This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
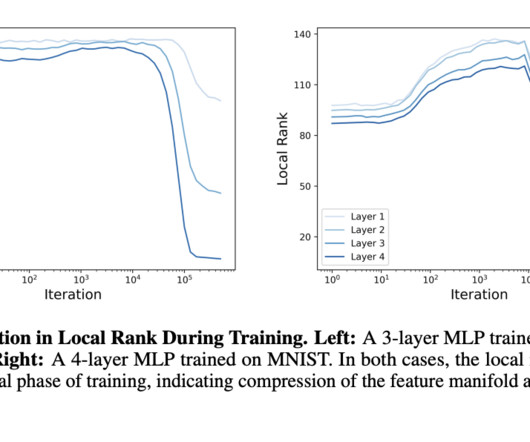
Deep neuralnetworks are powerful tools that excel in learning complex patterns, but understanding how they efficiently compress input data into meaningful representations remains a challenging research problem. The paper presents both theoretical analysis and empirical evidence demonstrating this phenomenon.
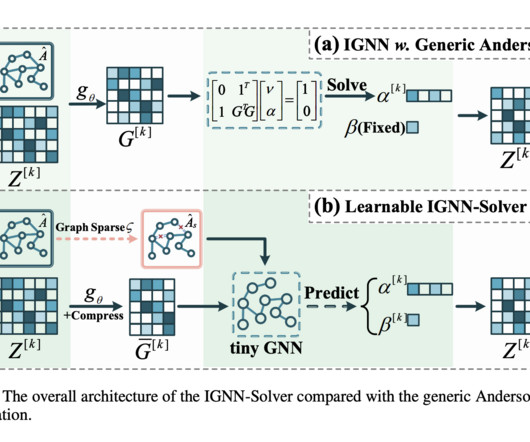
A team of researchers from Huazhong University of Science and Technology, hanghai Jiao Tong University, and Renmin University of China introduce IGNN-Solver, a novel framework that accelerates the fixed-point solving process in IGNNs by employing a generalized Anderson Acceleration method, parameterized by a small Graph NeuralNetwork (GNN).
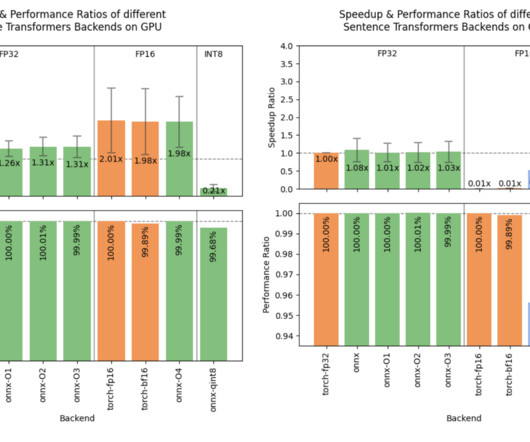
This feature is especially useful for repeated neuralnetwork modules like those commonly used in transformers. Users working with these newer GPUs will find that their workflows can achieve greater throughput with reduced latency, thereby enhancing training and inference times for large-scale models.
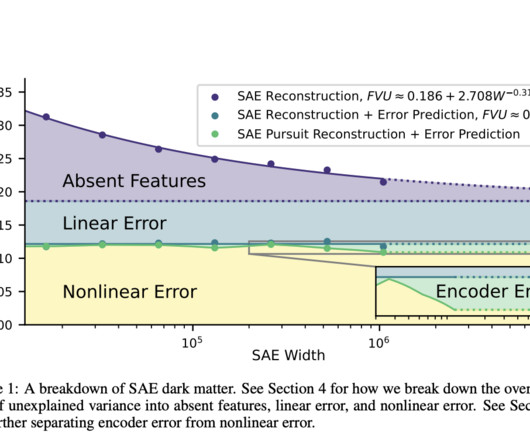
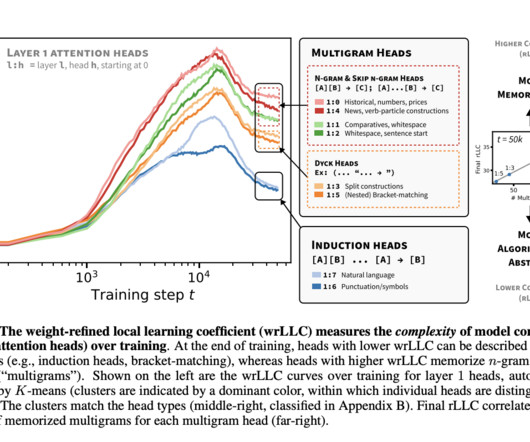
The ultimate aim of mechanistic interpretability is to decode neuralnetworks by mapping their internal features and circuits. Two methods to reduce nonlinear error were explored: inference time optimization and SAE outputs from earlier layers, with the latter showing greater error reduction.
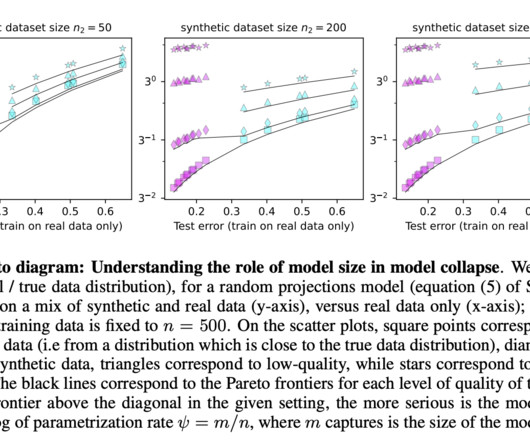
One of the core areas of development within machine learning is neuralnetworks, which are especially critical for tasks such as image recognition, language processing, and autonomous decision-making. Model collapse presents a critical challenge affecting neuralnetworks’ scalability and reliability.
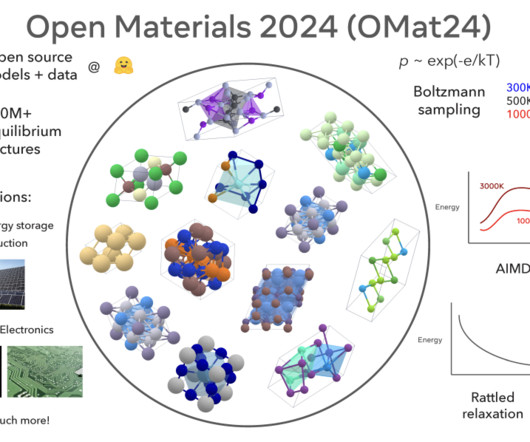
They also present the EquiformerV2 model, a state-of-the-art Graph NeuralNetwork (GNN) trained on the OMat24 dataset, achieving leading results on the Matbench Discovery leaderboard. The dataset includes diverse atomic configurations sampled from both equilibrium and non-equilibrium structures.
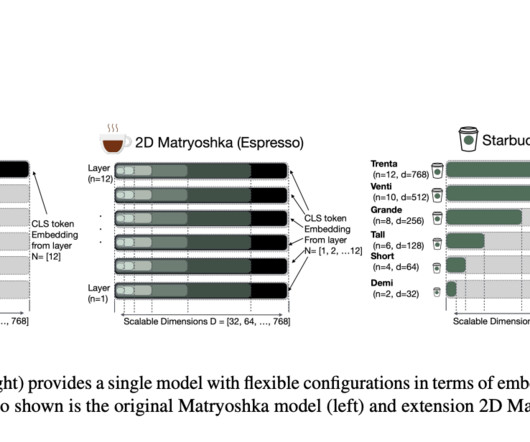
Shallow neuralnetworks are used to map these relationships, so they fail to capture their depth. Traditional embedding methods, such as 2D Matryoshka Sentence Embeddings (2DMSE), have been used to represent data in vector space, but they struggle to encode the depth of complex structures. Don’t Forget to join our 55k+ ML SubReddit.
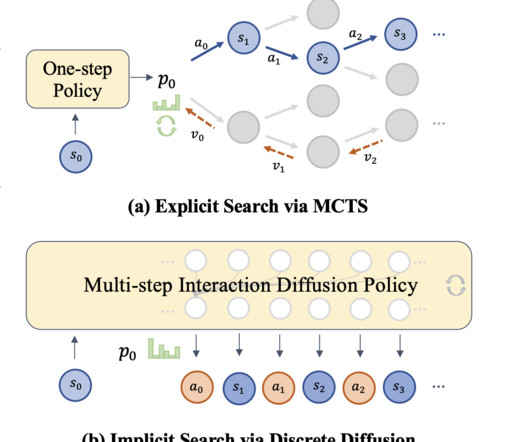
Existing methods to address the challenges in AI-powered chess and decision-making systems include neuralnetworks for chess, diffusion models, and world models. In chess AI, the field has evolved from handcrafted search algorithms and heuristics to neuralnetwork-based approaches.
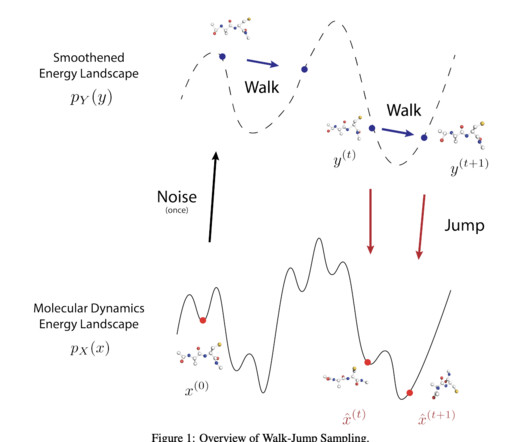
The proposed methodology is rooted in the concept of Walk-Jump Sampling, where noise is added to clean data, followed by training a neuralnetwork to denoise it, thereby allowing a smooth sampling process. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
Static Embeddings are bags of token embeddings that are summed together to create text embeddings, allowing for lightning-fast embeddings without requiring neuralnetworks. [link] Introduction of Static Embeddings Another major feature is Static Embeddings, a modernized version of traditional word embeddings like GLoVe and word2vec.
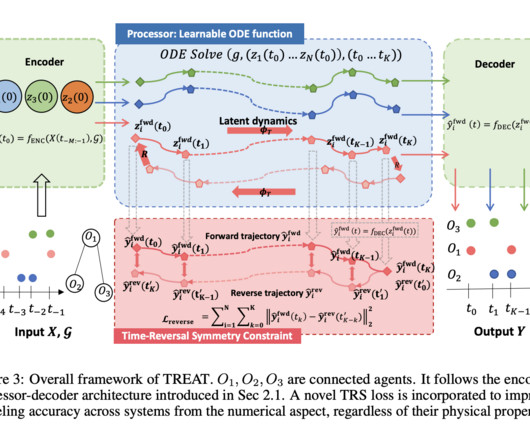
Inaccurate predictions in these cases can have real-world consequences, such as in engineering designs or scientific simulations where precision is critical. HNNs are particularly effective for systems where energy conservation holds but struggle with systems that violate this principle. If you like our work, you will love our newsletter.
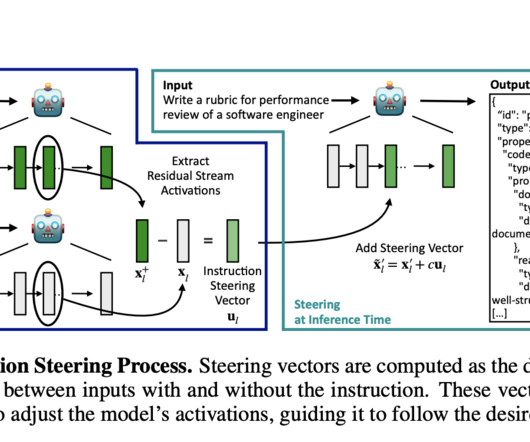
When a model receives an input, it processes it through multiple layers of neuralnetworks, where each layer adjusts the model’s understanding of the task. Activation steering operates by identifying and manipulating the internal layers of the model responsible for instruction-following.
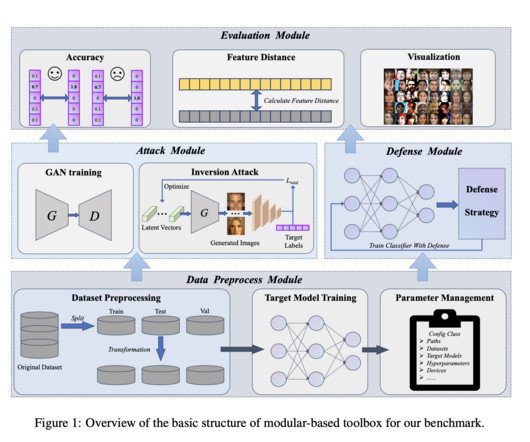
raising widespread concerns about privacy threats of Deep NeuralNetworks (DNNs). Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post MIBench: A Comprehensive AI Benchmark for Model Inversion Attack and Defense appeared first on MarkTechPost.
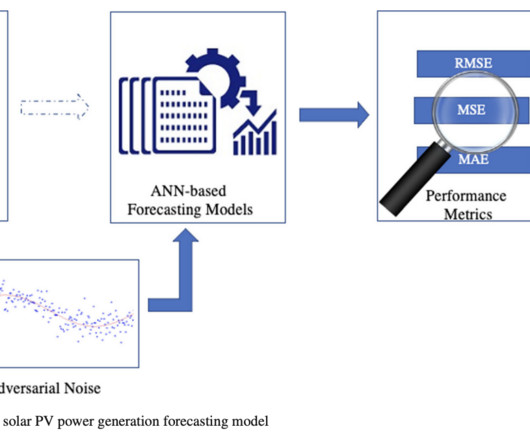
More sophisticated machine learning approaches, such as artificial neuralnetworks (ANNs), may detect complex relationships in data. Furthermore, deep learning techniques like convolutional networks (CNNs) and long short-term memory (LSTM) models are commonly employed due to their ability to analyze temporal and meteorological data.
A significant aspect of AI research focuses on neuralnetworks, particularly transformers. Several tools have been developed to study how neuralnetworks operate. During training, neuralnetworks adjust their weights based on how well they minimize prediction errors (loss).
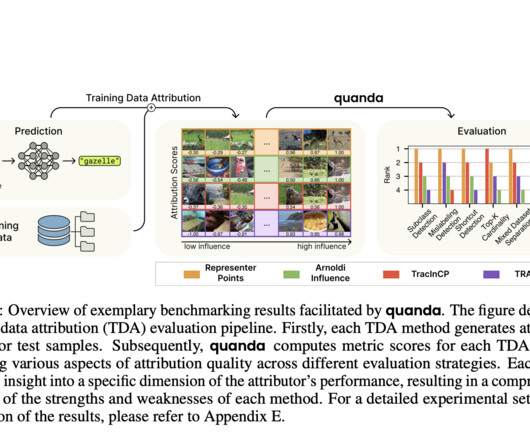
XAI, or Explainable AI, brings about a paradigm shift in neuralnetworks that emphasizes the need to explain the decision-making processes of neuralnetworks, which are well-known black boxes. Today, we talk about TDA, which aims to relate a model’s inference from a specific sample to its training data.
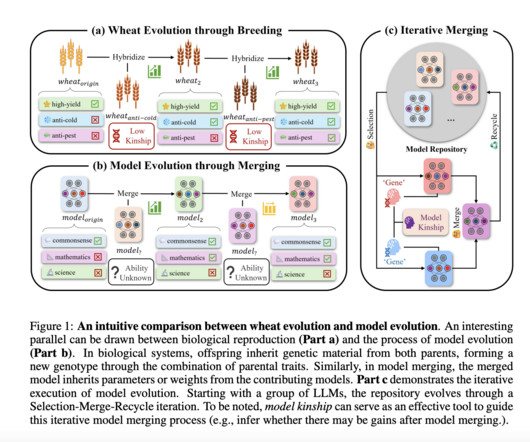
Weight averaging, originating from Utans’ work in 1996, has been widely applied in deep neuralnetworks for combining checkpoints, utilizing task-specific information, and parallel training of LLMs. Researchers have explored various approaches to address the challenges of model merging and multitask learning in LLMs.
Deep neuralnetworks, typically fine-tuned foundational models, are widely used in sectors like healthcare, finance, and criminal justice, where biased predictions can have serious societal impacts. Datasets and pre-trained models come with intrinsic biases. If you like our work, you will love our newsletter.
The OCM methodology offers a streamlined approach to estimating covariance by training a neuralnetwork to predict the diagonal Hessian, which allows for accurate covariance approximation with minimal computational demands. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










Let's personalize your content