This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generativeAI models for inference. The implementation of Container Caching for running Llama3.1
Elon Musks xAI has introduced Grok-3 , a next-generationAI chatbot designed to change the way people interact on social media. A powerful feature of Grok-3 is its integration with Deep Search, a next-generationAI-powered search engine.
This stack, which boasts a decoding throughput four times faster than the open-source vLLM, surpasses leading commercial solutions like Amazon Bedrock, Azure AI, Fireworks, and Octo AI by 1.3x Together Lite endpoints leverage INT4 quantization for the most cost-efficient and scalable Llama 3 models available, priced at just $0.10
NVIDIA AI Foundry is a service that enables enterprises to use data, accelerated computing and software tools to create and deploy custom models that can supercharge their generativeAI initiatives. Using the NeMo platform in NVIDIA AI Foundry, businesses can create custom AI models that are precisely tailored to their needs.
However, recent advancements in generativeAI have opened up new possibilities for creating an infinite game experience. Don’t Forget to join our 55k+ ML SubReddit.
Proprietary Cloud Platform : The CLUSTER ENGINE is a proprietary cloud management system that optimizes resource scheduling, providing a flexible and efficient cluster management solution Add inferenceengine roadmap : Continuous computing, guarantee high SLA. Anyone should be able to build their AI application.
Last Updated on July 3, 2024 by Editorial Team Author(s): Suhaib Arshad Originally published on Towards AI. Image source) There has been a drastic increase in number of generativeAI products since the debut of ChatGPT in 2022. This is when NVIDIA NIM comes into the picture. What is Nvidia Nim?
Understanding NVIDIA NIM NVIDIA NIM, or NVIDIA Inference Microservices, is simplifying the process of deploying AI models. This rapid deployment capability enables developers to quickly build generativeAI applications like copilots, chatbots, and digital avatars, significantly boosting productivity.
The use of large language models (LLMs) and generativeAI has exploded over the last year. Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. In his current role, he works on optimizing training and inference of generativeAI models on AWS AI chips.
Moreover, to operate smoothly, generativeAI models rely on thousands of GPUs, leading to significant operational costs. The high operational demands are a key reason why generativeAI models are not yet effectively deployed on personal-grade devices. Let's begin.
NVIDIA and Google Cloud have announced a new collaboration to help startups around the world accelerate the creation of generativeAI applications and services. Startups in particular are constrained by the high costs associated with AI investments. DGX Cloud with GB200 NVL72 will also be available on Google Cloud in 2025.
Black Forest Labs is not just another AI startup; it's a powerhouse of talent with a track record of developing foundational generativeAI models. The team includes the creators of VQGAN, Latent Diffusion, and the Stable Diffusion family of models that have taken the AI art world by storm.
GenerativeAI has become a common tool for enhancing and accelerating the creative process across various industries, including entertainment, advertising, and graphic design. One significant benefit of generativeAI is creating unique and personalized experiences for users. amazonaws.com/djl-inference:0.21.0-deepspeed0.8.3-cu117"
Current generativeAI models face challenges related to robustness, accuracy, efficiency, cost, and handling nuanced human-like responses. There is a need for more scalable and efficient solutions that can deliver precise outputs while being practical for diverse AI applications. Don’t Forget to join our 50k+ ML SubReddit.
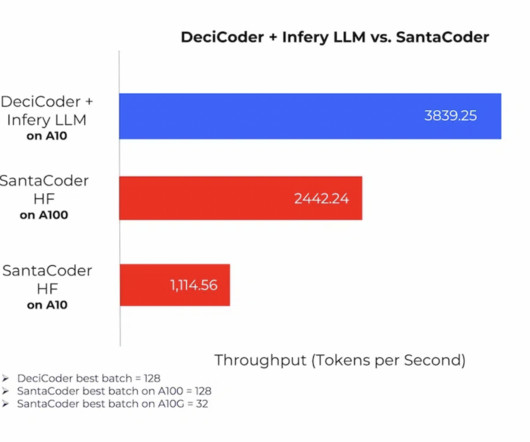
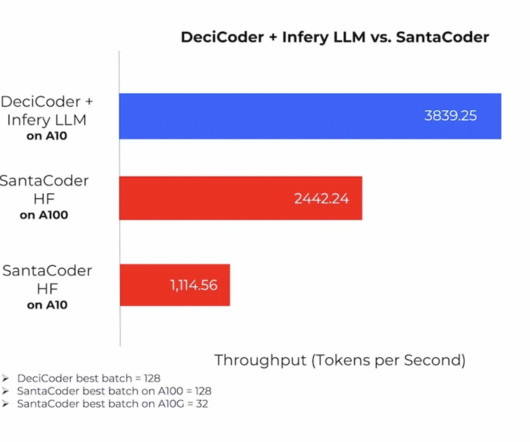
By leveraging DeciCoder alongside Infery LLM, a dedicated inferenceengine, users unlock the power of significantly higher throughput – a staggering 3.5 link] DeciCoder is not an isolated endeavor; it’s part of Deci’s holistic approach to AI efficiency. The implications of this development are profound.
While PC gamers understand frames per second (FPS) and similar stats, measuring AI performance requires new metrics. Trillions is the important word here — the processing numbers behind generativeAI tasks are absolutely massive. Think of TOPS as a raw performance metric, similar to an engine’s horsepower rating.
The generativeAI market has expanded exponentially, yet many existing models still face limitations in adaptability, quality, and computational demands. is a significant step toward democratizing generativeAI by making sophisticated tools available to users regardless of their technical expertise or hardware capabilities.
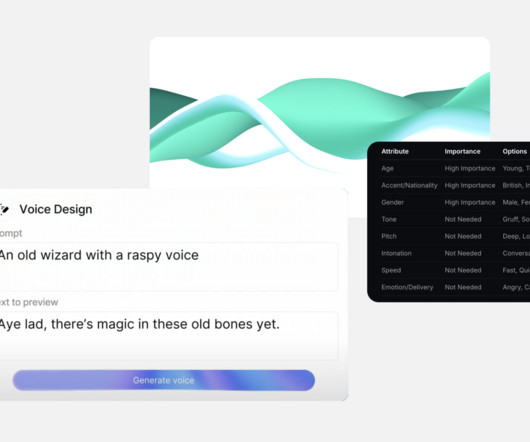
There was not much innovation going on in the generativeAI voices platforms—but that was until ElevenLabs stepped in with Voice Design. ElevenLabs’ Voice Design lets anyone generate a custom AI voice based on a simple single-text prompt. You can find your custom AI-generated voice in the personal section in Voices.
GenerativeAI models have become highly prominent in recent years for their ability to generate new content based on existing data, such as text, images, audio, or video. A specific sub-type, diffusion models, produces high-quality outputs by transforming noisy data into a structured format.
By leveraging DeciCoder alongside Infery LLM, a dedicated inferenceengine, users unlock the power of significantly higher throughput – a staggering 3.5 link] DeciCoder is not an isolated endeavor; it’s part of Deci’s holistic approach to AI efficiency. The implications of this development are profound.
AI-generated content is advancing rapidly, creating both opportunities and challenges. As generativeAI tools become mainstream, the blending of human and AI-generated text raises concerns about authenticity, authorship, and misinformation. If you like our work, you will love our newsletter.
Future work could explore expanding the model’s capacity to handle even larger resolutions efficiently and further refine the distillation techniques to push the boundaries of what is possible in real-time generativeAI. Check out the Paper and Model Card. All credit for this research goes to the researchers of this project.
India is becoming a key producer of AI for virtually every industry — powered by thousands of startups that are serving the country’s multilingual, multicultural population and scaling out to global users. The company runs its custom AI models on NVIDIA Tensor Core GPUs for inference.
Code generationAI models (Code GenAI) are becoming pivotal in developing automated software demonstrating capabilities in writing, debugging, and reasoning about code. However, their ability to autonomously generate code raises concerns about security vulnerabilities. If you like our work, you will love our newsletter.
With AI technologies bound to continue their growth, Agentic IR may well shape how information is retrieved in the future and hence show its potential as a key enabler for next-generationAI-driven applications. Check out the Paper. All credit for this research goes to the researchers of this project.
Researchers from Google offer a set of modifications to the implementation of large diffusion models that allow for the fastest inference latency on mobile devices with GPUs to date. These updates improve the overall user experience across various devices and increase the scope of usage for generativeAI.
Lin Qiao, was formerly head of Meta's PyTorch and is the Co-Founder and CEO of Fireworks AI. Fireworks AI is a production AI platform that is built for developers, Fireworks partners with the world's leading generativeAI researchers to serve the best models, at the fastest speeds.
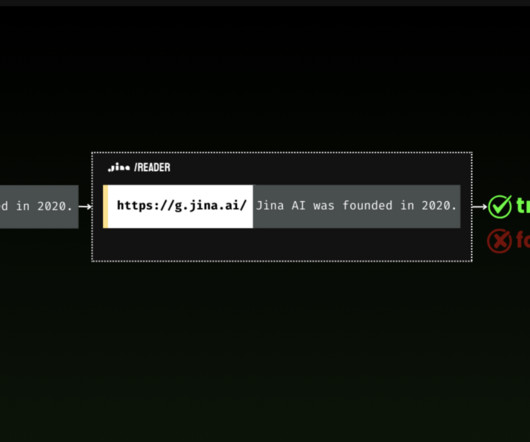
Jina AI announced the release of their latest product, g.jina.ai , designed to tackle the growing problem of misinformation and hallucination in generativeAI models. This innovative tool is part of their larger suite of applications to improve factual accuracy and grounding in AI-generated and human-written content.
In the first part of this blog, we are going to explore how Modular came into existence, who are it’s founding members, and what they have to offer to the AI community. This highly complex and fragmented ecosystem is hampering the AI innovation, and is pulling back the AI community, as a whole.
In today’s rapidly evolving generativeAI world, keeping pace requires more than embracing cutting-edge technology. Our latest achievement combines Advanced Retrieval-Augmented Generation (RAG) with Small Language Models (SLMs), aiming to enhance the capabilities of embedded devices beyond traditional cloud solutions.
Bench IQ, a Toronto-based startup, has unveiled an AI platform that promises to change how lawyers prepare for court. Source ) According to a report, Apple is hoping to push forward its efforts in generativeAI in a bid to catch up with competitor Microsoft. The Open-Sora Plan project ‘s aim is to reproduce OpenAI’s Sora.
With advancements in hardware design, a wide range of CPU- and GPU-based infrastructures are available to help you speed up inference performance. He is currently focused on GenerativeAI, LLMs, prompt engineering, large model inference optimization and scaling ML across enterprises. Vikram Elango is an Sr.
GenerativeAI is rapidly transforming industries, driving demand for secure, high-performance inference solutions to scale increasingly complex models efficiently and cost-effectively.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content