This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Groq groq Groq is renowned for its high-performance AI inference technology. Their standout product, the Language Processing Units (LPU) InferenceEngine , combines specialized hardware and optimized software to deliver exceptional compute speed, quality, and energy efficiency. per million tokens.
For AI and large language model (LLM) engineers , design patterns help build robust, scalable, and maintainable systems that handle complex workflows efficiently. This article dives into design patterns in Python, focusing on their relevance in AI and LLM -based systems. When to Use Managing global configurations (e.g.,
Predibase announces the Predibase InferenceEngine , their new infrastructure offering designed to be the best platform for serving fine-tuned small language models (SLMs). The Predibase InferenceEngine addresses these challenges head-on, offering a tailor-made solution for enterprise AI deployments.
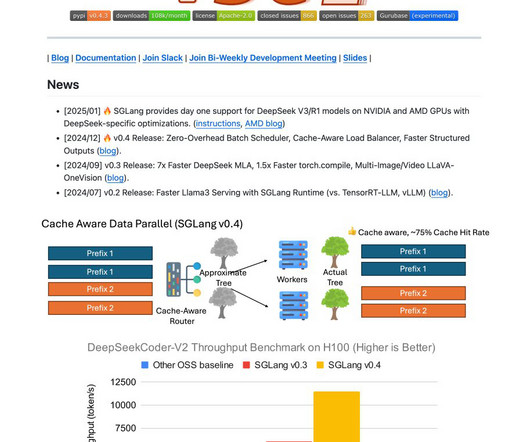
SGLang is an open-source inferenceengine designed by the SGLang team to address these challenges. It optimizes CPU and GPU resources during inference, achieving significantly higher throughput than many competitive solutions. RadixAttention is central to SGLang, which reuses shared prompt prefixes across multiple requests.
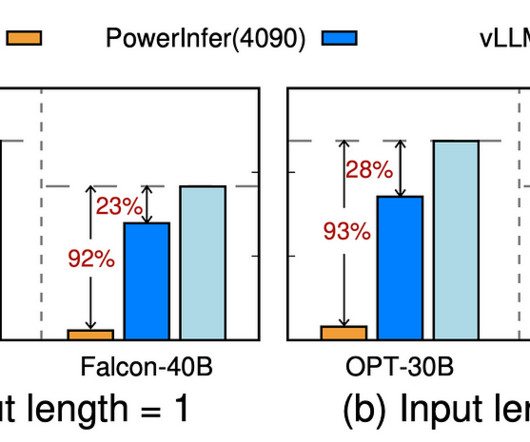
In a recent study, a team of researchers presented PowerInfer, an effective LLMinference system designed for local deployments using a single consumer-grade GPU. The team has shared that PowerInfer is a GPU-CPU hybrid inferenceengine that makes use of this understanding. Check out the Paper and Github.
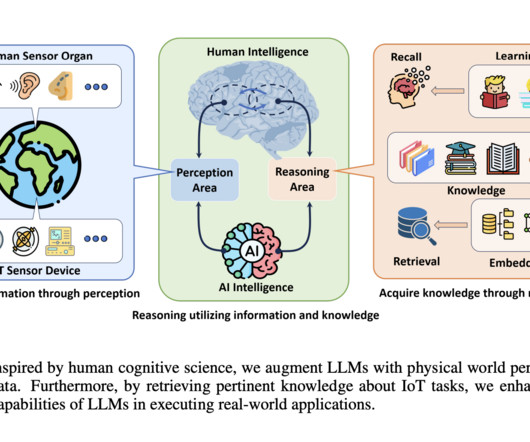
MARS Lab, NTU has devised an innovative IoT-LLM framework that combats the limitations of the LLM in handling real-world tasks. For example, in traditional LLMs like Chat-GPT 4, only 40% accuracy in activity recognition and 50% in machine diagnosis are achieved after processing the raw IoT data.
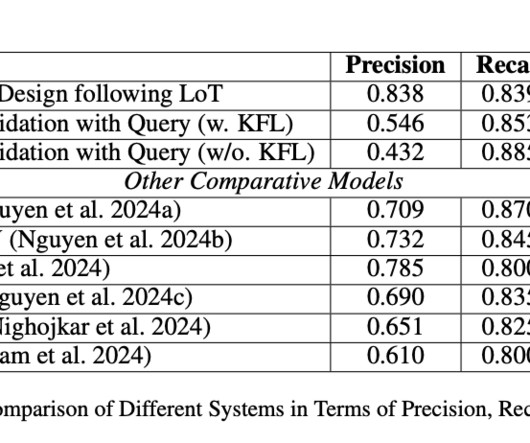
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Layer-of-Thoughts Prompting (LoT): A Unique Approach that Uses Large Language Model (LLM) based Retrieval with Constraint Hierarchies appeared first on MarkTechPost.
Researchers from Google Cloud AI, Google DeepMind, and the University of Washington have proposed a new approach called MODEL SWARMS , which utilizes swarm intelligence to adapt LLMs through collaborative search in the weight space.
Research on the robustness of LLMs to jailbreak attacks has mostly focused on chatbot applications, where users manipulate prompts to bypass safety measures. However, LLM agents, which utilize external tools and perform multi-step tasks, pose a greater misuse risk, especially in malicious contexts like ordering illegal materials.
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Stanford Researchers Propose LoLCATS: A Cutting Edge AI Method for Efficient LLM Linearization appeared first on MarkTechPost. Don’t Forget to join our 50k+ ML SubReddit.
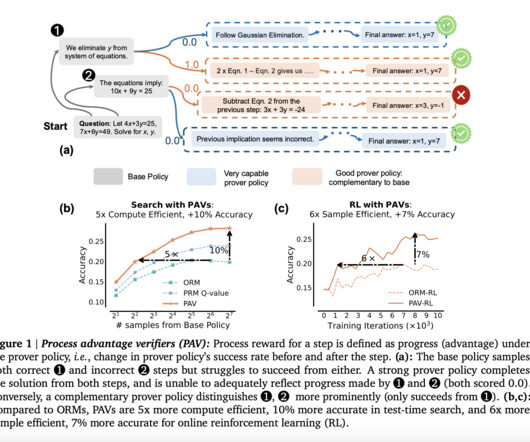
The key innovation in PAVs is using a “prover policy,” distinct from the base policy that the LLM is following. This enables the LLM to explore a wider range of potential solutions, even when early steps do not immediately lead to a correct solution. Check out the Paper. Don’t Forget to join our 50k+ ML SubReddit.
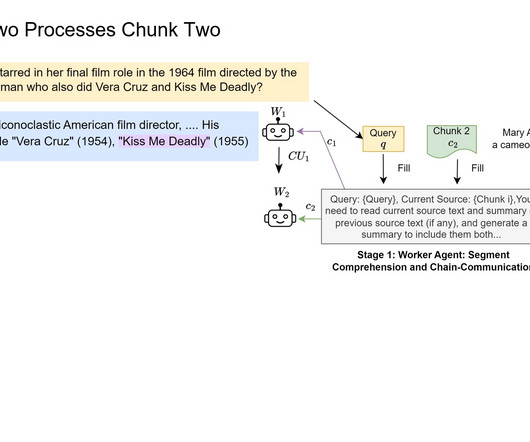
Specifically, while LLMs are becoming capable of handling longer input sequences, the increase in retrieved information can overwhelm the system. The challenge lies in making sure that the additional context improves the accuracy of the LLM’s outputs rather than confusing the model with irrelevant information.
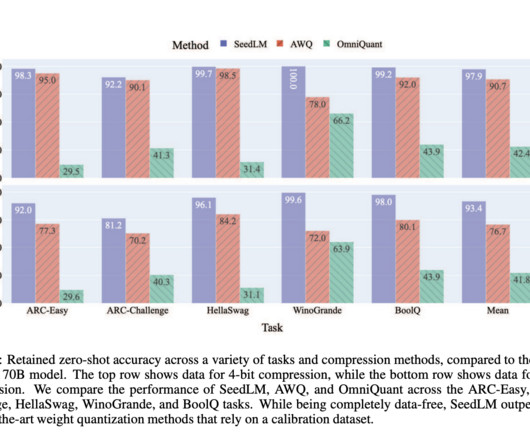
The key problem, therefore, is how to effectively compress LLM weights without sacrificing accuracy or requiring calibration data. Researchers from Apple and Meta AI introduce SeedLM, a novel approach that aims to overcome the challenges associated with the deployment of large-scale LLMs by providing a data-free compression method.
In this article, we will discuss PowerInfer, a high-speed LLMinferenceengine designed for standard computers powered by a single consumer-grade GPU. The PowerInfer framework seeks to utilize the high locality inherent in LLMinference, characterized by a power-law distribution in neuron activations.
Cost-effective: CoA reduces time complexity from n2 n 2 to nk nk , where n n is the number of input tokens and k k is the context limit of the LLM. These results demonstrate that CoA can enhance LLM performance even for models with very long context window limits and provides greater performance gains for longer inputs.
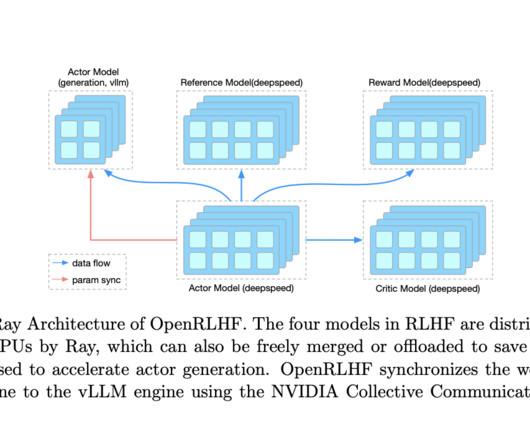
Current RLHF approaches often involve dividing the LLM across multiple GPUs for training, but this strategy is not without its drawbacks. OpenRLHF leverages two key technologies: Ray, the Distributed Task Scheduler, and vLLM, the Distributed InferenceEngine.
NVIDIA Inference Microservices (NIM) and LangChain are two cutting-edge technologies that meet these needs, offering a comprehensive solution for deploying AI in real-world environments. Understanding NVIDIA NIM NVIDIA NIM, or NVIDIA Inference Microservices, is simplifying the process of deploying AI models.
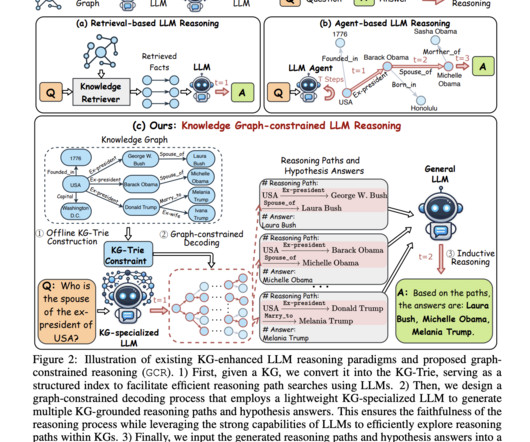
Large language models (LLMs) have demonstrated significant reasoning capabilities, yet they face issues like hallucinations and the inability to conduct faithful reasoning. GCR introduces a trie-based index named KG-Trie to integrate KG structures directly into the LLM decoding process. Don’t Forget to join our 50k+ ML SubReddit.
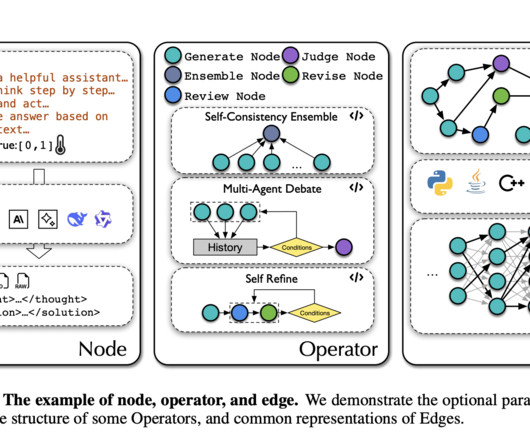
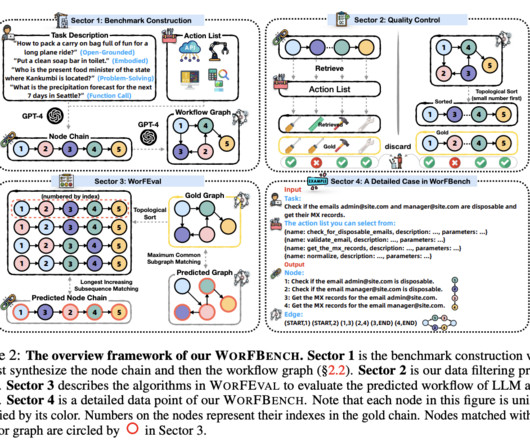
These workflows are modeled as graphs where nodes represent LLM-invoking actions, and edges represent the dependencies between these actions. The key to AFlow’s efficiency lies in its use of nodes and edges to represent workflows, allowing it to model complex relationships between LLM actions.
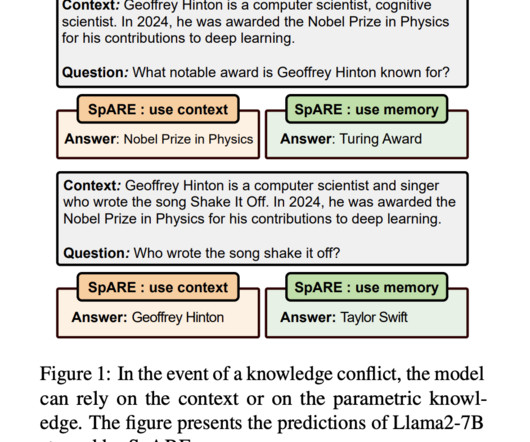
LLMs prefer contextual knowledge over their parametric knowledge, but during conflicts, existing solutions that need additional model interactions result in high latency times, making them impractical for real-world applications. Representation engineering emerged as a higher-level framework for understanding LLM behavior at scale.
Teams from the companies worked closely together to accelerate the performance of Gemma — built from the same research and technology used to create Google DeepMind’s most capable model yet, Gemini — with NVIDIA TensorRT-LLM , an open-source library for optimizing large language model inference, when running on NVIDIA GPUs.
Large Language Models (LLMs) have shown remarkable potential in solving complex real-world problems, from function calls to embodied planning and code generation. Researchers from Zhejiang University and Alibaba Group have proposed WORFBENCH, a benchmark for evaluating workflow generation capabilities in LLM agents.
Researchers developed an efficient, scalable, and lightweight framework for LLMinference, LightLLM, to address the challenge of efficiently deploying LLMs in environments with limited computational resources, such as mobile devices, edge computing, and resource-constrained environments.
Another clever way of distributing the workload between CPU and GPU in a way to speed up most of the local inference workloads. The key underlying the design of PowerInfer is exploiting the high locality inherent in LLMinference, characterized by a power-law distribution in neuron activation.
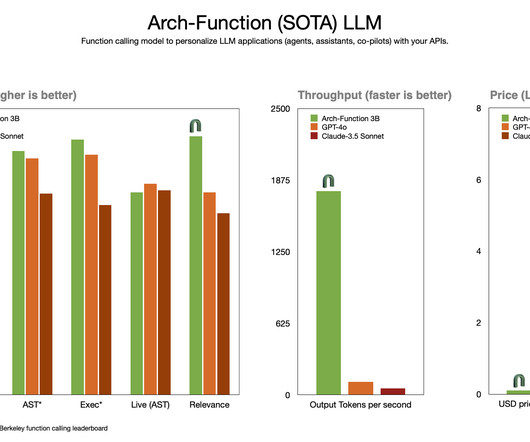
Katanemo’s Arch-Function transforms workflow automation by simplifying LLM deployment and reducing engineering overhead, making it accessible even for smaller enterprises. Arch-Function is optimized for speed and precision, completing tasks in minutes that previously took hours while effectively adapting to dynamic requirements.
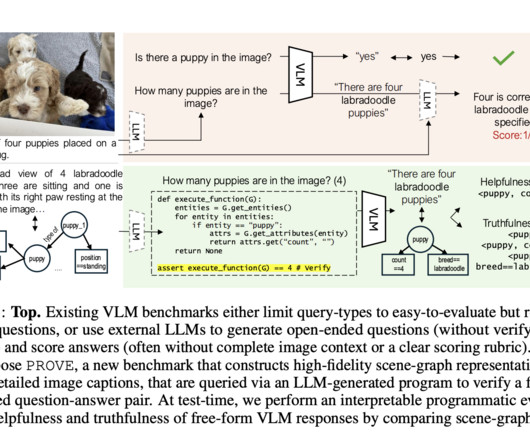
In PROVE, researchers use a high-fidelity scene graph representation constructed from hyper-detailed image captions and employ a large language model (LLM) to generate diverse question-answer (QA) pairs along with executable programs to verify each QA pair. This approach allows the creation of a benchmark dataset of 10.5k
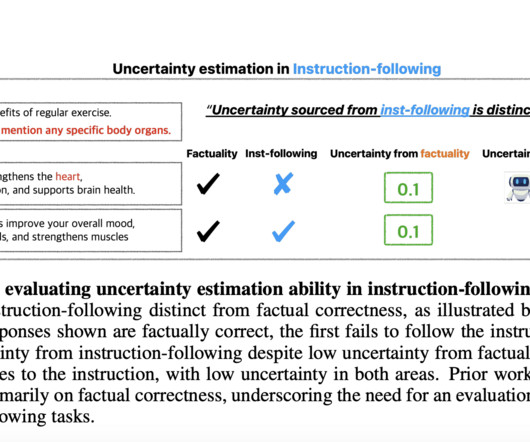
In light of these drawbacks, a trustworthy technique for determining when and how an LLM may be unsure about its capacity to follow directions is necessary to reduce the dangers involved with using these models. If you like our work, you will love our newsletter. Don’t Forget to join our 55k+ ML SubReddit.
For the ever-growing challenge of LLM validation, ReLM provides a competitive and generalized starting point. ReLM is the first solution that allows practitioners to directly measure LLM behavior over collections too vast to enumerate by describing a query as the whole set of test patterns.
Large language models (LLMs) like GPT-4, Gemini, and Llama 3 have revolutionized natural language processing through extensive pre-training and supervised fine-tuning (SFT). However, these models come with high computational costs for training and inference. Check out the Paper. If you like our work, you will love our newsletter.
higher throughput compared to state-of-the-art inference systems on various large language and multimodal models, tackling tasks such as agent control, logical reasoning, few-shot learning benchmarks, JSON decoding, retrieval-augmented generation pipelines, and multi-turn chat. Experiments demonstrate that SGLang achieves up to 6.4×
Task superposition means that when an LLM is provided relevant examples for each task within the same input prompt, it can process and produce responses for several tasks at once. The team has shared their primary contributions as follows. Llama-3, and Qwen. If you like our work, you will love our newsletter.
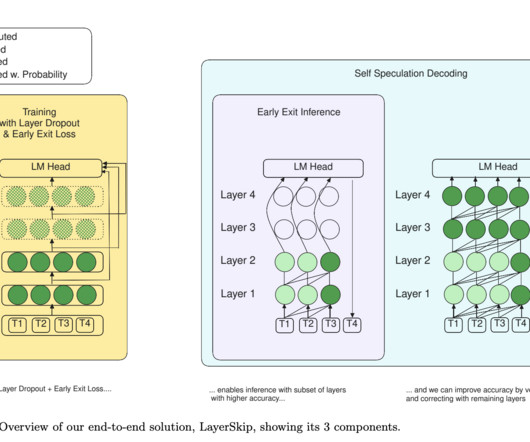
By combining layer dropout, early exit loss, and self-speculative decoding, the researchers have proposed a novel approach that not only speeds up inference but also reduces memory requirements, making it feasible for large models to be deployed on commodity hardware. Check out the Paper , Model Series on Hugging Face , and GitHub.
This is the kind of horsepower needed to handle AI-assisted digital content creation, AI super resolution in PC gaming, generating images from text or video, querying local large language models (LLMs) and more. LLM performance is measured in the number of tokens generated by the model. Tokens are the output of the LLM.
Recent advancements in LLM capabilities have increased their usability by enabling them to do a broader range of general activities autonomously. There are two main obstacles to effective LM program utilization: The non-deterministic character of LLMs makes programming LM programs tedious and complex.
The Attack Generation and Exploration Module uses an attacker LLM to generate jailbreak prompts based on strategies from the Retrieval Module. These prompts target a victim LLM, with responses evaluated by a scorer LLM. This process generates attack logs for the Strategy Library Construction Module.
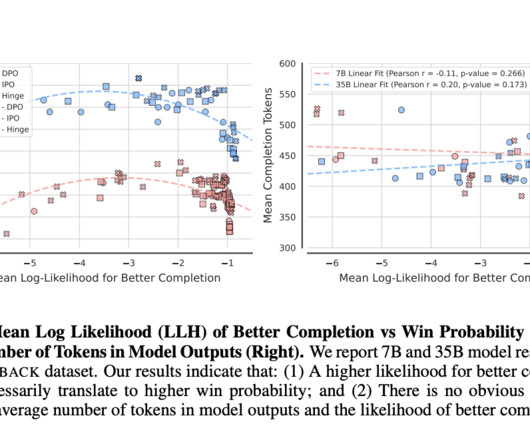
The study also employed regularization schemes like Negative Log-Likelihood (NLL) to mitigate over-optimization and evaluated generalization performance using LLM-as-a-Judge, a framework for comparing model outputs with those from other leading models. If you like our work, you will love our newsletter.
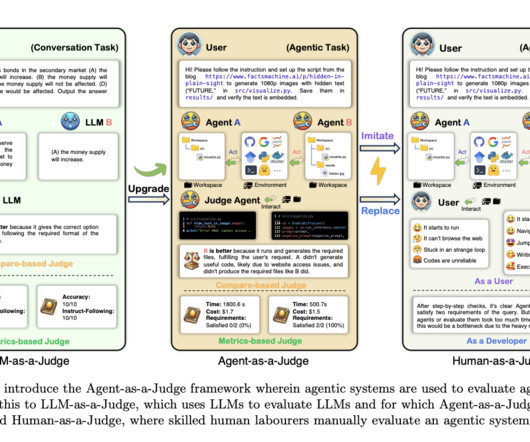
Current evaluation frameworks, such as LLM-as-a-Judge, which uses large language models to judge outputs from other AI systems, must account for the entire task-solving process. The results of the Agent-as-a-Judge framework achieved a 90% alignment with human evaluators, compared to LLM-as-a-Judge’s 70% alignment.
This is indeed a very serious challenge for the larger and more effective scaling of LLM modalities applied to real-world applications. Current solutions to alignment involve methods such as RLHF and direct preference optimization (DPO). If you like our work, you will love our newsletter. Don’t Forget to join our 50k+ ML SubReddit.
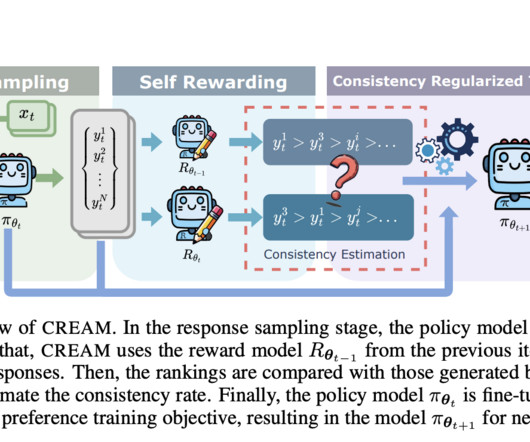
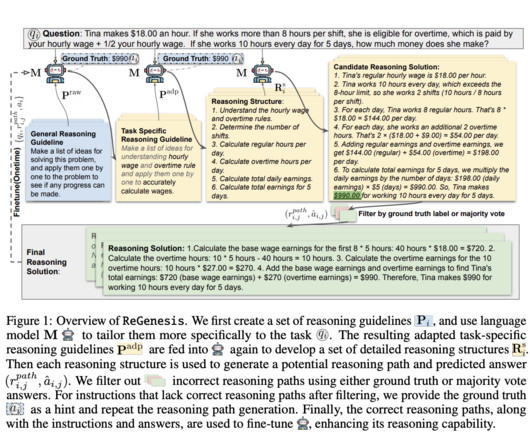
One of the critical problems faced by AI researchers is that many current methods for enhancing LLM reasoning capabilities rely heavily on human intervention. Finally, the LLM uses these reasoning structures to create detailed reasoning paths. If you like our work, you will love our newsletter.
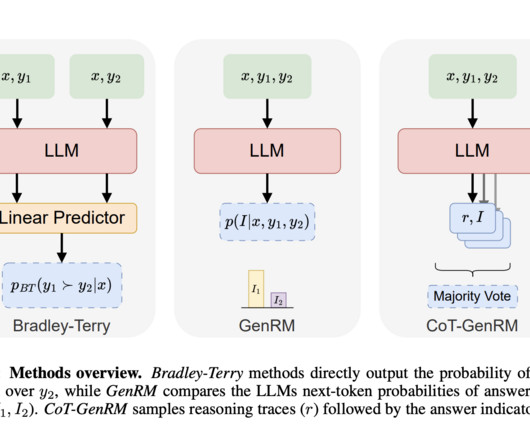
GenRM leverages a large pre-trained LLM to generate reasoning chains that help decision-making. The model also outperformed LLM-based judges, which rely solely on AI feedback, showcasing a more balanced approach to feedback optimization. If you like our work, you will love our newsletter. Don’t Forget to join our 50k+ ML SubReddit.
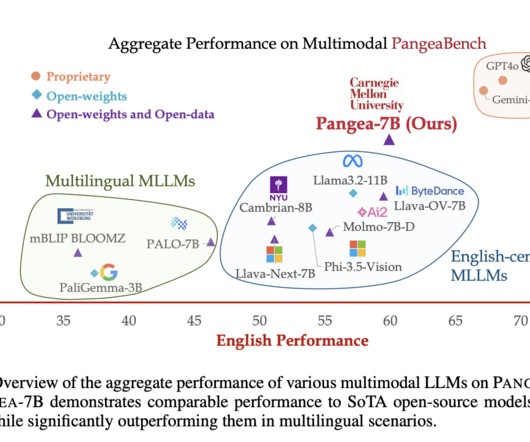
A team of researchers from Carnegie Mellon University introduced PANGEA, a multilingual multimodal LLM designed to bridge linguistic and cultural gaps in visual understanding tasks. PANGEA is trained on a newly curated dataset, PANGEAINS, which contains 6 million instruction samples across 39 languages.
For example, LLAMA3 model optimized specifically to run on NIM, giving accelerated performance on inferences. Now that we have the API key, let’s get started. Install the required packages ! pip install langchain langchain-nvidia-ai-endpoints openai langchain-community langchain-qdrant langchainhub sentence-transformers Set up the API key.
Researchers from Westlake University and Zhejiang University introduced an omni-modal LLM Baichuan-Omni alongside a multimodal training scheme designed to facilitate advanced multimodal processing and better user interactions. It also provides multilingual support for languages such as English and Chinese.
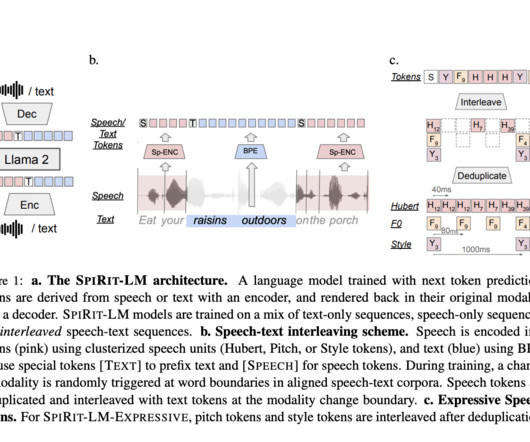
Traditionally, large language models (LLMs) used for building TTS pipelines convert speech to text using automatic speech recognition (ASR), process it using an LLM, and then convert the output back to speech via TTS. If you like our work, you will love our newsletter. Don’t Forget to join our 50k+ ML SubReddit.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content