This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Evaluating large language models (LLMs) is crucial as LLM-based systems become increasingly powerful and relevant in our society. Rigorous testing allows us to understand an LLMs capabilities, limitations, and potential biases, and provide actionable feedback to identify and mitigate risk.
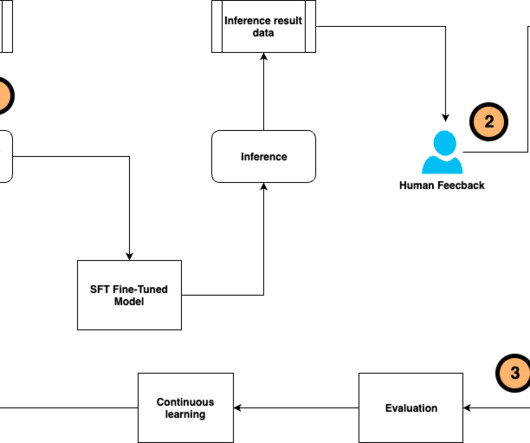
Fine-tuning a pre-trained large language model (LLM) allows users to customize the model to perform better on domain-specific tasks or align more closely with human preferences. You can use supervised fine-tuning (SFT) and instruction tuning to train the LLM to perform better on specific tasks using human-annotated datasets and instructions.
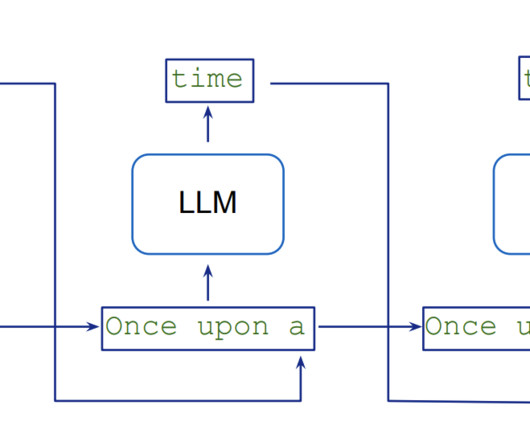
Researchers developed Medusa , a framework to speed up LLM inference by adding extra heads to predict multiple tokens simultaneously. This post demonstrates how to use Medusa-1, the first version of the framework, to speed up an LLM by fine-tuning it on Amazon SageMaker AI and confirms the speed up with deployment and a simple load test.
Amazon SageMaker is a cloud-based machine learning (ML) platform within the AWS ecosystem that offers developers a seamless and convenient way to build, train, and deploy ML models. He focuses on architecting and implementing large-scale generativeAI and classic ML pipeline solutions.
Large language models (LLMs) have achieved remarkable success in various natural language processing (NLP) tasks, but they may not always generalize well to specific domains or tasks. You may need to customize an LLM to adapt to your unique use case, improving its performance on your specific dataset or task.
Generative artificial intelligence (generativeAI) has enabled new possibilities for building intelligent systems. Recent improvements in GenerativeAI based large language models (LLMs) have enabled their use in a variety of applications surrounding information retrieval.
In part 1 of this blog series, we discussed how a large language model (LLM) available on Amazon SageMaker JumpStart can be fine-tuned for the task of radiology report impression generation. You can securely integrate and deploy generativeAI capabilities into your applications using the AWS services you are already familiar with.
Nowadays, the majority of our customers is excited about large language models (LLMs) and thinking how generativeAI could transform their business. In this post, we discuss how to operationalize generativeAI applications using MLOps principles leading to foundation model operations (FMOps).
Large enterprises are building strategies to harness the power of generativeAI across their organizations. Managing bias, intellectual property, prompt safety, and data integrity are critical considerations when deploying generativeAI solutions at scale.
This transcription then serves as the input for a powerful LLM, which draws upon its vast knowledge base to provide personalized, context-aware responses tailored to your specific situation. LLM integration The preprocessed text is fed into a powerful LLM tailored for the healthcare and life sciences (HCLS) domain.
Building a deployment pipeline for generative artificial intelligence (AI) applications at scale is a formidable challenge because of the complexities and unique requirements of these systems. GenerativeAI models are constantly evolving, with new versions and updates released frequently. We use Python to do this.
Clean up To clean up the model and endpoint, use the following code: predictor.delete_model() predictor.delete_endpoint() Conclusion In this post, we explored how SageMaker JumpStart empowers data scientists and MLengineers to discover, access, and run a wide range of pre-trained FMs for inference, including the Falcon 3 family of models.
Perfect for developers and data scientists looking to push the boundaries of AI-powered assistants. With real-world examples from regulated industries, this session equips data scientists, MLengineers, and risk professionals with the skills to build more transparent and accountable AIsystems.
GenerativeAI has emerged as a transformative force, captivating industries with its potential to create, innovate, and solve complex problems. Machine learning (ML) engineers must make trade-offs and prioritize the most important factors for their specific use case and business requirements.
Introduction to AI and Machine Learning on Google Cloud This course introduces Google Cloud’s AI and ML offerings for predictive and generative projects, covering technologies, products, and tools across the data-to-AI lifecycle. It also introduces Google’s 7 AI principles.
Top 5 GenerativeAI Integration Companies to Drive Customer Support in 2023 If you’ve been following the buzz around ChatGPT, OpenAI, and generativeAI, it’s likely that you’re interested in finding the best GenerativeAI integration provider for your business.
However, businesses can meet this challenge while providing personalized and efficient customer service with the advancements in generative artificial intelligence (generativeAI) powered by large language models (LLMs). GenerativeAI chatbots have gained notoriety for their ability to imitate human intellect.
. 📝 Editorial: The Undisputed Champion of Open Source GenerativeAI Stability AI is synonymous with open-source generativeAI. The release of Stable Diffusion was a sort of Sputnik moment in the evolution of open-source generativeAI models.
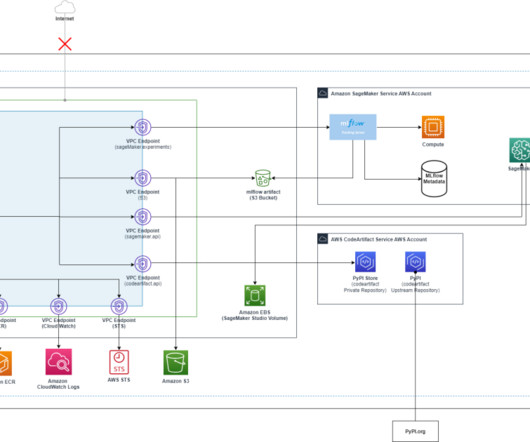
With access to a wide range of generativeAI foundation models (FM) and the ability to build and train their own machine learning (ML) models in Amazon SageMaker , users want a seamless and secure way to experiment with and select the models that deliver the most value for their business. An MLflow 2.16.2
Introduction to Large Language Models Difficulty Level: Beginner This course covers large language models (LLMs), their use cases, and how to enhance their performance with prompt tuning. This short course also includes guidance on using Google tools to develop your own GenerativeAI apps.
Today, generativeAI can enable people without SQL knowledge. This generativeAI task is called text-to-SQL, which generates SQL queries from natural language processing (NLP) and converts text into semantically correct SQL. on Amazon Bedrock as our LLM. Here, the generated SQL is sent for syntax errors.
Our proposed architecture provides a scalable and customizable solution for online LLM monitoring, enabling teams to tailor your monitoring solution to your specific use cases and requirements. We suggest that each module take incoming inference requests to the LLM, passing prompt and completion (response) pairs to metric compute modules.
Snorkel AI held its Enterprise LLM Virtual Summit on October 26, 2023, drawing an engaged crowd of more than 1,000 attendees across three hours and eight sessions that featured 11 speakers. The conversation included notes about how much time data scientists spend preparing data, and the responsibility that comes with using AI.
Healthcare and life sciences (HCLS) customers are adopting generativeAI as a tool to get more from their data. In this post, we walk you through deploying a Falcon large language model (LLM) using Amazon SageMaker JumpStart and using the model to summarize long documents with LangChain and Python.
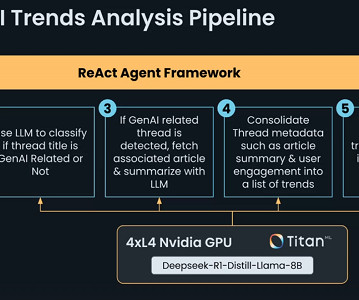
The AI agent classified and summarized GenAI-related content from Reddit, using a structured pipeline with utility functions for API interactions, web scraping, and LLM-based reasoning. The workshop underscored the value of knowledge graphs in improving AI explainability and retrieval precision.
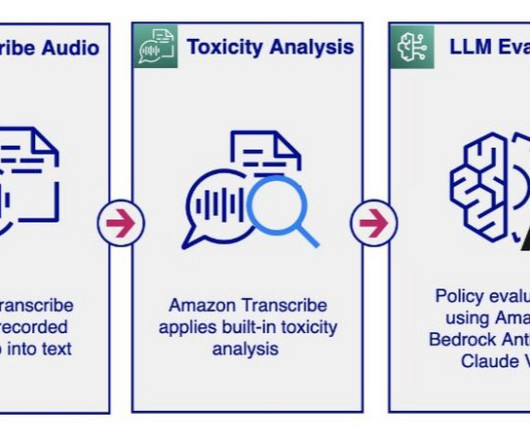
By orchestrating toxicity classification with large language models (LLMs) using generativeAI, we offer a solution that balances simplicity, latency, cost, and flexibility to satisfy various requirements. The audio moderation workflow activates the LLM’s policy evaluation only when the toxicity analysis exceeds a set threshold.
Instead, Vitech opted for Retrieval Augmented Generation (RAG), in which the LLM can use vector embeddings to perform a semantic search and provide a more relevant answer to users when interacting with the chatbot. Prompt engineering Prompt engineering is crucial for the knowledge retrieval system.
Machine learning (ML) engineers have traditionally focused on striking a balance between model training and deployment cost vs. performance. This is important because training ML models and then using the trained models to make predictions (inference) can be highly energy-intensive tasks.
Amazon Bedrock also provides a broad set of capabilities needed to build generativeAI applications with security, privacy, and responsible AI practices. However, deploying customized FMs to support generativeAI applications in a secure and scalable manner isn’t a trivial task.
Snorkel AI held its Enterprise LLM Virtual Summit on October 26, 2023, drawing an engaged crowd of more than 1,000 attendees across three hours and eight sessions that featured 11 speakers. The conversation included notes about how much time data scientists spend preparing data, and the responsibility that comes with using AI.
You can now create an end-to-end workflow to train, fine tune, evaluate, register, and deploy generativeAI models with the visual designer for Amazon SageMaker Pipelines. Create a complete AI/ML pipeline for fine-tuning an LLM using drag-and-drop functionality. But fine-tuning an LLM just once isn’t enough.
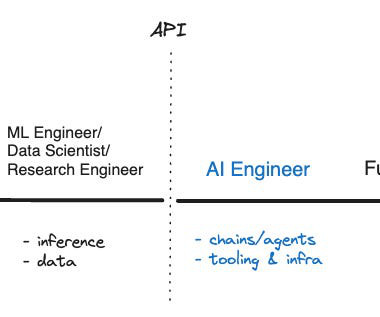
GenerativeAI and Large Language Models (LLMs) are new to most companies. If you are an engineering leader building Gen AI applications, it can be hard to know what skills and types of people are needed. At the same time, the capabilities of AI models have grown.
About Building LLMs for Production GenerativeAI and LLMs are transforming industries with their ability to understand and generate human-like text and images. However, building reliable and scalable LLM applications requires a lot of extra work and a deep understanding of various techniques and frameworks.
HuggingFace open-sourced a series of small, high-performance LLMs. Even by the crazy standards of the generativeAI market, last week was a remarkable week in terms of model releases. Proven-Verifier Games in LLMs OpenAI published a paper unveiling a prover-verifier game to improve the legibility of LLM outputs.
The rapid advancements in artificial intelligence and machine learning (AI/ML) have made these technologies a transformative force across industries. According to a McKinsey study , across the financial services industry (FSI), generativeAI is projected to deliver over $400 billion (5%) of industry revenue in productivity benefits.
Snorkel AI held its Enterprise LLM Virtual Summit on October 26, 2023, drawing an engaged crowd of more than 1,000 attendees across three hours and eight sessions that featured 11 speakers. The conversation included notes about how much time data scientists spend preparing data, and the responsibility that comes with using AI.
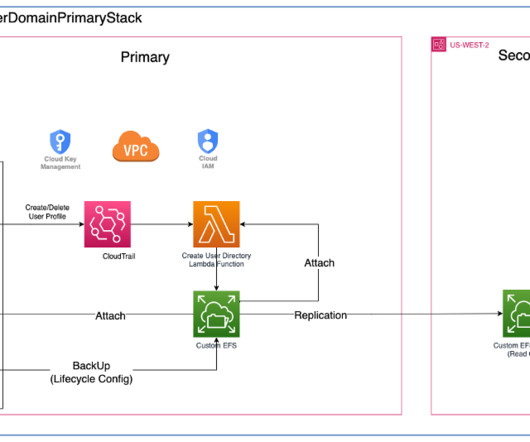
Specialist Data Engineering at Merck, and Prabakaran Mathaiyan, Sr. MLEngineer at Tiger Analytics. The large machine learning (ML) model development lifecycle requires a scalable model release process similar to that of software development. This post is co-written with Jayadeep Pabbisetty, Sr.
This significantly reduces the time you spend setting up your environment and decreases the complexity of managing package dependencies in your ML project. Amazon CodeWhisperer integration – Code Editor also comes with generativeAI capabilities powered by Amazon CodeWhisperer. You can find the sample code in this GitHub repo.
The introduction of generativeAI provides another opportunity for Thomson Reuters to work with customers and once again advance how they do their work, helping professionals draw insights and automate workflows, enabling them to focus their time where it matters most.
The risks associated with generativeAI have been well-publicized. Research shows that not only do risks for bias and toxicity transfer from pre-trained foundation models (FM) to task-specific generativeAI services, but that tuning an FM for specific tasks, on incremental datasets, introduces new and possibly greater risks.
At ODSC East 2025 , were excited to present 12 curated tracks designed to equip data professionals, machine learning engineers, and AI practitioners with the tools they need to thrive in this dynamic landscape. This track dives into the design, development, and deployment of intelligent agents that leverage LLMs and machine learning.
In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows. This often means the method of using a third-party LLM API won’t do for security, control, and scale reasons.
However, with the advent of LLM, everything has changed. LLMs seem to rule them all, and interestingly, no one knows how LLMs work. Now, people are questioning whether they should still develop solutions other than LLM but know little about how to make LLM-based solutions accountable. Everyone was happy.
Configuration files (YAML and JSON) allow ML practitioners to specify undifferentiated code for orchestrating training pipelines using declarative syntax. The following are the key benefits of this solution: Automation – The entire ML workflow, from data preprocessing to model registry, is orchestrated with no manual intervention.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































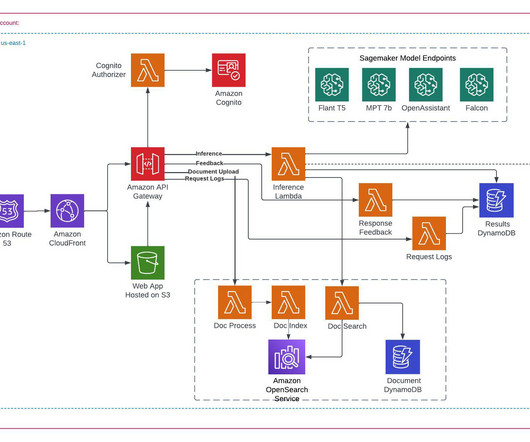


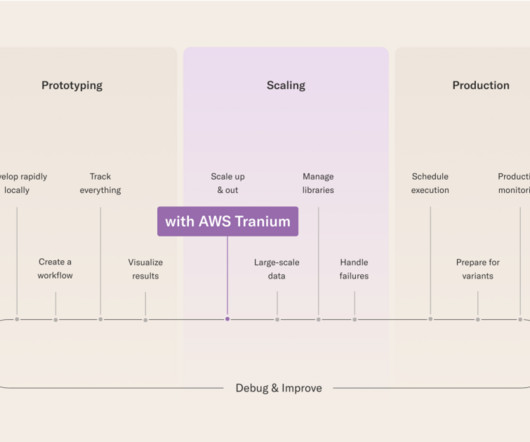

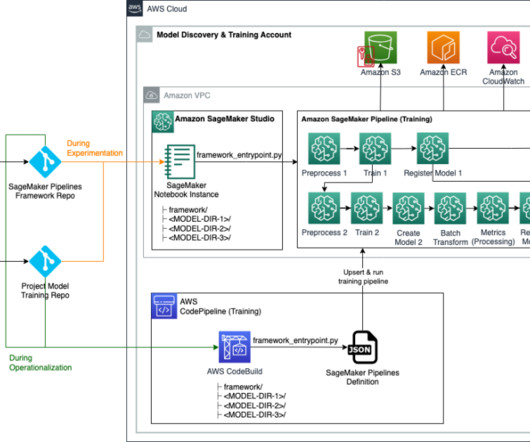






Let's personalize your content