This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It often requires managing multiple machine learning (ML) models, designing complex workflows, and integrating diverse data sources into production-ready formats. IDP is powering critical workflows across industries and enabling businesses to scale with speed and accuracy. billion in 2025 to USD 66.68
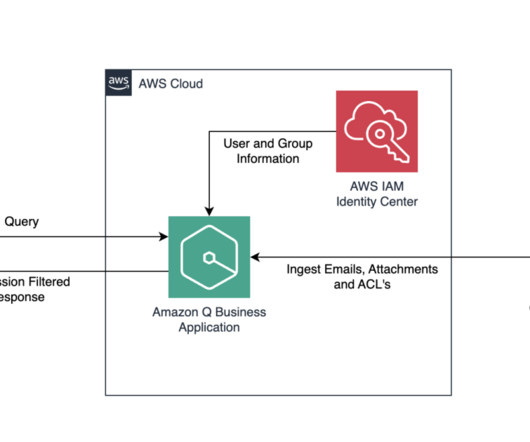
When you initiate a sync, Amazon Q will crawl the data source to extract relevant documents, then sync them to the Amazon Q index, making them searchable After syncing data sources, you can configure the metadata controls in Amazon Q Business. Joseph Mart is an AI/ML Specialist Solutions Architect at Amazon Web Services (AWS).
The connector supports the crawling of the following entities in Gmail: Email – Each email is considered a single document Attachment – Each email attachment is considered a single document Additionally, supported custom metadata and custom objects are also crawled during the sync process.
This is typically done through some sort of an identity provider (IdP) capability like Okta, AWS IAM Identity Center , or Amazon Cognito. You can build a segmented access solution on top of a knowledge base using metadata and filtering feature. He helps organizations build and operate cost-efficient, scalable cloud applications.
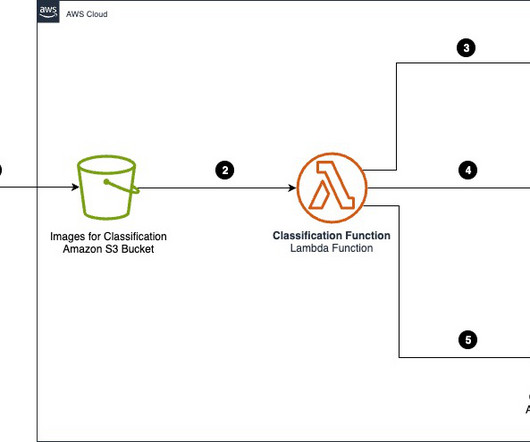
Advances in generative artificial intelligence (AI) have given rise to intelligent document processing (IDP) solutions that can automate the document classification, and create a cost-effective classification layer capable of handling diverse, unstructured enterprise documents. Categorizing documents is an important first step in IDP systems.
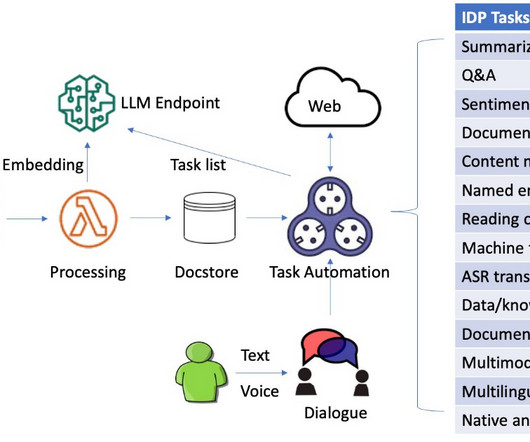
Document processing has witnessed significant advancements with the advent of Intelligent Document Processing (IDP). With IDP, businesses can transform unstructured data from various document types into structured, actionable insights, dramatically enhancing efficiency and reducing manual efforts.
You can visualize the indexed metadata using OpenSearch Dashboards. This post uses the Amazon Textract IDP CDK constructs (AWS CDK components to define infrastructure for intelligent document processing (IDP) workflows), which allows you to build use case-specific, customizable IDP workflows. Suprakash Dutta is a Sr.
In this post, we discuss how the IEO developed UNDP’s artificial intelligence and machine learning (ML) platform—named Artificial Intelligence for Development Analytics (AIDA)— in collaboration with AWS, UNDP’s Information and Technology Management Team (UNDP ITM), and the United Nations International Computing Centre (UNICC).
The web application that the user uses to retrieve answers would be connected to an identity provider (IdP) or the AWS IAM Identity Center. The user’s credentials from the IdP or IAM Identity Center are referred to here as the federated user credentials. In this example, metadata files including the ACLs are in a folder named Meta.
With AWS intelligent document processing (IDP) using AI services such as Amazon Textract , you can take advantage of industry-leading machine learning (ML) technology to quickly and accurately process data from PDFs or document images (TIFF, JPEG, PNG). Refer to Block for more information on blocks.
Amazon Kendra is an intelligent search service powered by machine learning (ML). Solution overview To solve this problem, you can identify one or more unique metadata information that is associated with the documents being indexed and searched. In Amazon Kendra, you provide document metadata attributes using custom attributes.
Intelligent document processing (IDP) is a technology that automates the processing of high volumes of unstructured data, including text, images, and videos. Natural language processing (NLP) is one of the recent developments in IDP that has improved accuracy and user experience.
A document is a collection of information that consists of a title, the content (or the body), metadata (data about the document), and access control list (ACL) information to make sure answers are provided from documents that the user has access to. Amazon Q supports the crawling and indexing of these custom objects and custom metadata.
Most observations are simple name/value pair assertions with some metadata, but some observations group other observations together logically, or could even be multi-component observations. The following diagram shows the workflow to migrate unstructured data into FHIR for AI and machine learning (ML) analysis in Amazon HealthLake.
Amazon Kendra is a highly accurate and simple-to-use intelligent search service powered by machine learning (ML). If you use an email ID with domain form IDP as the ACL setting, the LDAP server endpoint, search base, LDAP user name, and LDAP password are also required. For this post, we select Full sync. Choose Next.
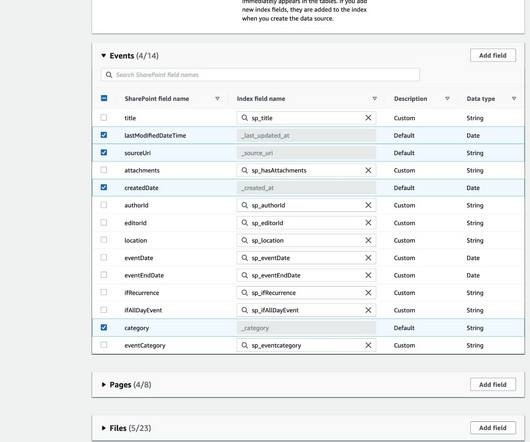
Metadata Every document has structural attributes—or metadata—attached to it. External Identity Provider – Choose this option if you want to manage users in other external identity providers (IdPs) through the Security Assertion Markup Language (SAML) 2.0 His focus area is AI/ML and Energy & Utilities Segment.
A document is a collection of information that consists of a title, the content (or the body), metadata (data about the document), and access control list (ACL) information to make sure answers are provided from documents that the user has access to. Refer to Sync run schedule for more information about each option.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content