This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To serve their customers, Vitech maintains a repository of information that includes product documentation (user guides, standard operating procedures, runbooks), which is currently scattered across multiple internal platforms (for example, Confluence sites and SharePoint folders). langsmith==0.0.43 pgvector==0.2.3 streamlit==1.28.0
Regular interval evaluation also allows organizations to stay informed about the latest advancements, making informed decisions about upgrading or switching models. This allows you to keep track of your ML experiments. In this post, we show how to use FMEval and Amazon SageMaker to programmatically evaluate LLMs.
The SageMaker endpoint (which includes the custom inference code to preprocesses the multi-payload request) passes the inference data to the ML model, postprocesses the predictions, and sends a response to the user or application. The information pertaining to the request and response is stored in Amazon S3.
Machine learning (ML) engineers must make trade-offs and prioritize the most important factors for their specific use case and business requirements. You can use advanced parsing options supported by Amazon Bedrock Knowledge Bases for parsing non-textual information from documents using FMs.
In the rapidly evolving healthcare landscape, patients often find themselves navigating a maze of complex medical information, seeking answers to their questions and concerns. However, accessing accurate and comprehensible information can be a daunting task, leading to confusion and frustration.
In this post, we introduce an example to help DevOps engineers manage the entire ML lifecycle—including training and inference—using the same toolkit. Solution overview We consider a use case in which an MLengineer configures a SageMaker model building pipeline using a Jupyter notebook.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Third, despite the larger adoption of centralized analytics solutions like data lakes and warehouses, complexity rises with different table names and other metadata that is required to create the SQL for the desired sources.
It automatically keeps track of model artifacts, hyperparameters, and metadata, helping you to reproduce and audit model versions. The SageMaker Pipelines decorator feature helps convert local ML code written as a Python program into one or more pipeline steps. See Provisioned Throughput for Amazon Bedrock for more information.
Introduction to AI and Machine Learning on Google Cloud This course introduces Google Cloud’s AI and ML offerings for predictive and generative projects, covering technologies, products, and tools across the data-to-AI lifecycle.
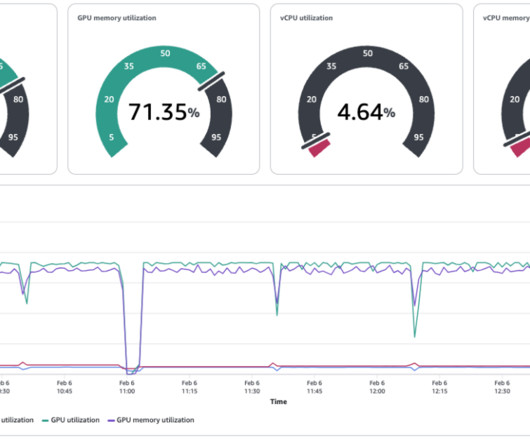
These graphs inform administrators where teams can further maximize their GPU utilization. In this example, the MLengineering team is borrowing 5 GPUs for their training task With SageMaker HyperPod, you can additionally set up observability tools of your choice. queue-name: hyperpod-ns-researchers-localqueue kueue.x-k8s.io/priority-class:
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Can you compare images?
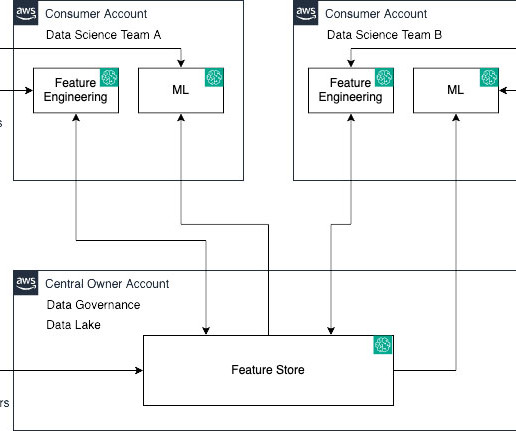
However, model governance functions in an organization are centralized and to perform those functions, teams need access to metadata about model lifecycle activities across those accounts for validation, approval, auditing, and monitoring to manage risk and compliance. An experiment collects multiple runs with the same objective.
An MLengineer deploys the model pipeline into the ML team test environment using a shared services CI/CD process. After stakeholder validation, the ML model is deployed to the team’s production environment. ML operations This module helps LOBs and MLengineers work on their dev instances of the model deployment template.
It is ideal for MLengineers, data scientists, and technical leaders, providing real-world training for production-ready generative AI using Amazon Bedrock and cloud-native services.
This post guides you through the steps to get started with setting up and deploying Studio to standardize ML model development and collaboration with fellow MLengineers and ML scientists. cdk.json – Contains metadata, and feature flags. For more information about Amazon Studio, see Amazon SageMaker Studio.
Let’s demystify this using the following personas and a real-world analogy: Data and MLengineers (owners and producers) – They lay the groundwork by feeding data into the feature store Data scientists (consumers) – They extract and utilize this data to craft their models Data engineers serve as architects sketching the initial blueprint.
If advertisers do not supply this information, the model will infer it based on information from their product listing on amazon.com. Here, Amazon SageMaker Ground Truth allowed MLengineers to easily build the human-in-the-loop workflow (step v).
Unpickling an object can execute malicious code, so it’s crucial to only unpickle information from reliable sources. Cons of Saving ML Models with JSON 1 Because JSON only supports a small number of data types, it could not be compatible with sophisticated machine learning models that employ unique data types.
This is particularly useful for tracking access to sensitive resources such as personally identifiable information (PII), model updates, and other critical activities, enabling enterprises to maintain a robust audit trail and compliance. For more information, see Monitor Amazon Bedrock with Amazon CloudWatch.
During AWS re:Invent 2022, AWS introduced new ML governance tools for Amazon SageMaker which simplifies access control and enhances transparency over your ML projects. For more information about improving governance of your ML models, refer to Improve governance of your machine learning models with Amazon SageMaker.
Came to ML from software. Founded neptune.ai , a modular MLOps component for MLmetadata store , aka “experiment tracker + model registry”. Most of our customers are doing ML/MLOps at a reasonable scale, NOT at the hyperscale of big-tech FAANG companies. . – How about the MLengineer? Let me explain.
Planet and AWS’s partnership on geospatial ML SageMaker geospatial capabilities empower data scientists and MLengineers to build, train, and deploy models using geospatial data. It also contains each scene’s metadata, its image ID, and a preview image reference. Shital Dhakal is a Sr.
Specialist Data Engineering at Merck, and Prabakaran Mathaiyan, Sr. MLEngineer at Tiger Analytics. The large machine learning (ML) model development lifecycle requires a scalable model release process similar to that of software development. This post is co-written with Jayadeep Pabbisetty, Sr.
Fine-tuning an LLM can be a complex workflow for data scientists and machine learning (ML) engineers to operationalize. This enables tracking and reproducibility of experiments across different runs, allowing for more informed decision-making about which models perform best on specific tasks or domains.
Earth.com didn’t have an in-house MLengineering team, which made it hard to add new datasets featuring new species, release and improve new models, and scale their disjointed ML system. It also persists a manifest file to Amazon S3, including all necessary information to recreate that dataset version.
Solution overview Ground Truth is a fully self-served and managed data labeling service that empowers data scientists, machine learning (ML) engineers, and researchers to build high-quality datasets. For our example use case, we work with the Fashion200K dataset , released at ICCV 2017.
By introducing IP-Restricted presigned URLs, SageMaker Ground Truth empowers you with greater control over data access, so sensitive information remains accessible only to authorized workers within approved locations. For more information or assistance, contact your AWS account team or visit the SageMaker community forums.
We’ll see how this architecture applies to different classes of ML systems, discuss MLOps and testing aspects, and look at some example implementations. Understanding machine learning pipelines Machine learning (ML) pipelines are a key component of ML systems. But what is an ML pipeline?
For more information on this and on setting up a pull through cache, see the Neuron Monitor User Guide. He is a rising senior at the University of Pennsylvania pursuing Dual Bachelor’s Degrees in Computer Information Science and Business Analytics in the Jerome Fisher Management and Technology Program. 32xlarge - inf1.xlarge
This post is co-written with Jad Chamoun, Director of Engineering at Forethought Technologies, Inc. and Salina Wu, Senior MLEngineer at Forethought Technologies, Inc. SupportGPT leverages state-of-the-art Information Retrieval (IR) systems and large language models (LLMs) to power over 30 million customer interactions annually.
ML operations, known as MLOps, focus on streamlining, automating, and monitoring ML models throughout their lifecycle. Data scientists, MLengineers, IT staff, and DevOps teams must work together to operationalize models from research to deployment and maintenance. Add the desired GitHub user names as reviewers.
Amazon SageMaker provides purpose-built tools for machine learning operations (MLOps) to help automate and standardize processes across the ML lifecycle. In this post, we describe how Philips partnered with AWS to develop AI ToolSuite—a scalable, secure, and compliant ML platform on SageMaker.
Reports holistically summarize each evaluation in a human-readable way, through natural-language explanations, visualizations, and examples, focusing annotators and data scientists on where to optimize their LLMs and help make informed decisions. What is FMEval? We use datasets such as BoolQ , NaturalQuestions , and TriviaQA.
These types of data are historical raw data from an ML perspective. For example, each log is written in the format of timestamp, user ID, and event information. These are all implemented as a single ML pipeline using Amazon SageMaker Pipelines , and all the ML trainings are managed via Amazon SageMaker Experiments.
help data scientists systematically record, catalog, and analyze modeling artifacts and experiment metadata. But as you can imagine, storing all this information in a reliable, accessible, and intuitive way can be difficult and tedious. Experiment trackers like neptune.ai Even though neptune.ai Aside neptune.ai
You are provided with information about entities the Human mentions, if relevant. A session stores metadata and application-specific data known as session attributes. Ryan Gomes is a Data & MLEngineer with the AWS Professional Services Intelligence Practice. He leads the NYC machine learning and AI meetup.
During AWS re:Invent 2022, AWS introduced new ML governance tools for Amazon SageMaker which simplifies access control and enhances transparency over your ML projects. For more information about improving governance of your ML models, refer to Improve governance of your machine learning models with Amazon SageMaker.
RC : I have had MLengineers tell me, “You didn’t need to do feature selection anymore, and that you could just throw everything at the model and it will figure out what to keep and what to throw away.” So does that mean feature selection is no longer necessary? If not, when should we consider using feature selection?”
RC : I have had MLengineers tell me, “You didn’t need to do feature selection anymore, and that you could just throw everything at the model and it will figure out what to keep and what to throw away.” So does that mean feature selection is no longer necessary? If not, when should we consider using feature selection?”
RC : I have had MLengineers tell me, “You didn’t need to do feature selection anymore, and that you could just throw everything at the model and it will figure out what to keep and what to throw away.” So does that mean feature selection is no longer necessary? If not, when should we consider using feature selection?”
MLflow is an open-source platform designed to manage the entire machine learning lifecycle, making it easier for MLEngineers, Data Scientists, Software Developers, and everyone involved in the process. Machine learning operations (MLOps) are a set of practices that automate and simplify machine learning (ML) workflows and deployments.
By directly integrating with Amazon Managed Service for Prometheus and Amazon Managed Grafana and abstracting the management of hardware failures and job resumption, SageMaker HyperPod allows data scientists and MLengineers to focus on model development rather than infrastructure management. You can find more information on the p4de.24xlarge
We had historical data on past Facebook ads along with the sales information from Shopify. Based on this information, the ad content could be better adjusted to a given target group, resulting in a two times greater conversion rate of Facebook ads. Fast forward a little bit.
So at some point in your project, you need to store all this information so that you can retrieve them whenever needed. So for our project, we created a document containing information about each specific module that we have worked on for example, data collection, data preprocessing and exploration, modeling, deployment, monitoring, etc.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content