This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article dives into design patterns in Python, focusing on their relevance in AI and LLM -based systems. I'll explain each pattern with practical AI use cases and Python code examples. Let’s explore some key design patterns that are particularly useful in AI and machine learning contexts, along with Python examples.
Groq groq Groq is renowned for its high-performance AI inference technology. Their standout product, the Language Processing Units (LPU) InferenceEngine , combines specialized hardware and optimized software to deliver exceptional compute speed, quality, and energy efficiency. per million tokens.
C++ enterprise application for Windows executes a Python module. Image generated by the author using AI tools Intro Python’s simplicity, extensive package ecosystem, and supportive community make it an attractive choice. Frequently, Python code invokes C++ methods for intricate algorithmic calculations. Neither seems optimal.
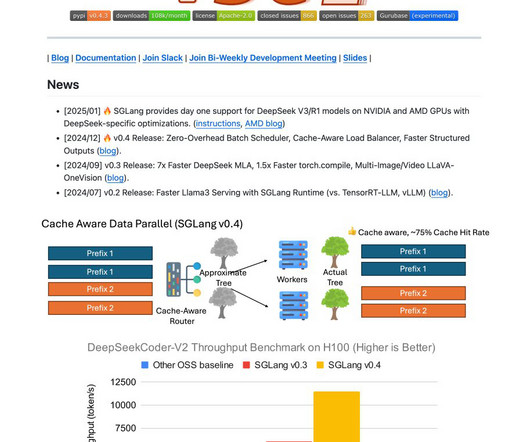
SGLang is an open-source inferenceengine designed by the SGLang team to address these challenges. It optimizes CPU and GPU resources during inference, achieving significantly higher throughput than many competitive solutions. SGLang is released under the Apache 2.0
Researchers at the Allen Institute for AI introduced olmOCR , an open-source Python toolkit designed to efficiently convert PDFs into structured plain text while preserving logical reading order. Compatible with inferenceengines like vLLM and SGLang, allowing flexible deployment on various hardware setups.
Moreover, the OpenAI-compatible Assistants API and Python SDK offer flexibility in easily integrating these agents into broader AI solutions. Developers can use built-in tools or create custom ones in JavaScript or Python, allowing for a highly customizable experience. If you like our work, you will love our newsletter.
Distillation is employed to transfer the knowledge of a large, complex model to a smaller, more efficient version that still performs well on inference tasks. Together, these components ensure that LightLLM achieves high performance in terms of inference speed and resource utilization.
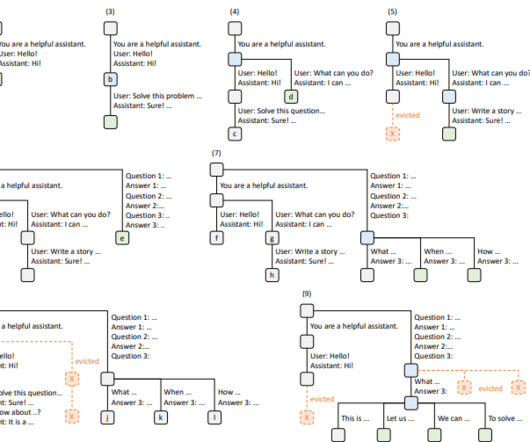
State-of-the-art inferenceengines, optimized to reduce latency and improve throughput, lack direct knowledge of the workload, resulting in significant inefficiencies. A notable example is the reuse of the Key-Value (KV) cache, which consists of reusable intermediate tensors essential for generative inference. fork, join).
From Sale Marketing Business 7 Powerful Python ML For Data Science And Machine Learning need to be use. This post will outline seven powerful python ml libraries that can help you in data science and different python ml environment. A python ml library is a collection of functions and data that can use to solve problems.
The dataset included 3.5TB of source code from various programming languages, ensuring the model could handle multiple languages, including Python, Java, C++, and JavaScript. The model was trained using a rigorous data collection pipeline that involved data crawling, cleaning, deduplication, and quality checks.
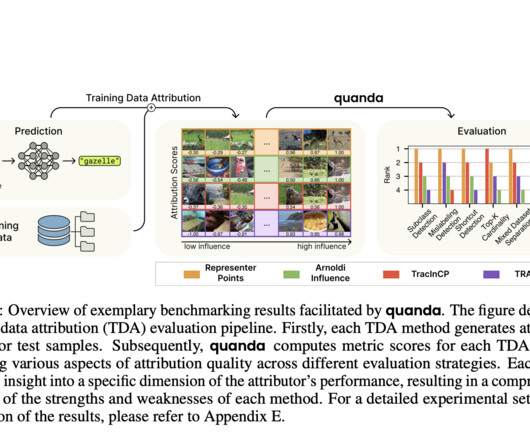
It is a Python toolkit that provides a comprehensive set of evaluation metrics and a uniform interface for seamless integration with current TDA implementations. This calls for a unified framework for TDA evaluation (and beyond). The Fraunhofer Institute for Telecommunications has put forth Quanda to bridge this gap.
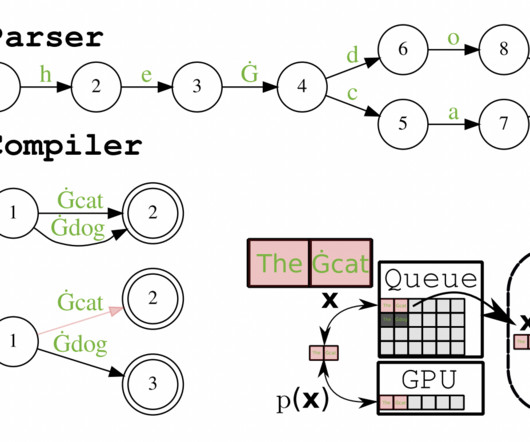
Because SGLang works with Python’s libraries and control flow, users may easily build sophisticated prompting processes using the language’s natural syntax. Both components can operate separately or in tandem for optimal performance. The team also presented a compiler and an interpreter for SGLang.
Deploying Flux as an API with LitServe For those looking to deploy Flux as a scalable API service, Black Forest Labs provides an example using LitServe, a high-performance inferenceengine. 1-schnell", subfolder="tokenizer_2", torch_dtype=torch.bfloat16) vae = AutoencoderKL.from_pretrained("black-forest-labs/FLUX.1-schnell",
Setup Python Virtual Environment Ubuntu 22.04 comes with Python 3.10. lib64 BNB_CUDA_VERSION=122 CUDA_VERSION=122 python setup.py The model is first parsed and optimized by TensorRT, which generates a highly optimized inferenceengine tailored for the specific model and hardware.
Python user programs can use the ReLM framework; ReLM exposes a specific API that these programs can use. A regular expression inferenceengine that effectively converts regular expressions to finite automata has been designed and implemented. They are the first group to use automata to accommodate these variant encodings.
GitHub: Tencent/TurboTransformers Make transformers serving fast by adding a turbo to your inferenceengine!Transformer Instead of building a model from… github.com NERtwork Awesome new shell/python script that graphs a network of co-occurring entities from plain text! These 2 repos encompass NLP and Speech modeling.
In order to tackle this, the team at Modular developed a modular inferenceengine. When state-of-the-art models are moved from the research phase to the production phase, developers are usually compelled to rewrite large portions of their models in more performing languages than Python, in order to meet the latency and cost targets.
With advancements in hardware design, a wide range of CPU- and GPU-based infrastructures are available to help you speed up inference performance. Analyze the default and advanced Inference Recommender job results, which include ML instance type recommendation latency, performance, and cost metrics. sm_client = boto3.client("sagemaker",
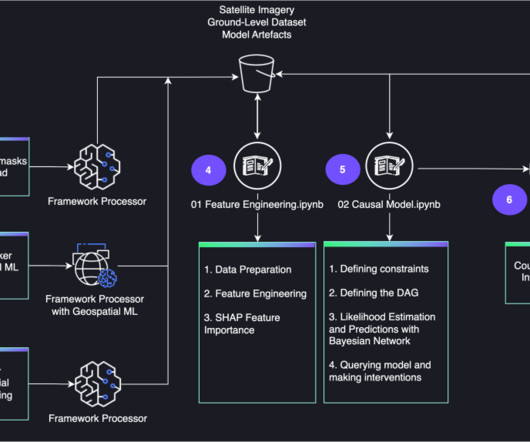
The causal inferenceengine is deployed with Amazon SageMaker Asynchronous Inference. Conclusion This solution provides a blueprint for use cases where causal inference with Bayesian networks are the preferred methodology for answering causal questions from a combination of data and human inputs.
The document chunking step is conducted offline using Python scripts. Tech Stack Tech Stack Below, we provide a quick overview of the project, divided into research and inference sites. Methods and Tools Let’s start with the inferenceengine for the Small Language Model.
launch() This Python script uses a HuggingFace Transformers library to load the tiiuae/falcon-7b-instruct model. LLM from a CPU-Optimized (GGML) format: LLaMA.cpp is a C++ library that provides a high-performance inferenceengine for large language models (LLMs). We leverage the python bindings for LLaMA.cpp to load the model.
Please join me at my ODSC workshop on Jan 15th for a deeper dive on turbo LoRA, as well as a few other innovative features of Predibases next-gen inferenceengine that collectively enhance the deployment ofSLMs. We made fine-tuning super easy but also flexible for advanced users to configure different settings.
Serving as a high-performance inferenceengine, ONNX Runtime can handle machine learning models in the ONNX format and has been proven to significantly boost inference performance across a multitude of models. Our Models Hub now contains over 18,000+ free and truly open-source models & pipelines. LTS Databricks 13.1
Installation Installation is quite simple* Clone the library* Run installation script Support available for▹ Python — 3.6▹ With Monk, it is easier to do the same using simple pythonic syntax. Get over the hassles of changing codes and configurations to insert custom dataset for training. Cuda — 9.0, Runs on colab too!!!
👷 The LLM Engineer focuses on creating LLM-based applications and deploying them. DataDreamer is a powerful open-source Python library for prompting, synthetic data generation, and training workflows. Differential Language Analysis ToolKit DLATK is an end to end human text analysis package for Python 3.
dkr.ecr.amazonaws.com/huggingface-pytorch-tgi-inference:2.4.0-tgi2.4.0-gpu-py311-cu124-ubuntu22.04-v2.0", On SageMaker, Triton offers a comprehensive serving stack with support for various backends, including TensorRT, PyTorch, Python, and more. gpu-py311-cu124-ubuntu22.04-v2.0",
You can reattach to your Docker container and stop the online inference server with the following: docker attach $(docker ps --format "{{.ID}}") Create a file for using the offline inferenceengine: cat > offline_inference.py <<EOF from vllm.entrypoints.llm import LLM from vllm.sampling_params import SamplingParams # Sample prompts.
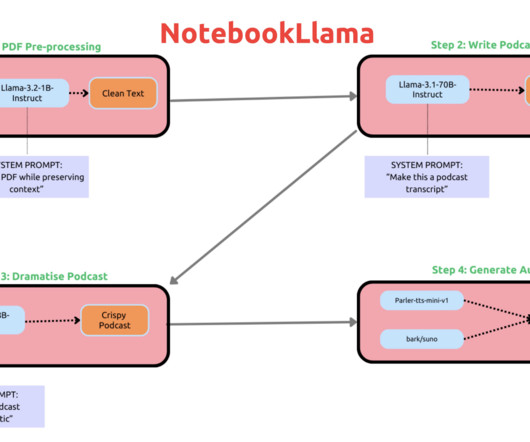
A community-driven benchmark on Reddit highlights NotebookLlama’s effectiveness in generating insightful commentary for complex Python scripts, achieving over 90% accuracy in generating meaningful docstrings. Conclusion Meta’s NotebookLlama is a significant step forward in the world of open-source AI tools.
DeepSparse: a CPU inferenceengine for sparse models. Sparsify: a UI interface to optimize deep neural networks for better inference performance. Their infrastructure is built on top of FastAPI and supports Python, Go and Ruby languages. Follow their code on GitHub. SparseZoo: a model repo for sparse models. torch==1.2.0…
DeepSparse: a CPU inferenceengine for sparse models. Sparsify: a UI interface to optimize deep neural networks for better inference performance. Their infrastructure is built on top of FastAPI and supports Python, Go and Ruby languages. Follow their code on GitHub. SparseZoo: a model repo for sparse models. torch==1.2.0…
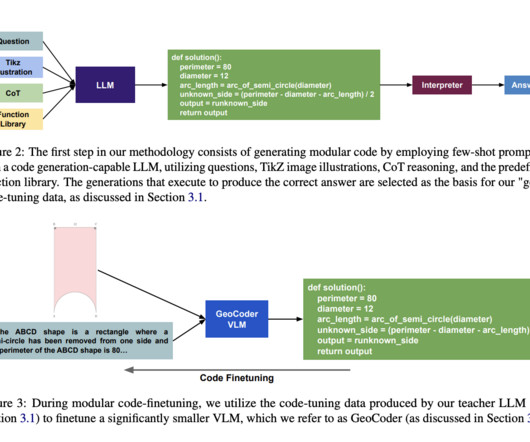
The proposed method introduces GeoCoder, a VLM fine-tuned to solve geometry problems by generating modular Python code that references a predefined geometry function library. GeoCoder and RAG-GeoCoder achieve over a 16% performance boost on geometry tasks, demonstrating enhanced reasoning and interpretability on complex multimodal datasets.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content