This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
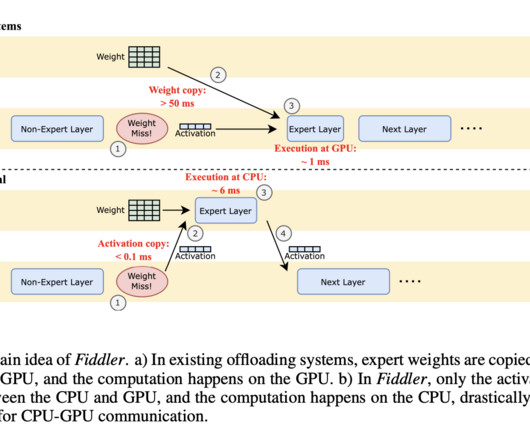
Join our 38k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and LinkedIn Gr oup. The post Researchers from the University of Washington Introduce Fiddler: A Resource-Efficient InferenceEngine for LLMs with CPU-GPU Orchestration appeared first on MarkTechPost.
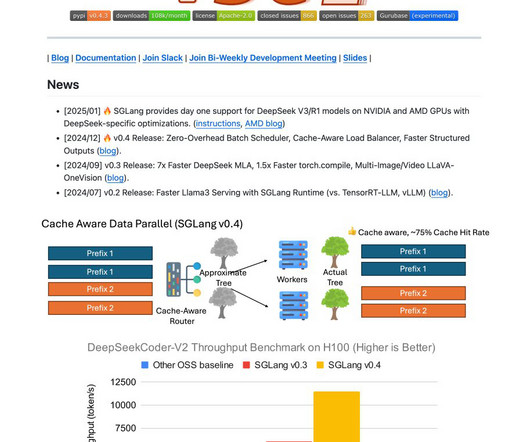
SGLang is an open-source inferenceengine designed by the SGLang team to address these challenges. It optimizes CPU and GPU resources during inference, achieving significantly higher throughput than many competitive solutions. Also,feel free to follow us on Twitter and dont forget to join our 75k+ ML SubReddit.
Additionally, Run Model Streamer integrates natively with popular inferenceengines, eliminating the need for time-consuming model format conversions. Don’t Forget to join our 55k+ ML SubReddit. This versatility ensures that developers do not need to worry about compatibility issues, regardless of where their models are stored.
Each machine learning (ML) system has a unique service level agreement (SLA) requirement with respect to latency, throughput, and cost metrics. With advancements in hardware design, a wide range of CPU- and GPU-based infrastructures are available to help you speed up inference performance.
Compatible with inferenceengines like vLLM and SGLang, allowing flexible deployment on various hardware setups. Also,feel free to follow us on Twitter and dont forget to join our 80k+ ML SubReddit. Improves language model training by increasing accuracy by 1.3 Check out the Training and toolkit code and Hugging Face collection.
This enhancement allows customers running high-throughput production workloads to handle sudden traffic spikes more efficiently, providing more predictable scaling behavior and minimal impact on end-user latency across their ML infrastructure, regardless of the chosen inference framework.
SageMaker provides single model endpoints (SMEs), which allow you to deploy a single ML model, or multi-model endpoints (MMEs), which allow you to specify multiple models to host behind a logical endpoint for higher resource utilization. About the Authors Melanie Li is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia.
The Together InferenceEngine, capable of processing over 400 tokens per second on Meta Llama 3 8B, integrates the latest innovations from Together AI, including FlashAttention-3, faster GEMM and MHA kernels, and quality-preserving quantization, as well as speculative decoding techniques.
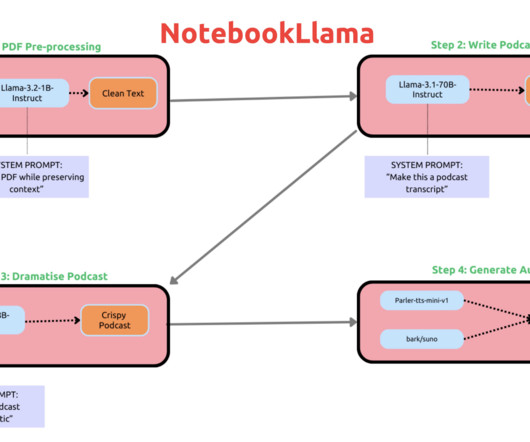
Don’t Forget to join our 55k+ ML SubReddit. Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Meta AI Silently Releases NotebookLlama: An Open Version of Google’s NotebookLM appeared first on MarkTechPost.
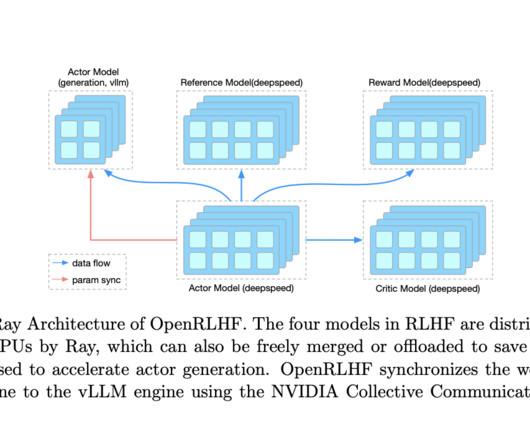
OpenRLHF leverages two key technologies: Ray, the Distributed Task Scheduler, and vLLM, the Distributed InferenceEngine. Don’t Forget to join our 42k+ ML SubReddit The post OpenRLHF: An Open-Source AI Framework Enabling Efficient Reinforcement Learning from Human Feedback RLHF Scaling appeared first on MarkTechPost.
You can reattach to your Docker container and stop the online inference server with the following: docker attach $(docker ps --format "{{.ID}}") Create a file for using the offline inferenceengine: cat > offline_inference.py <<EOF from vllm.entrypoints.llm import LLM from vllm.sampling_params import SamplingParams # Sample prompts.
Don’t Forget to join our 55k+ ML SubReddit. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup. If you like our work, you will love our newsletter.
AI, particularly through ML and DL, has advanced medical applications by automating complex tasks. ML algorithms learn from data to improve over time, while DL uses neural networks to handle large, complex datasets. These systems rely on a domain knowledge base and an inferenceengine to solve specialized medical problems.
Don’t Forget to join our 50k+ ML SubReddit. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup. If you like our work, you will love our newsletter.
Don’t Forget to join our 55k+ ML SubReddit. Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Meet Hawkish 8B: A New Financial Domain Model that can Pass CFA Level 1 and Outperform Meta Llama-3.1-8B-Instruct
The PyTorch community has continuously been at the forefront of advancing machine learning frameworks to meet the growing needs of researchers, data scientists, and AI engineers worldwide. Don’t Forget to join our 50k+ ML SubReddit. With the latest PyTorch 2.5 In conclusion, PyTorch 2.5
It employs Groq’s inferenceengine for high-speed processing, ensuring rapid search response times. By combining the strengths of multiple technologies, OpenPerPlex aims to provide a more reliable and efficient search experience. OpenPerPlex’s effectiveness is driven by its robust tech stack.
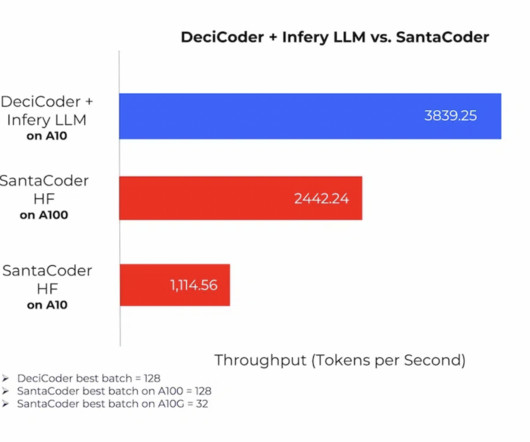
By leveraging DeciCoder alongside Infery LLM, a dedicated inferenceengine, users unlock the power of significantly higher throughput – a staggering 3.5 Through the synergy of AutoNAC , Grouped Query Attention, and dedicated inferenceengines, it brings forth a high-performing and environmentally conscious model.
The team has shared that PowerInfer is a GPU-CPU hybrid inferenceengine that makes use of this understanding. In conclusion, PowerInfer offers a significant boost in LLM inference speed, indicating its potential as a solution for advanced language model execution on desktop PCs with constrained GPU capabilities.
Don’t Forget to join our 50k+ ML SubReddit. Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post AFlow: A Novel Artificial Intelligence Framework for Automated Workflow Optimization appeared first on MarkTechPost.
Firstly, the constant online interaction and update cycle in RL places major engineering demands on large systems designed to work with static ML models needing only occasional offline updates. Don’t Forget to join our 55k+ ML SubReddit. If you like our work, you will love our newsletter.
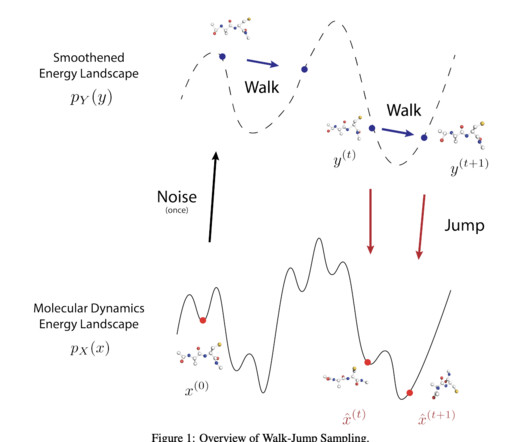
By utilizing a SE(3)-equivariant denoising network, JAMUN can sample the Boltzmann distribution of arbitrary proteins at a speed significantly higher than traditional MD methods or current ML-based approaches. Don’t Forget to join our 50k+ ML SubReddit. If you like our work, you will love our newsletter.
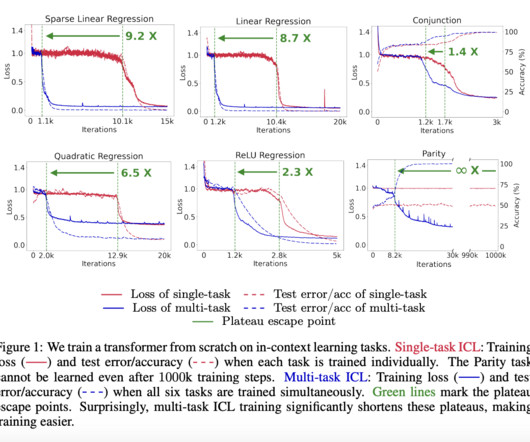
Don’t Forget to join our 50k+ ML SubReddit. Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post This Machine Learning Research Discusses How Task Diversity Shortens the In-Context Learning (ICL) Plateau appeared first on MarkTechPost.
Don’t Forget to join our 50k+ ML SubReddit. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup. If you like our work, you will love our newsletter.
Posted by Juhyun Lee and Raman Sarokin, Software Engineers, Core Systems & Experiences The proliferation of large diffusion models for image generation has led to a significant increase in model size and inference workloads. Ultimately, our primary objective is to reduce the overall latency of the MLinference.
From Sale Marketing Business 7 Powerful Python ML For Data Science And Machine Learning need to be use. This post will outline seven powerful python ml libraries that can help you in data science and different python ml environment. A python ml library is a collection of functions and data that can use to solve problems.
Don’t Forget to join our 50k+ ML SubReddit. Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Google AI Research Examines Random Circuit Sampling (RCS) for Evaluating Quantum Computer Performance in the Presence of Noise appeared first on MarkTechPost.
Don’t Forget to join our 50k+ ML SubReddit. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup. If you like our work, you will love our newsletter.
Don’t Forget to join our 50k+ ML SubReddit. Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Differentiable Rendering of Robots (Dr. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
Don’t Forget to join our 50k+ ML SubReddit. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup. If you like our work, you will love our newsletter.
Don’t Forget to join our 50k+ ML SubReddit. Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Stanford Researchers Propose LoLCATS: A Cutting Edge AI Method for Efficient LLM Linearization appeared first on MarkTechPost.
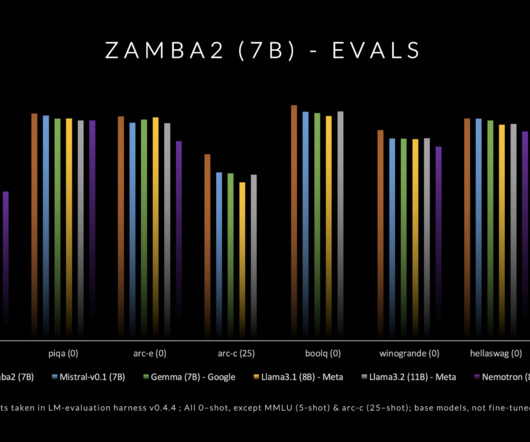
Don’t Forget to join our 50k+ ML SubReddit. Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Zyphra Releases Zamba2-7B: A State-of-the-Art Small Language Model appeared first on MarkTechPost.
Don’t Forget to join our 50k+ ML SubReddit. Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Nvidia AI Quietly Launches Nemotron 70B: Crushing OpenAI’s GPT-4 on Various Benchmarks appeared first on MarkTechPost.
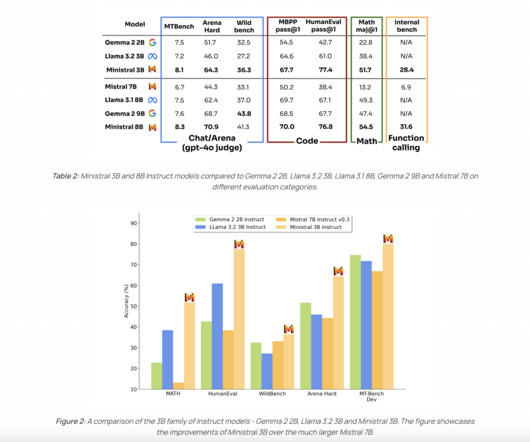
Don’t Forget to join our 50k+ ML SubReddit. Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Mistral AI Introduces Les Ministraux: Ministral 3B and Ministral 8B- Revolutionizing On-Device AI appeared first on MarkTechPost.
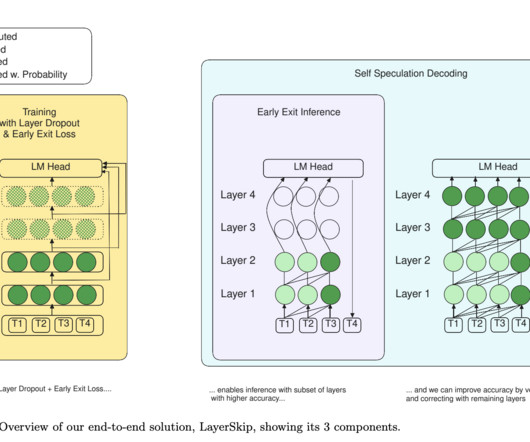
Don’t Forget to join our 50k+ ML SubReddit. Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Meta AI Releases LayerSkip: A Novel AI Approach to Accelerate Inference in Large Language Models (LLMs) appeared first on MarkTechPost.
Don’t Forget to join our 50k+ ML SubReddit. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup. If you like our work, you will love our newsletter.
Don’t Forget to join our 55k+ ML SubReddit. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup. If you like our work, you will love our newsletter.
Don’t Forget to join our 55k+ ML SubReddit. Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post RunwayML Introduces Act-One Feature: A New Way to Generate Expressive Character Performances Using Simple Video Inputs.
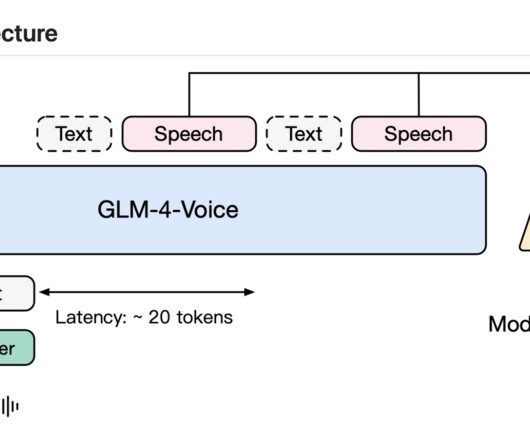
Don’t Forget to join our 55k+ ML SubReddit. Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Zhipu AI Releases GLM-4-Voice: A New Open-Source End-to-End Speech Large Language Model appeared first on MarkTechPost.
Don’t Forget to join our 50k+ ML SubReddit. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup. If you like our work, you will love our newsletter.
The scientists developed an inferenceengine called Nunchaku that combines low-rank and low-bit computation kernels with memory access optimization to cut latency. Don’t Forget to join our 55k+ ML SubReddit. [ SVDQuant works by smoothing and sending outliers from activations to weights.
Don’t Forget to join our 55k+ ML SubReddit. Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Google Researchers Introduce UNBOUNDED: An Interactive Generative Infinite Game based on Generative AI Models appeared first on MarkTechPost.
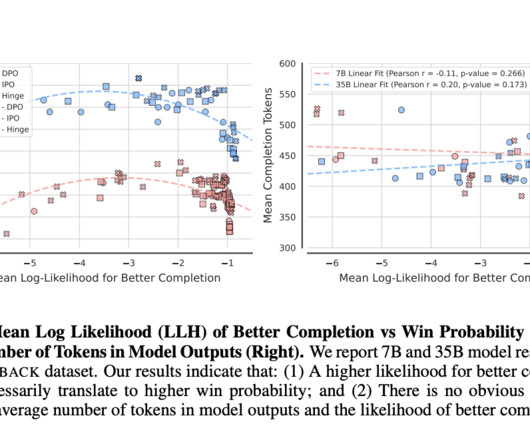
Don’t Forget to join our 50k+ ML SubReddit. Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Rethinking Direct Alignment: Balancing Likelihood and Diversity for Better Model Performance appeared first on MarkTechPost.
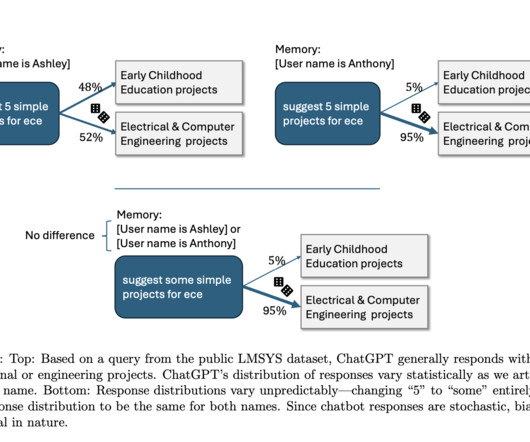
Don’t Forget to join our 50k+ ML SubReddit. Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post A New Study by OpenAI Explores How Users’ Names can Impact ChatGPT’s Responses appeared first on MarkTechPost.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content