This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Developing generativeAI agents that can tackle real-world tasks is complex, and building production-grade agentic applications requires integrating agents with additional tools such as user interfaces, evaluation frameworks, and continuous improvement mechanisms.
Building a deployment pipeline for generative artificial intelligence (AI) applications at scale is a formidable challenge because of the complexities and unique requirements of these systems. GenerativeAI models are constantly evolving, with new versions and updates released frequently.
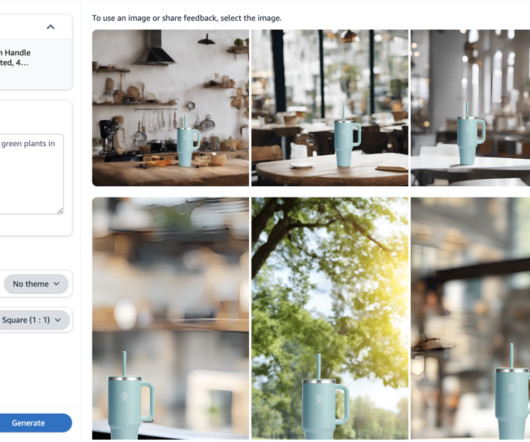
To help advertisers more seamlessly address this challenge, Amazon Ads rolled out an image generation capability that quickly and easily develops lifestyle imagery, which helps advertisers bring their brand stories to life. Here, Amazon SageMaker Ground Truth allowed MLengineers to easily build the human-in-the-loop workflow (step v).
Large enterprises are building strategies to harness the power of generativeAI across their organizations. Managing bias, intellectual property, prompt safety, and data integrity are critical considerations when deploying generativeAI solutions at scale.
Nowadays, the majority of our customers is excited about large language models (LLMs) and thinking how generativeAI could transform their business. In this post, we discuss how to operationalize generativeAI applications using MLOps principles leading to foundation model operations (FMOps).
GenerativeAI has emerged as a transformative force, captivating industries with its potential to create, innovate, and solve complex problems. Machine learning (ML) engineers must make trade-offs and prioritize the most important factors for their specific use case and business requirements.
Introduction to AI and Machine Learning on Google Cloud This course introduces Google Cloud’s AI and ML offerings for predictive and generative projects, covering technologies, products, and tools across the data-to-AI lifecycle. It also introduces Google’s 7 AI principles.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Today, generativeAI can enable people without SQL knowledge. Therefore, collecting comprehensive and high-quality metadata also remains a challenge. We use Anthropic Claude v2.1 on Amazon Bedrock as our LLM.
By investing in robust evaluation practices, companies can maximize the benefits of LLMs while maintaining responsible AI implementation and minimizing potential drawbacks. To support robust generativeAI application development, its essential to keep track of models, prompt templates, and datasets used throughout the process.
At AWS re:Invent 2024, we launched a new innovation in Amazon SageMaker HyperPod on Amazon Elastic Kubernetes Service (Amazon EKS) that enables you to run generativeAI development tasks on shared accelerated compute resources efficiently and reduce costs by up to 40%. queue-name: hyperpod-ns-researchers-localqueue kueue.x-k8s.io/priority-class:
This short course also includes guidance on using Google tools to develop your own GenerativeAI apps. Prompt Engineering with LLaMA-2 Difficulty Level: Beginner This course covers the prompt engineering techniques that enhance the capabilities of large language models (LLMs) like LLaMA-2.
Artificial intelligence (AI) and machine learning (ML) are becoming an integral part of systems and processes, enabling decisions in real time, thereby driving top and bottom-line improvements across organizations. However, putting an ML model into production at scale is challenging and requires a set of best practices.
However, model governance functions in an organization are centralized and to perform those functions, teams need access to metadata about model lifecycle activities across those accounts for validation, approval, auditing, and monitoring to manage risk and compliance. An experiment collects multiple runs with the same objective.
However, businesses can meet this challenge while providing personalized and efficient customer service with the advancements in generative artificial intelligence (generativeAI) powered by large language models (LLMs). GenerativeAI chatbots have gained notoriety for their ability to imitate human intellect.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. Recent developments in generativeAI models have further sped up the need of ML adoption across industries.
In this session, you will explore the flow of Imperva’s botnet detection, including data extraction, feature selection, clustering, validation, and fine-tuning, as well as the organization’s method for measuring the results of unsupervised learning problems using a query engine. Should you have manual sign-offs?
This post is co-written with Jad Chamoun, Director of Engineering at Forethought Technologies, Inc. and Salina Wu, Senior MLEngineer at Forethought Technologies, Inc. Forethought is a leading generativeAI suite for customer service.
Fine-tuning an LLM can be a complex workflow for data scientists and machine learning (ML) engineers to operationalize. By logging your datasets with MLflow, you can store metadata, such as dataset descriptions, version numbers, and data statistics, alongside your MLflow runs.
Additionally, VitechIQ includes metadata from the vector database (for example, document URLs) in the model’s output, providing users with source attribution and enhancing trust in the generated answers. Prompt engineering Prompt engineering is crucial for the knowledge retrieval system. “We
You will notice the content of this file as JSON with a text transcript available under the key transcripts, along with other metadata. Rushabh Lokhande is a Senior Data & MLEngineer with AWS Professional Services Analytics Practice. You can download a sample file and review the contents.
Specialist Data Engineering at Merck, and Prabakaran Mathaiyan, Sr. MLEngineer at Tiger Analytics. The large machine learning (ML) model development lifecycle requires a scalable model release process similar to that of software development. This post is co-written with Jayadeep Pabbisetty, Sr.
Repository Information**: Not shown in the provided excerpt, but likely contains metadata about the repository. Search for the embedding and text generation endpoints. Specialist Solutions Architect focused on generativeAI strategy, applied AI solutions, and conducting research to help customers hyper-scale on AWS.
At ODSC East 2025 , were excited to present 12 curated tracks designed to equip data professionals, machine learning engineers, and AI practitioners with the tools they need to thrive in this dynamic landscape. Whats Next in AI TrackExplore the Cutting-Edge Stay ahead of the curve with insights into the future of AI.
Amazon SageMaker provides purpose-built tools for machine learning operations (MLOps) to help automate and standardize processes across the ML lifecycle. In this post, we describe how Philips partnered with AWS to develop AI ToolSuite—a scalable, secure, and compliant ML platform on SageMaker.
His area of focus is generativeAI and AWS AI Accelerators. Niithiyn works closely with the GenerativeAI GTM team to enable AWS customers on multiple fronts and accelerate their adoption of generativeAI. Rohit Talluri is a GenerativeAI GTM Specialist (Tech BD) at Amazon Web Services (AWS).
The risks associated with generativeAI have been well-publicized. Research shows that not only do risks for bias and toxicity transfer from pre-trained foundation models (FM) to task-specific generativeAI services, but that tuning an FM for specific tasks, on incremental datasets, introduces new and possibly greater risks.
Similarly, a study by Meta AI and Carnegie Melon university found that, in the worst cases, 43 percent of compute time was wasted because of overheads due to hardware failures. This can adversely impact a customer’s ability to keep up with the pace of innovation in generativeAI and can also increase the time-to-market for their models.
I see so many of these job seekers, especially on the MLOps side or the MLengineer side. There’s no component that stores metadata about this feature store? Mikiko Bazeley: In the case of the literal feature store, all it does is store features and metadata. Aurimas: Was it content generation? It’s two things.
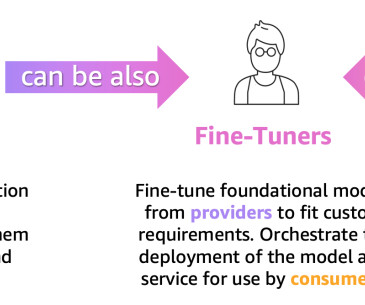
An evaluation is a task used to measure the quality and responsibility of output of an LLM or generativeAI service. Based on this tenet, we can classify generativeAI users who need LLM evaluation capabilities into 3 groups as shown in the following figure: model providers, fine-tuners, and consumers.
The application needs to search through the catalog and show the metadata information related to all of the data assets that are relevant to the search context. This allows FMs to retain their inductive abilities while grounding their language understanding and generation in well-structured domain knowledge and logical reasoning.
Customers across all industries are experimenting with generativeAI to accelerate and improve business outcomes. They contribute to the effectiveness and feasibility of generativeAI applications across various domains.
When using generativeAI, achieving high performance with low latency models that are cost-efficient is often a challenge, because these goals can clash with each other. With Amazon Bedrock Model Distillation, you can now customize models for your use case using synthetic data generated by highly capable models.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content