This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
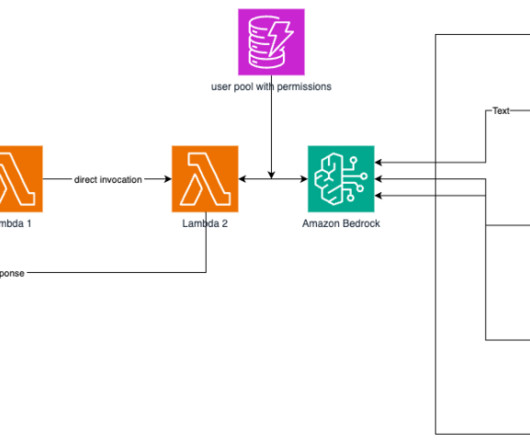
One effective way to improve context relevance is through metadata filtering, which allows you to refine search results by pre-filtering the vector store based on custom metadata attributes. By combining the capabilities of LLM function calling and Pydantic data models, you can dynamically extract metadata from user queries.
Despite advances in image and text-based AI research, the audio domain lags due to the absence of comprehensive datasets comparable to those available for computer vision or naturallanguageprocessing. The alignment of metadata to each audio clip provides valuable contextual information, facilitating more effective learning.
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data. Generate metadata for the page.
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive.
This new capability integrates the power of graph data modeling with advanced naturallanguageprocessing (NLP). By linking this contextual information, the generative AI system can provide responses that are more complete, precise, and grounded in source data.
Verisk (Nasdaq: VRSK) is a leading strategic data analytics and technology partner to the global insurance industry, empowering clients to strengthen operating efficiency, improve underwriting and claims outcomes, combat fraud, and make informed decisions about global risks.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services.
They are crucial for machine learning applications, particularly those involving naturallanguageprocessing and image recognition. Often support for metadata filtering alongside vector search Popular vector databases include FAISS (Facebook AI Similarity Search), Pinecone, Weaviate, Milvus, and Chroma.
Structured data, defined as data following a fixed pattern such as information stored in columns within databases, and unstructured data, which lacks a specific form or pattern like text, images, or social media posts, both continue to grow as they are produced and consumed by various organizations.
BedrockKBRetrieverTool enables CrewAI agents to retrieve information from Amazon Bedrock Knowledge Bases using naturallanguage queries. With Amazon Bedrock Knowledge Bases , you can securely connect FMs and agents to your company data to deliver more relevant, accurate, and customized responses.
In a world whereaccording to Gartner over 80% of enterprise data is unstructured, enterprises need a better way to extract meaningful information to fuel innovation. This ability to toggle between extraction types enables more comprehensive and nuanced data processing across various document types.
From predicting traffic flow to sales forecasting, accurate predictions enable organizations to make informed decisions, mitigate risks, and allocate resources efficiently. It stores models, organizes model versions, captures essential metadata and artifacts such as container images, and governs the approval status of each model.
This approach has two primary shortcomings: Missed Contextual Signals : Without considering metadata such as source URLs, LMs overlook important contextual information that could guide their understanding of a texts intent or quality. MeCo leverages readily available metadata, such as source URLs, during the pre-training phase.
To prevent these scenarios, protection of data, user assets, and identity information has been a major focus of the blockchain security research community, as to ensure the development of the blockchain technology, it is essential to maintain its security.
Large language models (LLMs) have unlocked new possibilities for extracting information from unstructured text data. This post walks through examples of building information extraction use cases by combining LLMs with prompt engineering and frameworks such as LangChain.
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset data model. Unstructured information may have a little or a lot of structure but in ways that are unexpected or inconsistent. A metadata layer helps build the relationship between the raw data and AI extracted output.
A significant challenge with question-answering (QA) systems in NaturalLanguageProcessing (NLP) is their performance in scenarios involving extensive collections of documents that are structurally similar or ‘indistinguishable.’ Check out the Paper and Github.
While these models are trained on vast amounts of generic data, they often lack the organization-specific context and up-to-date information needed for accurate responses in business settings. This offline batch process makes sure that the semantic cache remains up-to-date without impacting real-time operations.
Automated Reasoning checks help prevent factual errors from hallucinations using sound mathematical, logic-based algorithmic verification and reasoning processes to verify the information generated by a model, so outputs align with provided facts and arent based on hallucinated or inconsistent data.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. Most of today’s largest foundation models, including the large language model (LLM) powering ChatGPT, have been trained on information culled from the internet. Trustworthiness is critical.
So, instead of wandering the aisles in hopes you’ll stumble across the book, you can walk straight to it and get the information you want much faster. It uses metadata and data management tools to organize all data assets within your organization. Weeks pass by until the IT team locates and masks the data. Speed and self-service.
Despite their capabilities, AI & ML models are not perfect, and scientists are working towards building models that are capable of learning from the information they are given, and not necessarily relying on labeled or annotated data. However, this approach needs to filter images, and it works best only when a textual metadata is present.
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. Encoder-decoder and decoder-only large language models are available in the Prompt Lab today. To bridge the tuning gap, watsonx.ai
You can use advanced parsing options supported by Amazon Bedrock Knowledge Bases for parsing non-textual information from documents using FMs. Some documents benefit from semantic chunking by preserving the contextual relationship in the chunks, helping make sure that the related information stays together in logical chunks.
However, as technology advanced, so did the complexity and capabilities of AI music generators, paving the way for deep learning and NaturalLanguageProcessing (NLP) to play pivotal roles in this tech. Initially, the attempts were simple and intuitive, with basic algorithms creating monotonous tunes.
In the rapidly evolving healthcare landscape, patients often find themselves navigating a maze of complex medical information, seeking answers to their questions and concerns. However, accessing accurate and comprehensible information can be a daunting task, leading to confusion and frustration.
Investment professionals face the mounting challenge of processing vast amounts of data to make timely, informed decisions. This challenge is particularly acute in credit markets, where the complexity of information and the need for quick, accurate insights directly impacts investment outcomes.
In NaturalLanguageProcessing (NLP) tasks, data cleaning is an essential step before tokenization, particularly when working with text data that contains unusual word separations such as underscores, slashes, or other symbols in place of spaces.
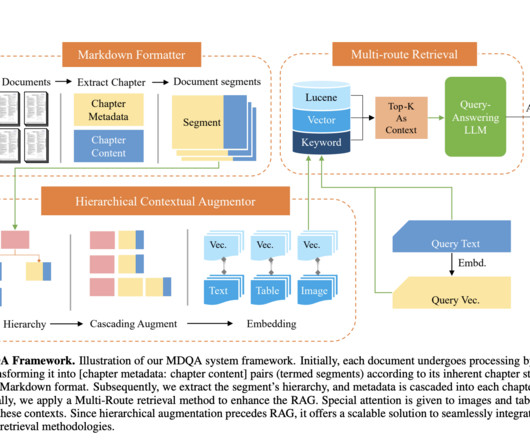
Advanced parsing Advanced parsing is the process of analyzing and extracting meaningful information from unstructured or semi-structured documents. It involves breaking down the document into its constituent parts, such as text, tables, images, and metadata, and identifying the relationships between these elements.
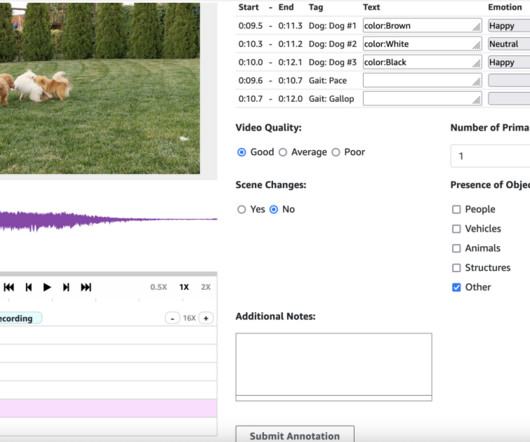
In this article, we will discuss the top Text Annotation tools for NaturalLanguageProcessing along with their characteristic features. Overview of Text Annotation Human language is highly diverse and is sometimes hard to decode for machines. It annotates images, videos, text documents, audio, and HTML, etc.
Using naturallanguageprocessing (NLP) and OpenAPI specs, Amazon Bedrock Agents dynamically manages API sequences, minimizing dependency management complexities. By using prompt instructions and API descriptions, agents collect essential information from API schemas to solve specific problems efficiently.
Inspect Rich Documents with Gemini Multimodality and Multimodal RAG This course covers using multimodal prompts to extract information from text and visual data and generate video descriptions with Gemini. NaturalLanguageProcessing on Google Cloud This course introduces Google Cloud products and solutions for solving NLP problems.
By understanding its significance, readers can grasp how it empowers advancements in AI and contributes to cutting-edge innovation in naturallanguageprocessing. Its mix of technical, academic, and informal content provides a comprehensive linguistic representation.
The emergence of generative AI agents in recent years has contributed to the transformation of the AI landscape, driven by advances in large language models (LLMs) and naturallanguageprocessing (NLP). This approach allows businesses to offload repetitive and time-consuming tasks in a controlled, predictable manner.
Large language models (LLMs) are revolutionizing fields like search engines, naturallanguageprocessing (NLP), healthcare, robotics, and code generation. The personalization of LLM applications can be achieved by incorporating up-to-date user information, which typically involves integrating several components.
They aim to decrypt or recover as much hidden or deleted information as possible. Since devices store information every time their user downloads something, visits a website or creates a post, a sort of electronic paper trail exits. Investigators can train or prompt it to seek case-specific information.
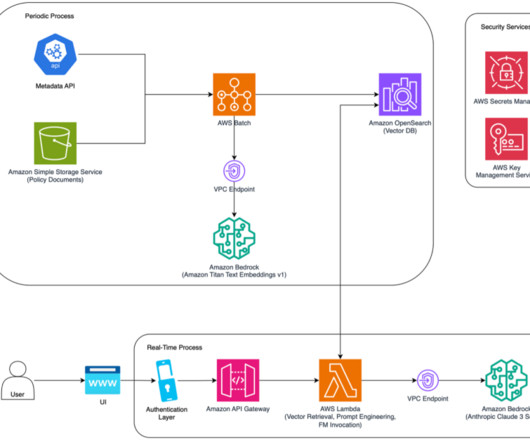
First, you extract label and celebrity metadata from the images, using Amazon Rekognition. You then generate an embedding of the metadata using a LLM. You store the celebrity names, and the embedding of the metadata in OpenSearch Service. Overview of solution The solution is divided into two main sections.
Scientific metadata in research literature holds immense significance, as highlighted by flourishing research in scientometricsa discipline dedicated to analyzing scholarly literature. Metadata improves the findability and accessibility of scientific documents by indexing and linking papers in a massive graph.
Sonnet model for naturallanguageprocessing. For example, we export pre-chunked asset metadata from our asset library to Amazon S3, letting Amazon Bedrock handle embeddings, vector storage, and search. The system adeptly handles ambiguous queries, extracting relevant information and intent.
By leveraging MLLM, these agents can process and synthesize vast amounts of information from various modalities, enabling them to offer personalized assistance and enhance user experiences in ways previously unimaginable. This expansion ensures that more information is preserved, aiding in decision-making.
We start with a simple scenario: you have an audio file stored in Amazon S3, along with some metadata like a call ID and its transcription. What feature would you like to see added ? " } You can adapt this structure to include additional metadata that your annotation workflow requires.
This method of enriching the LLM generation context with information retrieved from your internal data sources is called Retrieval Augmented Generation (RAG), and produces assistants that are domain specific and more trustworthy, as shown by Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. This generative AI task is called text-to-SQL, which generates SQL queries from naturallanguageprocessing (NLP) and converts text into semantically correct SQL. We use Anthropic Claude v2.1
Summary: The Information Retrieval system enables you to quickly find relevant information about. It goes beyond simple keyword matching by understanding the context of your query and ranking documents based on their relevance to your information needs. It is fueling the decision-making process in the organisation.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content