This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Furthermore, it might contain sensitive data or personally identifiable information (PII) requiring redaction.
The evolution of Large Language Models (LLMs) allowed for the next level of understanding and information extraction that classical NLP algorithms struggle with. This article will focus on LLM capabilities to extract meaningful metadata from product reviews, specifically using OpenAI API. pros** (`List[str]`).
Prompts are changed by introducing spelling errors, replacing synonyms, concatenating irrelevant information or translating from a different language. link] The paper proposes query rewriting as the solution to the problem of LLMs being overly affected by irrelevant information in the prompts. Character-level attacks rank second.
Structured data, defined as data following a fixed pattern such as information stored in columns within databases, and unstructured data, which lacks a specific form or pattern like text, images, or social media posts, both continue to grow as they are produced and consumed by various organizations.
In the rapidly evolving healthcare landscape, patients often find themselves navigating a maze of complex medical information, seeking answers to their questions and concerns. However, accessing accurate and comprehensible information can be a daunting task, leading to confusion and frustration.
To prevent these scenarios, protection of data, user assets, and identity information has been a major focus of the blockchain security research community, as to ensure the development of the blockchain technology, it is essential to maintain its security.
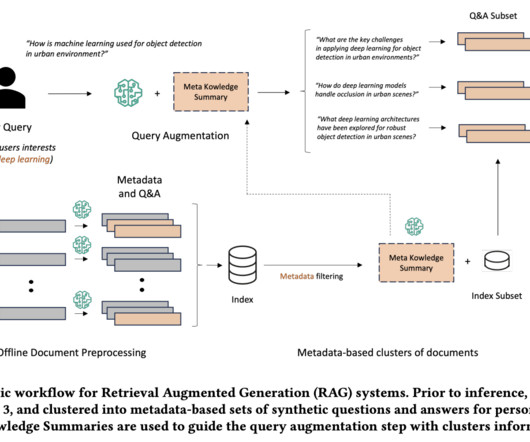
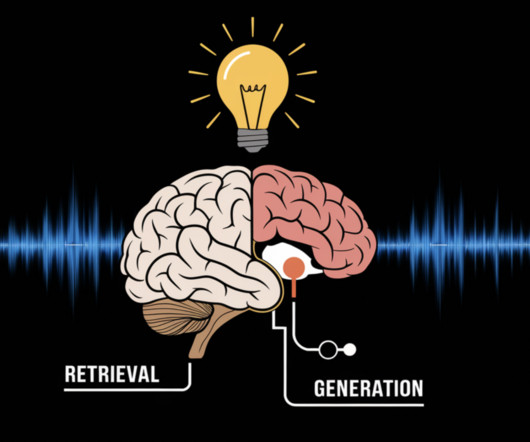
Retrieval Augmented Generation (RAG) represents a cutting-edge advancement in Artificial Intelligence, particularly in NLP and Information Retrieval (IR). This integration allows LLMs to perform more accurately and effectively in knowledge-intensive tasks, especially where proprietary or up-to-date information is crucial.
We are delighted to announce a suite of remarkable enhancements and updates in our latest release of Healthcare NLP. """ Result: Please check the ner_section_header_ diagnosis model card for more information. Unleash the full potential of your NLP model with these cutting-edge additions to the AssertionDLModel.
This new capability integrates the power of graph data modeling with advanced natural language processing (NLP). By linking this contextual information, the generative AI system can provide responses that are more complete, precise, and grounded in source data. Configure your knowledge base by adding filters or guardrails.
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset data model. Unstructured information may have a little or a lot of structure but in ways that are unexpected or inconsistent. A metadata layer helps build the relationship between the raw data and AI extracted output.
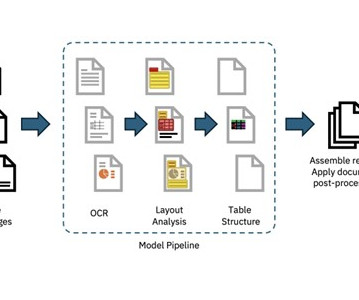
Solving this for traditional NLP problems or retrieval systems, or extracting knowledge from the documents to train models, continues to be challenging. As the screenshot below shows, the context information derived from the original layout is completely lost. The markdown version can encode the image inline and extract thetext.
This capability enables organizations to create custom inference profiles for Bedrock base foundation models, adding metadata specific to tenants, thereby streamlining resource allocation and cost monitoring across varied AI applications. He focuses on Deep learning including NLP and Computer Vision domains.
Large language models (LLMs) have unlocked new possibilities for extracting information from unstructured text data. This post walks through examples of building information extraction use cases by combining LLMs with prompt engineering and frameworks such as LangChain.
A significant challenge with question-answering (QA) systems in Natural Language Processing (NLP) is their performance in scenarios involving extensive collections of documents that are structurally similar or ‘indistinguishable.’
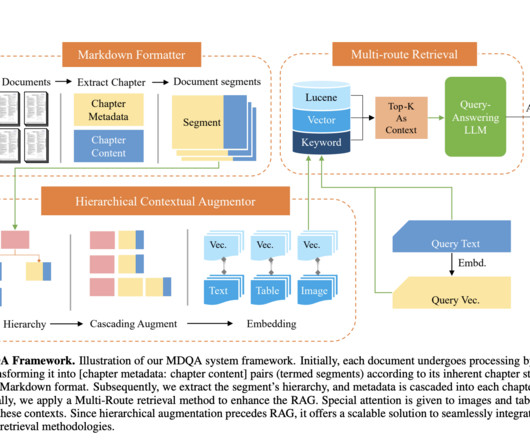
There is also the challenge of privacy and data security, as the information provided in the prompt could potentially be sensitive or confidential. On the other hand, a Node is a snippet or “chunk” from a Document, enriched with metadata and relationships to other nodes, ensuring a robust foundation for precise data retrieval later on.
Summary: The Information Retrieval system enables you to quickly find relevant information about. It goes beyond simple keyword matching by understanding the context of your query and ranking documents based on their relevance to your information needs. Earlier, our scope of information was limited to books and research papers.
Investment professionals face the mounting challenge of processing vast amounts of data to make timely, informed decisions. This challenge is particularly acute in credit markets, where the complexity of information and the need for quick, accurate insights directly impacts investment outcomes.
In Natural Language Processing (NLP) tasks, data cleaning is an essential step before tokenization, particularly when working with text data that contains unusual word separations such as underscores, slashes, or other symbols in place of spaces. The post Is There a Library for Cleaning Data before Tokenization?
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. Most of today’s largest foundation models, including the large language model (LLM) powering ChatGPT, have been trained on information culled from the internet. But how trustworthy is that training data?
Automated Reasoning checks help prevent factual errors from hallucinations using sound mathematical, logic-based algorithmic verification and reasoning processes to verify the information generated by a model, so outputs align with provided facts and arent based on hallucinated or inconsistent data.
Voice-based queries use natural language processing (NLP) and sentiment analysis for speech recognition so their conversations can begin immediately. With text to speech and NLP, AI can respond immediately to texted queries and instructions. Humanize HR AI can attract, develop and retain a skills-first workforce.
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. With multiple families in plan, the first release is the Slate family of models, which represent an encoder-only architecture.
However, as technology advanced, so did the complexity and capabilities of AI music generators, paving the way for deep learning and Natural Language Processing (NLP) to play pivotal roles in this tech. Initially, the attempts were simple and intuitive, with basic algorithms creating monotonous tunes.
Using natural language processing (NLP) and OpenAPI specs, Amazon Bedrock Agents dynamically manages API sequences, minimizing dependency management complexities. By using prompt instructions and API descriptions, agents collect essential information from API schemas to solve specific problems efficiently.
They aim to decrypt or recover as much hidden or deleted information as possible. Since devices store information every time their user downloads something, visits a website or creates a post, a sort of electronic paper trail exits. Investigators can train or prompt it to seek case-specific information.
From predicting traffic flow to sales forecasting, accurate predictions enable organizations to make informed decisions, mitigate risks, and allocate resources efficiently. It stores models, organizes model versions, captures essential metadata and artifacts such as container images, and governs the approval status of each model.
This method of enriching the LLM generation context with information retrieved from your internal data sources is called Retrieval Augmented Generation (RAG), and produces assistants that are domain specific and more trustworthy, as shown by Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
Scientific metadata in research literature holds immense significance, as highlighted by flourishing research in scientometricsa discipline dedicated to analyzing scholarly literature. Metadata improves the findability and accessibility of scientific documents by indexing and linking papers in a massive graph.
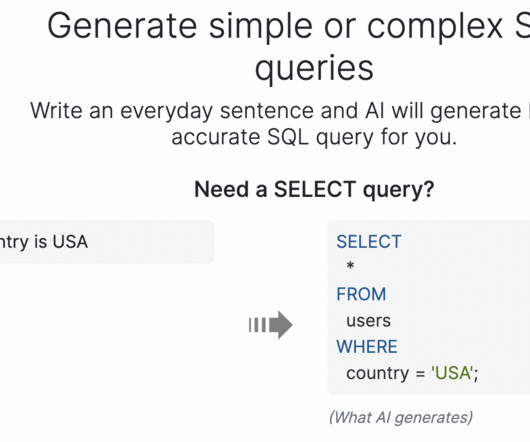
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. This generative AI task is called text-to-SQL, which generates SQL queries from natural language processing (NLP) and converts text into semantically correct SQL. Today, generative AI can enable people without SQL knowledge.
Inspect Rich Documents with Gemini Multimodality and Multimodal RAG This course covers using multimodal prompts to extract information from text and visual data and generate video descriptions with Gemini. Natural Language Processing on Google Cloud This course introduces Google Cloud products and solutions for solving NLP problems.
The emergence of generative AI agents in recent years has contributed to the transformation of the AI landscape, driven by advances in large language models (LLMs) and natural language processing (NLP). This approach allows businesses to offload repetitive and time-consuming tasks in a controlled, predictable manner.
What is Clinical Data Abstraction Creating large-scale structured datasets containing precise clinical information on patient itineraries is a vital tool for medical care providers, healthcare insurance companies, hospitals, medical research, clinical guideline creation, and real-world evidence.
First, you extract label and celebrity metadata from the images, using Amazon Rekognition. You then generate an embedding of the metadata using a LLM. You store the celebrity names, and the embedding of the metadata in OpenSearch Service. Overview of solution The solution is divided into two main sections.
John Snow Labs, the Healthcare AI and NLP company and developer of the Spark NLP library, is pleased to announce the general availability of its comprehensive Healthcare Data Library on the Databricks Marketplace. The data is regularly updated, and is available in a variety of formats with enriched metadata.
RAG combines the capabilities of LLMs with the strengths of traditional information retrieval systems such as databases to help AI write more accurate and relevant text. LLMs are crucial for driving intelligent chatbots and other NLP applications. This is done using mathematical vector calculations and representations.
The recent NLP Summit served as a vibrant platform for experts to delve into the many opportunities and also challenges presented by large language models (LLMs). At the recent NLP Summit, experts from academia and industry shared their insights. solves this problem by extracting metadata during the data preparation process.
It enables machines to process massive amounts of data and make informed decisions. In this article, we will discuss the use of Clinical NLP in understanding the rich meaning that lies behind the doctor’s written analysis (clinical documents/notes) of patients. the clinical NLP system should be able to detect it.
Large language models (LLMs) are revolutionizing fields like search engines, natural language processing (NLP), healthcare, robotics, and code generation. The personalization of LLM applications can be achieved by incorporating up-to-date user information, which typically involves integrating several components.
Let’s start with a brief introduction to Spark NLP and then discuss the details of pretrained pipelines with some concrete results. Spark NLP & LLM The Healthcare Library is a powerful component of John Snow Labs’ Spark NLP platform, designed to facilitate NLP tasks within the healthcare domain.
It interprets user input and generates suitable responses using artificial intelligence (AI) and natural language processing (NLP). It necessitates a thorough knowledge of natural language processing (NLP) methods. In this article, you will learn how to use RL and NLP to create an entire chatbot system. Why is NLP Required?
The Normalizer annotator in Spark NLP performs text normalization on data. The Normalizer annotator in Spark NLP is often used as part of a preprocessing step in NLP pipelines to improve the accuracy and quality of downstream analyses and models. These transformations can be configured by the user to meet their specific needs.
Rule-based sentiment analysis in Natural Language Processing (NLP) is a method of sentiment analysis that uses a set of manually-defined rules to identify and extract subjective information from text data. Using Spark NLP, it is possible to analyze the sentiment in a text with high accuracy.
Artificial intelligence chatbots have been trained to have conversations that resemble those of humans using natural language processing (NLP). NLP enables the AI chatbot to comprehend written human language, allowing them to function independently. From user-provided natural language words, AI Bot creates SQL JOIN statements.
Stopwords removal in natural language processing (NLP) is the process of eliminating words that occur frequently in a language but carry little or no meaning. Stopwords cleaning in Spark NLP is the process of removing stopwords from the text data. Stopwords are commonly occurring words (like the, a, and, in , etc.)
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content