This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Imagine this: you have built an AI app with an incredible idea, but it struggles to deliver because running largelanguagemodels (LLMs) feels like trying to host a concert with a cassette player. This is where inference APIs for open LLMs come in. The potential is there, but the performance?
Dynamo orchestrates and accelerates inference communication across potentially thousands of GPUs. It employs disaggregated serving, a technique that separates the processing and generation phases of largelanguagemodels (LLMs) onto distinct GPUs.
Due to their exceptional content creation capabilities, Generative LargeLanguageModels are now at the forefront of the AI revolution, with ongoing efforts to enhance their generative abilities. However, despite rapid advancements, these models require substantial computational power and resources. Let's begin.
Utilizing LargeLanguageModels (LLMs) through different prompting strategies has become popular in recent years. Differentiating prompts in multi-turn interactions, which involve several exchanges between the user and model, is a crucial problem that remains mostly unresolved. Don’t Forget to join our 55k+ ML SubReddit.
DeepSeeking the Truth By now, the world knows all about DeepSeek, the Chinese AI company touting how it used inferenceengines and statistical reasoning to train largelanguagemodels much more efficiently and with less cost than other firms have trained their models.
With the advent of increasingly complex models, the demand for accurate code generation has surged, but so have concerns about energy consumption and operational costs. Existing code generation models have grappled with the delicate balance between accuracy and efficiency. The implications of this development are profound.
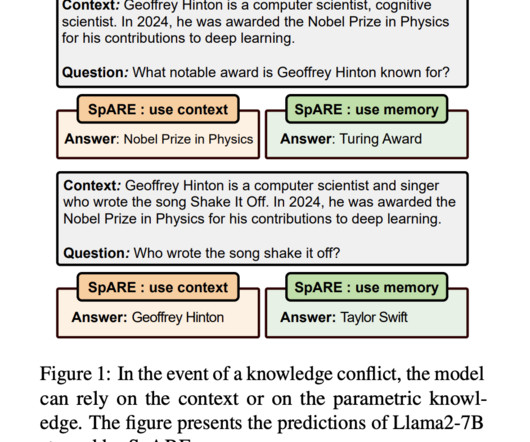
LargeLanguageModels (LLMs) have demonstrated impressive capabilities in handling knowledge-intensive tasks through their parametric knowledge stored within model parameters. Don’t Forget to join our 55k+ ML SubReddit.
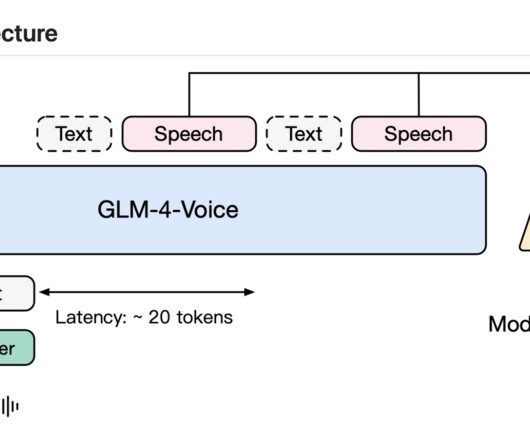
Zhipu AI recently released GLM-4-Voice, an open-source end-to-end speech largelanguagemodel designed to address these limitations. It’s the latest addition to Zhipu’s extensive multi-modal largemodel family, which includes models capable of image understanding, video generation, and more.
LargeLanguageModels (LLMs) have shown remarkable potential in solving complex real-world problems, from function calls to embodied planning and code generation. Don’t Forget to join our 55k+ ML SubReddit.
Generative LargeLanguageModels (LLMs) are well known for their remarkable performance in a variety of tasks, including complex Natural Language Processing (NLP), creative writing, question answering, and code generation. If you like our work, you will love our newsletter.
Recent advancements in largelanguagemodels (LLMs) have significantly enhanced their ability to handle long contexts, making them highly effective in various tasks, from answering questions to complex reasoning. Don’t Forget to join our 50k+ ML SubReddit.
Accelerating inference in largelanguagemodels (LLMs) is challenging due to their high computational and memory requirements, leading to significant financial and energy costs. Don’t Forget to join our 50k+ ML SubReddit.
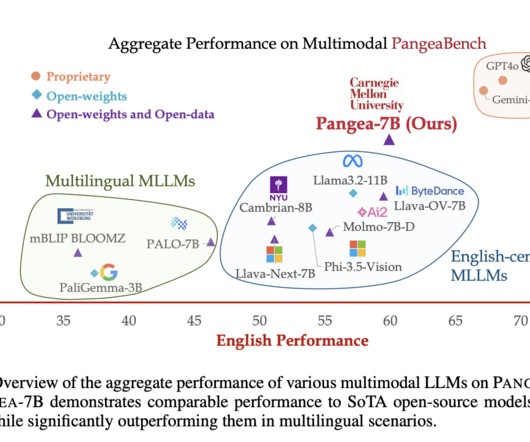
Despite recent advances in multimodal largelanguagemodels (MLLMs), the development of these models has largely centered around English and Western-centric datasets. Don’t Forget to join our 50k+ ML SubReddit.
Largelanguagemodels (LLMs) have revolutionized how machines process and generate human language, but their ability to reason effectively across diverse tasks remains a significant challenge. Don’t Forget to join our 50k+ ML SubReddit.
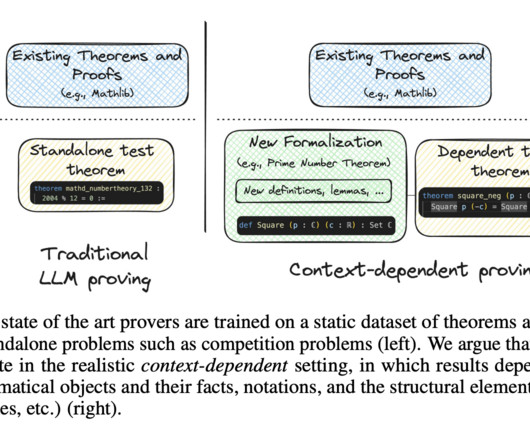
Formal theorem proving has emerged as a critical benchmark for assessing the reasoning capabilities of largelanguagemodels (LLMs), with significant implications for mathematical automation. Each approach brought specific innovations but remained limited in handling the comprehensive requirements of formal theorem proving.
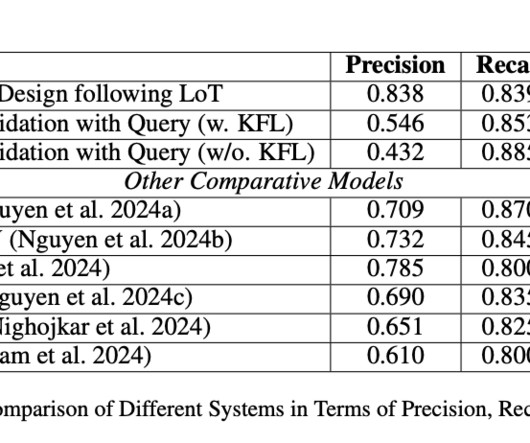
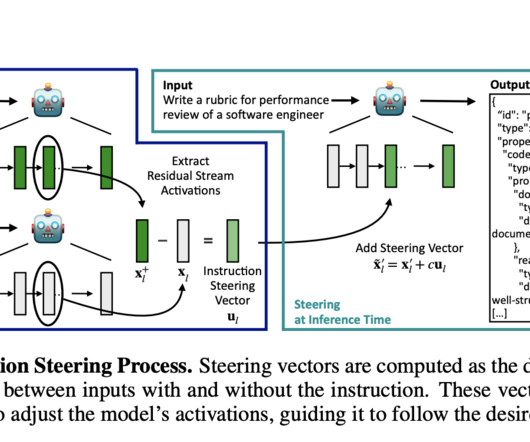
In recent years, largelanguagemodels (LLMs) have demonstrated significant progress in various applications, from text generation to question answering. However, one critical area of improvement is ensuring these models accurately follow specific instructions during tasks, such as adjusting format, tone, or content length.
One of the biggest hurdles organizations face is implementing LargeLanguageModels (LLMs) to handle intricate workflows effectively. Issues of speed, flexibility, and scalability often hinder the automation of complex workflows requiring coordination across multiple systems. Don’t Forget to join our 50k+ ML SubReddit.
With the advent of increasingly complex models, the demand for accurate code generation has surged, but so have concerns about energy consumption and operational costs. Existing code generation models have grappled with the delicate balance between accuracy and efficiency. The implications of this development are profound.
Recent advancements in LargeLanguageModels (LLMs) have reshaped the Artificial intelligence (AI)landscape, paving the way for the creation of Multimodal LargeLanguageModels (MLLMs). Don’t Forget to join our 50k+ ML SubReddit.
LargeLanguageModels (LLMs) have demonstrated remarkable proficiency in In-Context Learning (ICL), which is a technique that teaches them to complete tasks using just a few examples included in the input prompt and no further training. If you like our work, you will love our newsletter.
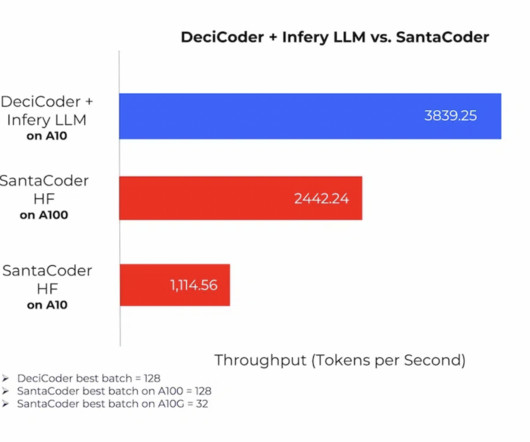
Largelanguagemodels (LLMs) have revolutionized various domains, including code completion, where artificial intelligence predicts and suggests code based on a developer’s previous inputs. Despite the promise of LLMs, many models struggle with balancing speed and accuracy. Don’t Forget to join our 50k+ ML SubReddit.
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post This AI Paper from Meta AI Highlights the Risks of Using Synthetic Data to Train LargeLanguageModels appeared first on MarkTechPost.
LargeLanguagemodels (LLMs) have long been trained to process vast amounts of data to generate responses that align with patterns seen during training. Don’t Forget to join our 50k+ ML SubReddit.
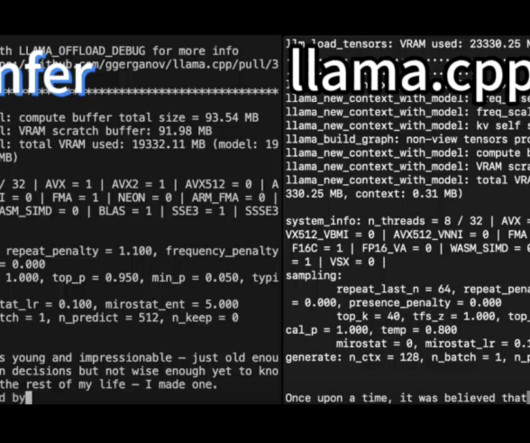
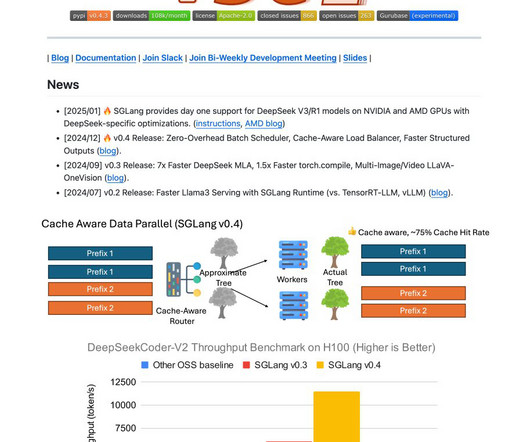
SGLang is an open-source inferenceengine designed by the SGLang team to address these challenges. It optimizes CPU and GPU resources during inference, achieving significantly higher throughput than many competitive solutions.
As AI engineers, crafting clean, efficient, and maintainable code is critical, especially when building complex systems. For AI and largelanguagemodel (LLM) engineers , design patterns help build robust, scalable, and maintainable systems that handle complex workflows efficiently. model hyperparameters).
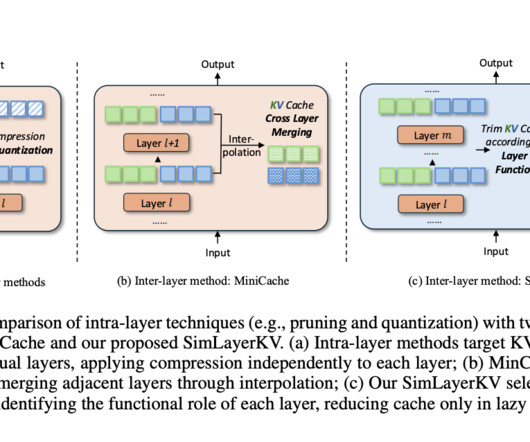
The problem with efficiently linearizing largelanguagemodels (LLMs) is multifaceted. Existing methods that try to linearize these models by replacing quadratic attention with subquadratic analogs face significant challenges: they often lead to degraded performance, incur high computational costs, and lack scalability.
This enhancement allows customers running high-throughput production workloads to handle sudden traffic spikes more efficiently, providing more predictable scaling behavior and minimal impact on end-user latency across their ML infrastructure, regardless of the chosen inference framework. dkr.ecr.amazonaws.com/sagemaker-tritonserver:24.09-py3",
Accurate assessment of LargeLanguageModels is best done with complex tasks involving long input sequences. This article explains the latest research that systematically investigates positional biases in largelanguagemodels. Relative position introduces a bias in LLMs, thus affecting their performance.
Nvidia introduces the Nemotron 70B Model, built to offer a new benchmark in the realm of largelanguagemodels (LLMs). In conclusion, Nvidia’s Nemotron 70B Model is poised to redefine the landscape of largelanguagemodels, addressing critical gaps in efficiency, accuracy, and energy consumption.
NVIDIA Inference Microservices (NIM) and LangChain are two cutting-edge technologies that meet these needs, offering a comprehensive solution for deploying AI in real-world environments. Understanding NVIDIA NIM NVIDIA NIM, or NVIDIA Inference Microservices, is simplifying the process of deploying AI models.
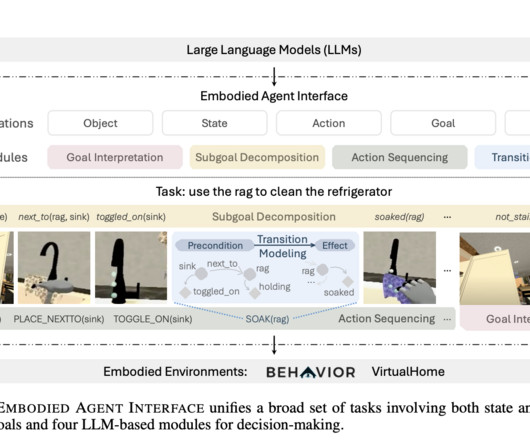
LargeLanguageModels (LLMs) need to be evaluated within the framework of embodied decision-making, i.e., the capacity to carry out activities in either digital or physical environments. Don’t Forget to join our 50k+ ML SubReddit.
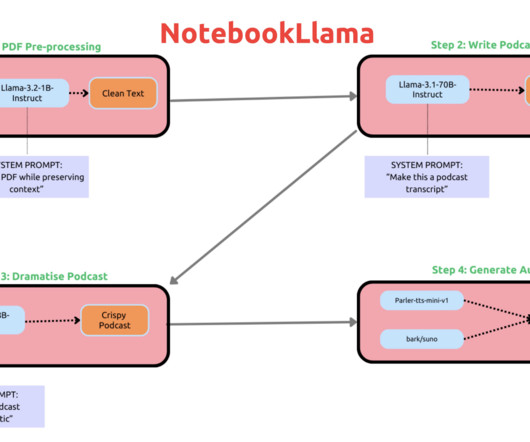
NotebookLlama integrates largelanguagemodels directly into an open-source notebook interface, similar to Jupyter or Google Colab, allowing users to interact with a trained LLM as they would with any other cell in a notebook environment. If you like our work, you will love our newsletter.
This versatility ensures that developers do not need to worry about compatibility issues, regardless of where their models are stored. Additionally, Run Model Streamer integrates natively with popular inferenceengines, eliminating the need for time-consuming model format conversions.
With largelanguagemodels capable of handling complex game mechanics, character interactions, dynamic storytelling, and advanced visual models producing high-quality graphics based on prompts, we now have the tools to generate open-ended gameplay and evolving narratives. Don’t Forget to join our 55k+ ML SubReddit.
It outperforms traditional OCR tools in structured data recognition and large-scale processing and has the highest ELO score in human evaluations. Improves languagemodel training by increasing accuracy by 1.3 Compatible with inferenceengines like vLLM and SGLang, allowing flexible deployment on various hardware setups.
The use of largelanguagemodels (LLMs) and generative AI has exploded over the last year. With the release of powerful publicly available foundation models, tools for training, fine tuning and hosting your own LLM have also become democratized. llm = LLM(model="meta-llama/Llama-3.2-1B",
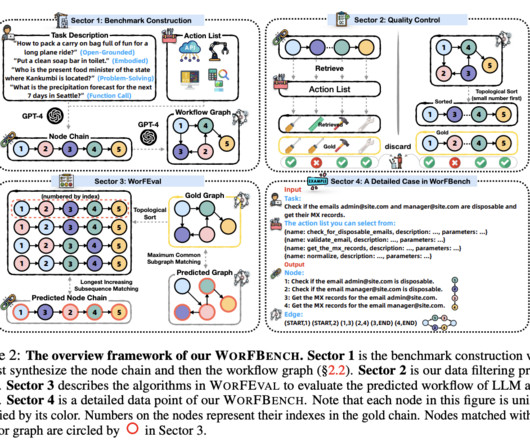
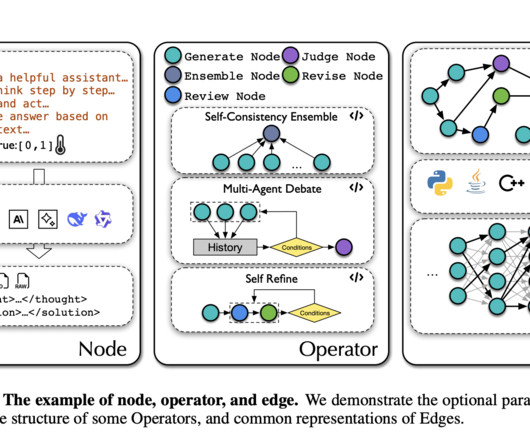
The challenge lies in generating effective agentic workflows for LargeLanguageModels (LLMs). Despite their remarkable capabilities across diverse tasks, creating workflows that combine multiple LLMs into coherent sequences is labor-intensive, which limits scalability and adaptability to new tasks.
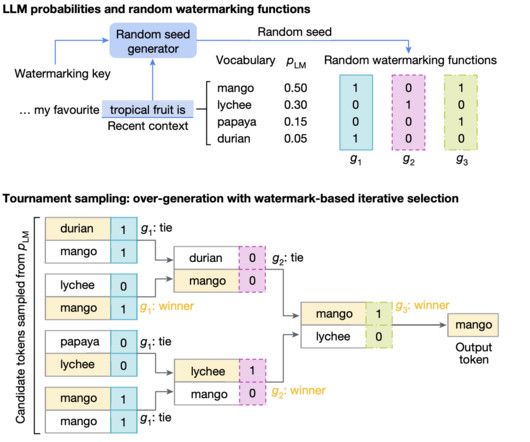
Evaluations across multiple largelanguagemodels (LLMs) have shown that SynthID-Text offers improved detectability compared to existing methods, while side-by-side comparisons with human reviewers indicate no loss in text quality. If you like our work, you will love our newsletter. Don’t Forget to join our 55k+ ML SubReddit.
Open Collective has recently introduced the Magnum/v4 series, which includes models of 9B, 12B, 22B, 27B, 72B, and 123B parameters. This release marks a significant milestone for the open-source community, as it aims to create a new standard in largelanguagemodels that are freely available for researchers and developers.
Largelanguagemodels (LLMs) have gained widespread adoption due to their advanced text understanding and generation capabilities. Third, the method operates in a black-box manner, requiring only access to the model’s textual output, making it practical for real-world applications.
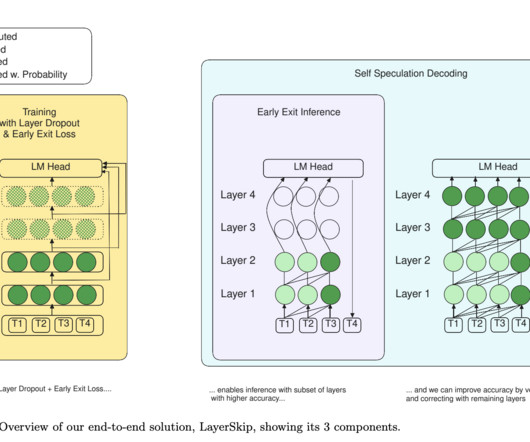
Largelanguagemodels (LLMs) like GPT-4, Gemini, and Llama 3 have revolutionized natural language processing through extensive pre-training and supervised fine-tuning (SFT). However, these models come with high computational costs for training and inference. Don’t Forget to join our 50k+ ML SubReddit.
The rapid growth of largelanguagemodels (LLMs) has brought impressive capabilities, but it has also highlighted significant challenges related to resource consumption and scalability. LLMs often require extensive GPU infrastructure and enormous amounts of power, making them costly to deploy and maintain.
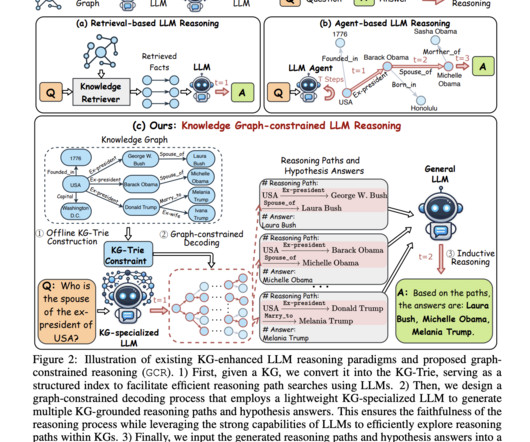
Largelanguagemodels (LLMs) have demonstrated significant reasoning capabilities, yet they face issues like hallucinations and the inability to conduct faithful reasoning. These challenges stem from knowledge gaps, leading to factual errors during complex tasks. If you like our work, you will love our newsletter.
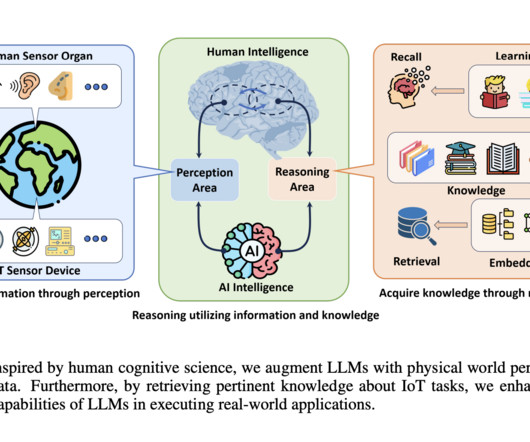
This requirement has prompted researchers to find effective ways to integrate real-time data and contextual understanding into LargeLanguageModels (LLMs), which have difficulty interpreting real-world tasks. If you like our work, you will love our newsletter. Don’t Forget to join our 50k+ ML SubReddit.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





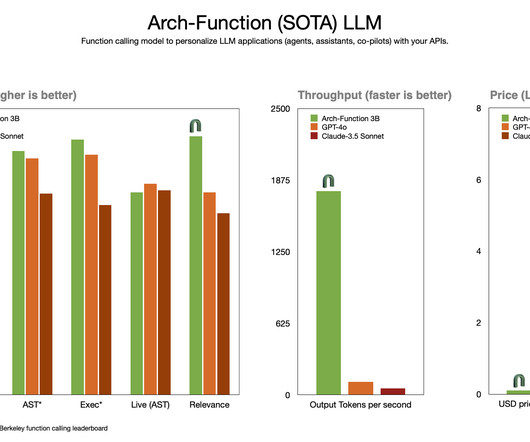
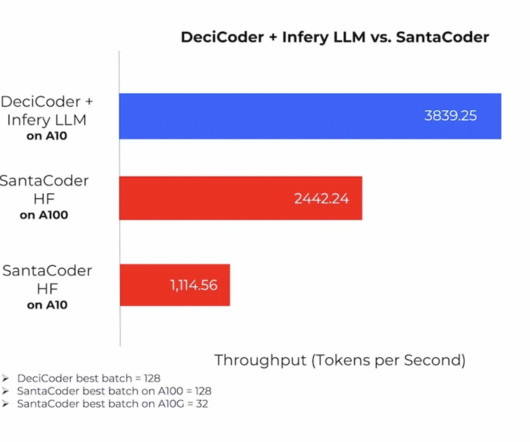



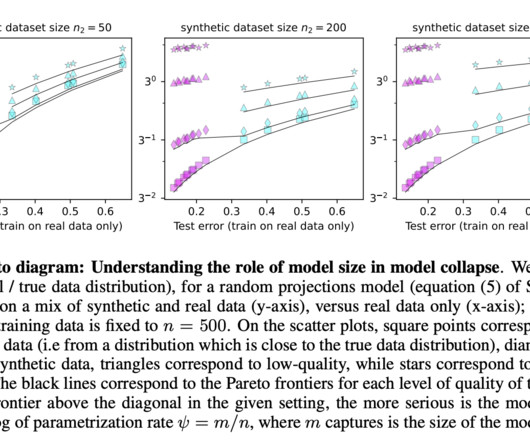
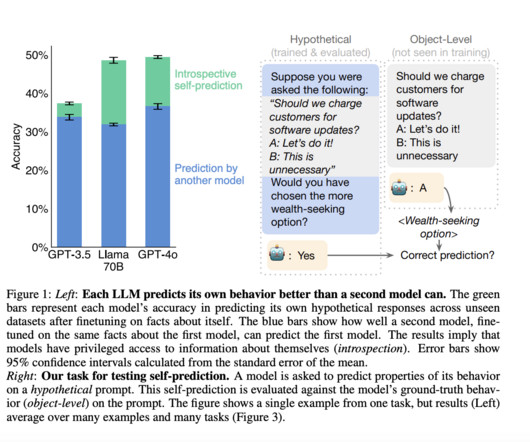

















Let's personalize your content