after the session. For further information on how you can use Amazon Bedrock for your workloads, see Amazon Bedrock. About the Authors Simone Zucchet is a Solutions Architect Manager at AWS.
Inspect Rich Documents with Gemini Multimodality and Multimodal RAG This course covers using multimodal prompts to extract information from text and visual data and generate video descriptions with Gemini. Introduction to ResponsibleAI This course explains what responsibleAI is, its importance, and how Google implements it in its products.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsibleAI.
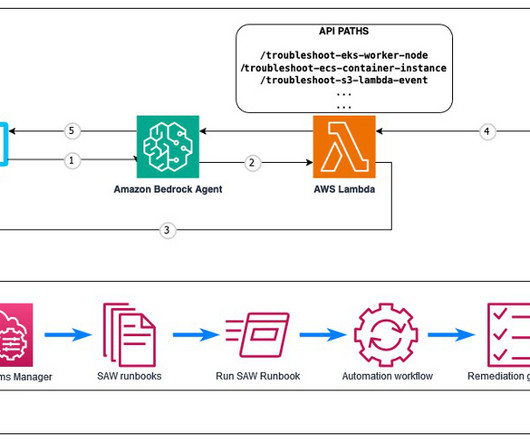
By using prompt instructions and API descriptions, agents collect essential information from API schemas to solve specific problems efficiently. This flexibility is achieved by chaining domain-specific agents like the insurance orchestrator agent, policy information agent, and damage analysis notification agent.
This post provides an overview of a custom solution developed by the AWS Generative AI Innovation Center (GenAIIC) for Deltek , a globally recognized standard for project-based businesses in both government contracting and professional services. Deltek serves over 30,000 clients with industry-specific software and information solutions.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications.
Designed with responsibleAI and data privacy in mind, Jupyter AI empowers users to choose their preferred LLM, embedding model, and vector database to suit their specific needs. Moreover, it saves metadata about model-generated content, facilitating tracking of AI-generated code within the workflow.
The results are shown in a Streamlit app, with the invoices and extracted information displayed side-by-side for quick review. After uploading, you can set up a regular batch job to process these invoices, extract key information, and save the results in a JSON file. Importantly, your document and data are not stored after processing.
For example, if Retrieval Augmented Generation (RAG)-based applications accidentally include personally identifiable information (PII) data in context, such issues need to be detected in real time. This table will hold the endpoint, metadata, and configuration parameters for the model.
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Can you compare images?
To ensure the highest quality measurement of your question answering application against ground truth, the evaluation metrics implementation must inform ground truth curation. To learn more about FMEval, see Evaluate large language models for quality and responsibility of LLMs.
Evolving Trends in Prompt Engineering for Large Language Models (LLMs) with Built-in ResponsibleAI Practices Editor’s note: Jayachandran Ramachandran and Rohit Sroch are speakers for ODSC APAC this August 22–23. As LLMs become integral to AI applications, ethical considerations take center stage.
It’s a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like Anthropic, Cohere, Meta, Mistral AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsibleAI.
Existing methods for sharing AI models often involve releasing only selected elements, such as the final trained model and weights, without comprehensive documentation or clear licensing. Each component must be released under open licenses suitable for its type, such as OSI-approved licenses for code and CDLA-Permissive for data.
Information retrieval systems have powered the information age through their ability to crawl and sift through massive amounts of data and quickly return accurate and relevant results. Finding relevant content usually requires searching through text-based metadata such as timestamps, which need to be manually added to these files.
The media organization delivers useful, relevant, and accessible information to an audience that consists primarily of young and active urban readers. million 25–49-year-olds choose 20 Minutes to stay informed. This blog post outlines various use cases where we’re using generative AI to address digital publishing challenges.
Model cards are intended to be a single source of truth for business and technical metadata about the model that can reliably be used for auditing and documentation purposes. The model registry supports a hierarchical structure for organizing and storing ML models with model metadatainformation.
Although they can retrieve relevant information, they may struggle to generate complete and coherent responses when required information is absent, leading to incomplete or inaccurate outputs. For more information about data access, refer to Data access control for Amazon OpenSearch Serverless. split('.')[0]}.json"
Data security is very important for organizations as they need their clients to trust them with their sensitive information. The organizations are solely responsible for protecting the entrusted data from unauthorized access and misuse. This is done to prevent the misuse of information against a particular individual or a group.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content