This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
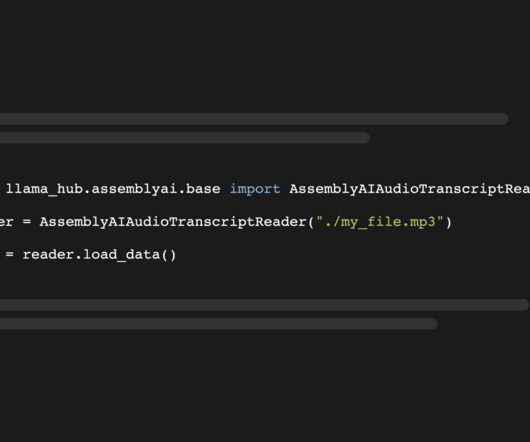
venv/bin/activate # Windows: python -m venv venv.venvScriptsactivate.bat Install LlamaIndex, Llama Hub, and the AssemblyAI Python package : pip install llama-index llama-hub assemblyai Set your AssemblyAI API key as an environment variable named ASSEMBLYAI_API_KEY. You can read more about the integration in the official Llama Hub docs.
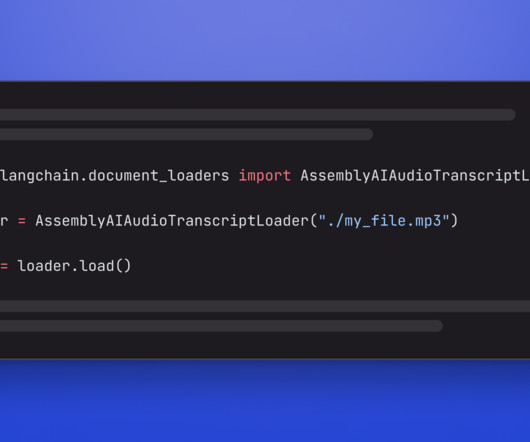
venv/bin/activate # Windows: python -m venv venv.venvScriptsactivate.bat Install LangChain and the AssemblyAI Python package : pip install langchain pip install assemblyai Set your AssemblyAI API key as an environment variable named ASSEMBLYAI_API_KEY. page_content) # Runner's knee. Runner's knee is a condition.
However, information about one dataset can be in another dataset, called metadata. Without using metadata, your retrieval process can cause the retrieval of unrelated results, thereby decreasing FM accuracy and increasing cost in the FM prompt token. This change allows you to use metadata fields during the retrieval process.
The Taxonomy of Traceable Artifacts The paper introduces a systematic taxonomy of artifacts that underpin AgentOps observability: Agent Creation Artifacts: Metadata about roles, goals, and constraints. These metrics are visualized across dimensions such as user sessions, prompts, and workflows, enabling real-time interventions.
Database metadata can be expressed in various formats, including schema.org and DCAT. ML data has unique requirements, like combining and extracting data from structured and unstructured sources, having metadata allowing for responsible data use, or describing ML usage characteristics like training, test, and validation sets.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services. versions, catering to different programming preferences.
We add the following to the end of the prompt: provide the response in json format with the key as “class” and the value as the class of the document We get the following response: { "class": "ID" } You can now read the JSON response using a library of your choice, such as the Python JSON library. The following image is of a gearbox.
Gradio is an open-source Python library that enables developers to create user-friendly and interactive web applications effortlessly. curl ) and using the Python client ( ollama package). Example Python Request Heres how you can use the Python client to interact with the Llama 3.2 and the Ollama API, just keep reading.
The embeddings, along with metadata about the source documents, are indexed for quick retrieval. Python 3.9 Technical Info: Provide part specifications, features, and explain component functions. The embeddings are stored in the Amazon OpenSearch Service owner manuals index. or later Node.js Assist with partial information.
How to save a trained model in Python? Note: The focus of this article is not to show you how you can create the best ML model but to explain how effectively you can save trained models. Saving trained model with pickle The pickle module can be used to serialize and deserialize the Python objects.
This request contains the user’s message and relevant metadata. In the following sections, we explain how to deploy this architecture. Install the Python package dependencies that are needed to build and deploy the project. This project is set up like a standard Python project.
Featured Community post from the Discord Arwmoffat just released Manifest, a tool that lets you write a Python function and have an LLM execute it. Manifest relies on runtime metadata, such as a function’s name, docstring, arguments, and type hints. It uses this metadata to compose a prompt and sends it to an LLM.
For instance, analyzing large tables might require prompting the LLM to generate Python or SQL and running it, rather than passing the tabular data to the LLM. In your code, the final variable should be named "result". """ We can then parse the code out from the tags in the LLM response and run it using exec in Python.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Third, despite the larger adoption of centralized analytics solutions like data lakes and warehouses, complexity rises with different table names and other metadata that is required to create the SQL for the desired sources.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., This includes features for model explainability, fairness assessment, privacy preservation, and compliance tracking. and Pandas or Apache Spark DataFrames. Can you render audio/video?
The search precision can also be improved with metadata filtering. To overcome these limitations, we propose a solution that combines RAG with metadata and entity extraction, SQL querying, and LLM agents, as described in the following sections. But how can we implement and integrate this approach to an LLM-based conversational AI?
🚀 Functional Paradigm: Python functions are the building blocks of data pipelines. ✨ Pure Python: Lightweight, with zero sub-dependencies. structured-logprobs is an open-source Python library that enhances OpenAI's structured outputs by providing detailed information about token log probabilities. Hassle free.
There was no mechanism to pass and store the metadata of the multiple experiments done on the model. We could re-use the previous Sagemaker Python SDK code to run the modules individually into Sagemaker Pipeline SDK based runs. We provided metadata to uniquely distinguish the model from each other. cpu-py39-ubuntu20.04-sagemaker',
We explore how to extract characteristics, also called features , from time series data using the TSFresh library —a Python package for computing a large number of time series characteristics—and perform clustering using the K-Means algorithm implemented in the scikit-learn library. to avoid overfitting.
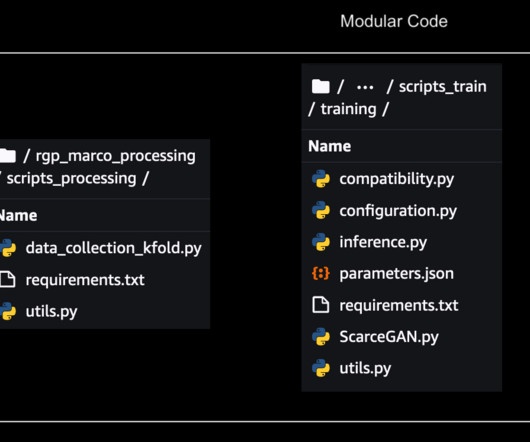
They can include model parameters, configuration files, pre-processing components, as well as metadata, such as version details, authorship, and any notes related to its performance. Additionally, you can list the required Python packages in a requirements.txt file. This is also where we can incorporate custom parameters as needed.
TL;DR Structuring Python projects is very important for proper internal working, as well as for distribution to other users in the form of packages. There are two main general structures: the flat layout vs the src layout as clearly explained in the official Python packaging guide here. Package your project source code folder.
Data and AI governance Publish your data products to the catalog with glossaries and metadata forms. With SageMaker Unified Studio notebooks, you can use Python or Spark to interactively explore and visualize data, prepare data for analytics and ML, and train ML models. Choose the plus sign and for Notebook , choose Python 3.
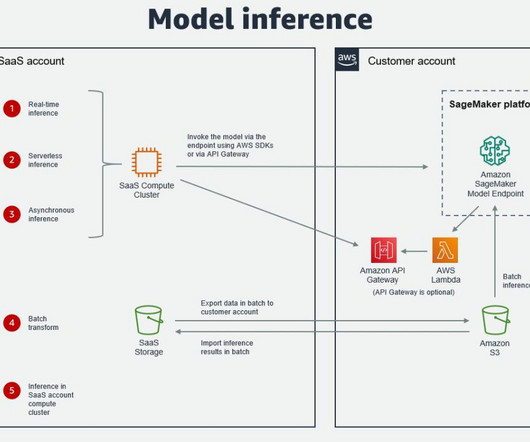
Most of the options explained are also applicable if SageMaker is running in the SaaS AWS account. The open-source Custom Connector SDK enables the development of a private, shared, or public connector using Python or Java. Creating such metadata can help SaaS providers manage the end-to-end lifecycle of the ML model more effectively.
Prerequisite libraries: SageMaker Python SDK, Pinecone Client Solution Walkthrough Using SageMaker Studio notebook, we first need install prerequisite libraries: !pip Since we top_k = 1 , index.query returned the top result along side the metadata which reads Managed Spot Training can be used with all instances supported in Amazon.
Solution overview Starting today, with SageMaker JumpStart and its private hub feature, administrators can create repositories for a subset of models tailored to different teams, use cases, or license requirements using the Amazon SageMaker Python SDK. For a list of filters you can apply, refer to SageMaker Python SDK.
Each dataset group can have up to three datasets, one of each dataset type: target time series (TTS), related time series (RTS), and item metadata. You can implement this workflow in Forecast either from the AWS Management Console , the AWS Command Line Interface (AWS CLI), via API calls using Python notebooks , or via automation solutions.
Hey guys in this video we will see the best Python Interview Questions. Python has become one of the most popular programming languages in the world, thanks to its simplicity, versatility, and vast array of applications. As a result, Python proficiency has become a valuable skill sought after by employers across various industries.
This article explains linear regression in the context of spatial analysis and shows a practical example of its use in GIS. They can categorize nodes and relationships into types with associated metadata, treat your graph as a superset of a vector database for hybrid search, and express complex queries using the Cypher graph query language.
In the first segment of this tutorial, we will address the essential Python packages necessary for building our people counter on OAK. As we approach the culmination of this tutorial, we will define the primary Python driver script that integrates all the utilities and logic that have been developed. mp4 │ └── example_02.mp4
It can also be done at scale, as explained in Operationalize LLM Evaluation at Scale using Amazon SageMaker Clarify and MLOps services. You can create workflows with SageMaker Pipelines that enable you to prepare data, fine-tune models, and evaluate model performance with simple Python code for each step.
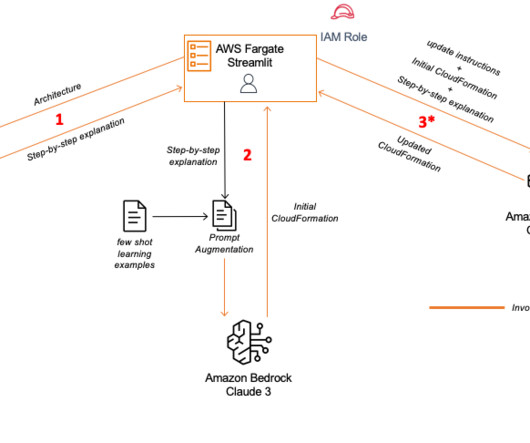
The generated response is divided into three parts: The context explains what the architecture diagram depicts. Second, we want to add metadata to the CloudFormation template. Let’s analyze the step-by-step explanation. We get a summary of the entire generated response. We also want to add additional functionality to the template.
link] Proposes an explainability method for language modelling that explains why one word was predicted instead of a specific other word. Adapts three different explainability methods to this contrastive approach and evaluates on a dataset of minimally different sentences. UC Berkeley, CMU. EMNLP 2022. Imperial, Cambridge, KCL.
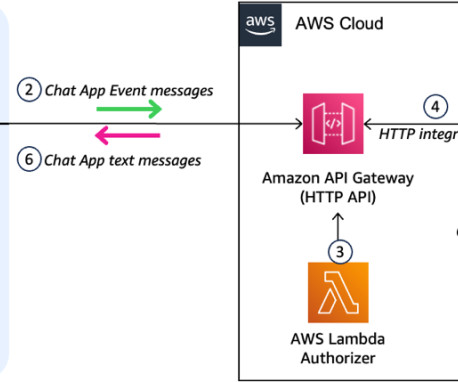
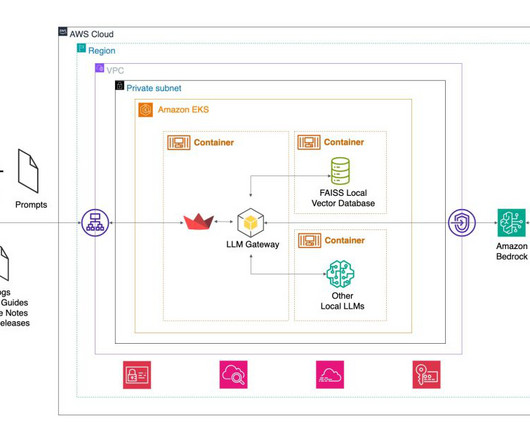
Solution overview The following diagram is a high-level reference architecture that explains how you can further enhance an IDP workflow with foundation models. Refer to our GitHub repository for detailed Python notebooks and a step-by-step walkthrough. The code blocks provided here have been trimmed down for brevity.
In the LLM gateway, prompts are processed in Python using LangChain and Amazon Bedrock. VerbaGPT uses FAISS because it is fast and straightforward to use from Python and LangChain. To create.", "metadata": { "source": "service-accounts.md" }}, ] WorkingDraft: "" User: Create a how-to guide for creating a service account.
Explainability Provides explanations for its predictions through generated text, offering insights into its decision-making process. Although no advanced technical knowledge is required, familiarity with Python and AWS Cloud services will be beneficial if you want to explore our sample code on GitHub.
You can use a managed service, such as Amazon Rekognition , to predict product attributes as explained in Automating product description generation with Amazon Bedrock. First, launch the notebook main.ipynb in SageMaker Studio by selecting the Image as Data Science and Kernel as Python 3.
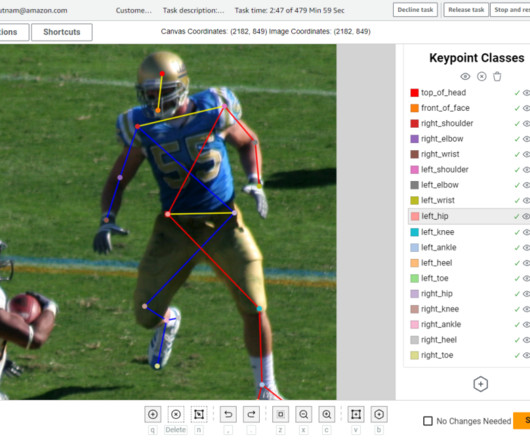
This architecture is comprised of several key components, each of which we explain in more detail in the following sections. This input manifest file contains metadata for a labeling job, acts as a reference to the data that needs to be labeled, and helps configure how the data should be presented to the annotators. for more details).
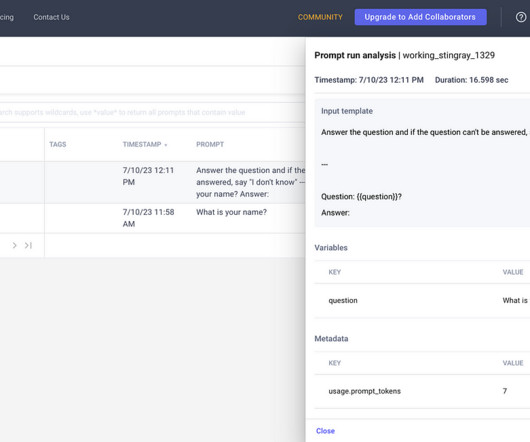
Comet provides tooling to track, explain, manage, and monitor our models in a single place. Using the LLM SDK to Log Prompts and Responses The LLM SDK supports logging prompts with its associated response and any associated metadata like token usage. link] All the information, such as the prompt, response, metadata, duration, etc.,
Building a tool for managing experiments can help your data scientists; 1 Keep track of experiments across different projects, 2 Save experiment-related metadata, 3 Reproduce and compare results over time, 4 Share results with teammates, 5 Or push experiment outputs to downstream systems.
An annotator takes an input text document and produces an output document with additional metadata, which can be used for further processing or analysis. Setup To install Spark NLP in Python, simply use your favorite package manager (conda, pip, etc.). Also the relationship with his wife is weird. Is she bad, or just weak?"
It registers the trained model if it qualifies as a successful model candidate and stores the training artifacts and associated metadata. The solution allows for the familiar use of programming languages like Python and R, development tools such as Jupyter Notebook, and ML frameworks through a configuration file.
We use OpenCV for reading, writing, and manipulating image data in Python. For more information regarding NFL Player Health and Safety, visit the NFL website and NFL Explained: Innovation in Player Health & Safety. Open fuse_and_visualize_multiview_impacts.ipynb and follow the instructions in the notebook.
This post explains how Provectus and Earth.com were able to enhance the AI-powered image recognition capabilities of EarthSnap, reduce engineering heavy lifting, and minimize administrative costs by implementing end-to-end ML pipelines, delivered as part of a managed MLOps platform and managed AI services.
In this post, we use a Hugging Face BERT-Large model pre-training workload as a simple example to explain how to useTrn1 UltraClusters. The shell script invokes the Python script via the neuron_parallel_compile API to compile the model into graphs without a full training run. We submit the training job with the sbatch command.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content