This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
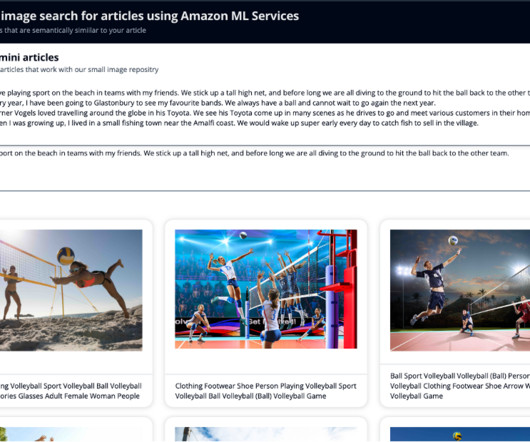
When building machinelearning (ML) models using preexisting datasets, experts in the field must first familiarize themselves with the data, decipher its structure, and determine which subset to use as features. This obstacle lowers productivity through machinelearning development—from data discovery to model training.
This enables the efficient processing of content, including scientific formulas and data visualizations, and the population of Amazon Bedrock Knowledge Bases with appropriate metadata. JupyterLab applications flexible and extensive interface can be used to configure and arrange machinelearning (ML) workflows.
Can you discuss the advantages of deep learning over traditional machinelearning in threat prevention? However, while many cyber vendors claim to bring AI to the fight, machinelearning (ML) – a less sophisticated form of AI – remains a core part of their products. Not all AI is equal.
However, information about one dataset can be in another dataset, called metadata. Without using metadata, your retrieval process can cause the retrieval of unrelated results, thereby decreasing FM accuracy and increasing cost in the FM prompt token. This change allows you to use metadata fields during the retrieval process.
I have written short summaries of 68 different research papers published in the areas of MachineLearning and Natural Language Processing. link] Proposes an explainability method for language modelling that explains why one word was predicted instead of a specific other word. UC Berkeley, CMU. EMNLP 2022.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services. versions, catering to different programming preferences.
This article will focus on LLM capabilities to extract meaningful metadata from product reviews, specifically using OpenAI API. Data processing Since our main area of interest is extracting metadata from reviews, we had to choose a subset of reviews and label it manually with selected fields of interest.
The graph, stored in Amazon Neptune Analytics, provides enriched context during the retrieval phase to deliver more comprehensive, relevant, and explainable responses tailored to customer needs. You can also supply a custom metadata file (each up to 10 KB) for each document in the knowledge base.
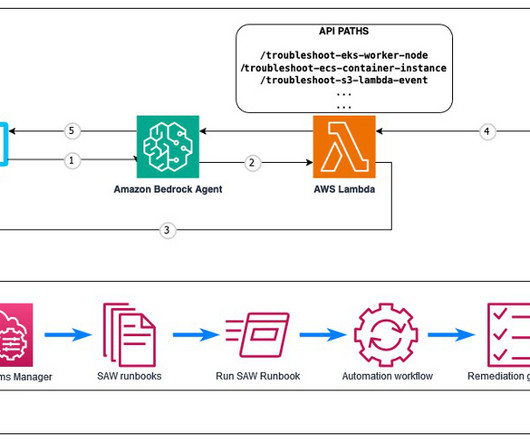
In the following sections, we explain how AI Workforce enables asset owners, maintenance teams, and operations managers in industries such as energy and telecommunications to enhance safety, reduce costs, and improve efficiency in infrastructure inspections. In this post, we introduce the concept and key benefits.
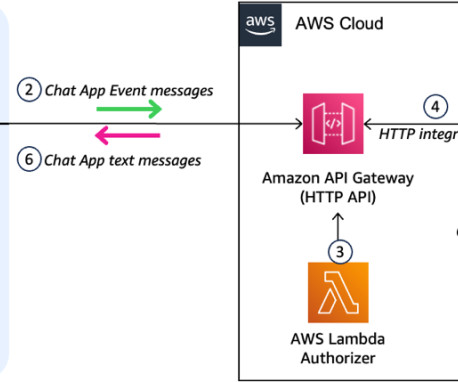
We use the following prompt to read this diagram: The steps in this diagram are explained using numbers 1 to 11. Can you explain the diagram using the numbers 1 to 11 and an explanation of what happens at each of those steps? Architects could also use this mechanism to explain the floor plan to customers.
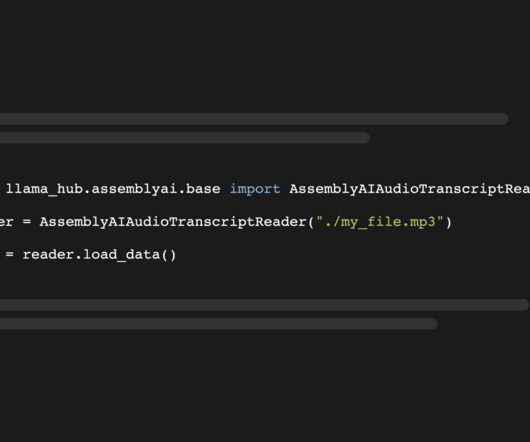
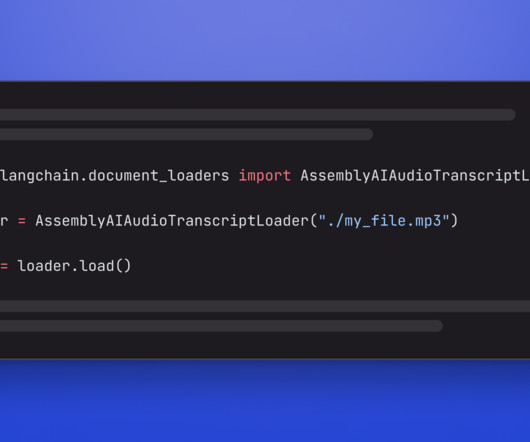
The metadata contains the full JSON response of our API with more meta information: print(docs[0].metadata) The metadata needs to be smaller than the text chunk size, and since it contains the full JSON response with extra information, it is quite large. You can read more about the integration in the official Llama Hub docs.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. An AI governance framework ensures the ethical, responsible and transparent use of AI and machinelearning (ML). ” Are foundation models trustworthy? . ” Are foundation models trustworthy?
After some impressive advances over the past decade, largely thanks to the techniques of MachineLearning (ML) and Deep Learning , the technology seems to have taken a sudden leap forward. 1] Users can access data through a single point of entry, with a shared metadata layer across clouds and on-premises environments.
They’re built on machinelearning algorithms that create outputs based on an organization’s data or other third-party big data sources. Among the tasks necessary for internal and external compliance is the ability to report on the metadata of an AI model.
Artificial intelligence (AI) and machinelearning (ML) are becoming an integral part of systems and processes, enabling decisions in real time, thereby driving top and bottom-line improvements across organizations. Machinelearning operations (MLOps) applies DevOps principles to ML systems.
However, with the help of AI and machinelearning (ML), new software tools are now available to unearth the value of unstructured data. But in the case of unstructured data, metadata discovery is challenging because the raw data isn’t easily readable. You can integrate different technologies or tools to build a solution.
Possibilities are growing that include assisting in writing articles, essays or emails; accessing summarized research; generating and brainstorming ideas; dynamic search with personalized recommendations for retail and travel; and explaining complicated topics for education and training. What is generative AI? What is watsonx.governance?
Getting ready for upcoming regulations with IBM IBM watsonx.governance accelerates responsible, transparent and explainable AI workflows IBM® watsonx.governance™ accelerates AI governance, the directing, managing and monitoring of your organization’s AI activities.
After developing a machinelearning model, you need a place to run your model and serve predictions. Someone with the knowledge of SQL and access to a Db2 instance, where the in-database ML feature is enabled, can easily learn to build and use a machinelearning model in the database. and Lawrence, N.D.,
That is, it should support both sound data governance —such as allowing access only by authorized processes and stakeholders—and provide oversight into the use and trustworthiness of AI through transparency and explainability.
The metadata contains the full JSON response of our API with more meta information: print(docs[0].metadata) "), ] result = transcript.lemur.question(questions) Conclusion This tutorial explained how to use the AssemblyAI integration that was added to the LangChain Python framework in version 0.0.272.
Innovations in artificial intelligence (AI) and machinelearning (ML) are causing organizations to take a fresh look at the possibilities these technologies can offer. For example, the AI/ML governance team trusts the development teams are sending the correct bias and explainability reports for a given model.
Bringing together traditional machinelearning and generative AI with a family of enterprise-grade, IBM-trained foundation models, watsonx allows the USTA to deliver fan-pleasing, AI-driven features much more quickly. This year, the USTA is using watsonx , IBM’s new AI and data platform for business.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machinelearning (ML) models across your AWS accounts. Mitigation strategies : Implementing measures to minimize or eliminate risks.
This article lists the top AI courses by Google that provide comprehensive training on various AI and machinelearning technologies, equipping learners with the skills needed to excel in the rapidly evolving field of AI. Participants learn how to improve model accuracy and write scalable, specialized ML models.
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. This includes features for model explainability, fairness assessment, privacy preservation, and compliance tracking.
In what ways do we understand image annotations, the underlying technology behind AI and machinelearning (ML), and its importance in developing accurate and adequate AI training data for machinelearning models? Overall, it shows the more data you have, the better your AI and machinelearning models are.
This approach allows for greater flexibility and integration with existing AI and machinelearning (AI/ML) workflows and pipelines. Be thorough in your search as the file may be nested within a markdown code block or within a directory listing. """ }, { "role": "user", "content": f"Can you explain to me the buildspec-1-10-2.yml
I’ll explain the steps to configure Amazon S3 bucket to store the artifacts, Amazon RDS (Postgres & Mysql) to store metadata, and EC2 instance to host the mlflow server. Get ready to supercharge your machine-learning projects and unlock new levels of productivity. Let me explain it separately. So let’s begin!
This request contains the user’s message and relevant metadata. In the following sections, we explain how to deploy this architecture. He enjoys supporting customers in their digital transformation journey, using big data, machinelearning, and generative AI to help solve their business challenges.
This post explores how Amazon SageMaker AI with MLflow can help you as a developer and a machinelearning (ML) practitioner efficiently experiment, evaluate generative AI agent performance, and optimize their applications for production readiness. This combination is particularly powerful for working with generative AI agents.
For use cases where accuracy is critical, customers need the use of mathematically sound techniques and explainable reasoning to help generate accurate FM responses. This includes watermarking, content moderation, and C2PA support (available in Amazon Nova Canvas) to add metadata by default to generated images.
It uses metadata and data management tools to organize all data assets within your organization. She can search structured or unstructured data, visualizations and dashboards, machinelearning models, and database connections. Technical metadata to describe schemas, indexes and other database objects.
Amazon Rekognition makes it easy to add image analysis capability to your applications without any machinelearning (ML) expertise and comes with various APIs to fulfil use cases such as object detection, content moderation, face detection and analysis, and text and celebrity recognition, which we use in this example.
The Annotated type is used to provide additional metadata about the return value, specifically that it should be included in the response body. About the Authors Wael Dimassi is a Technical Account Manager at AWS, building on his 7-year background as a MachineLearning specialist. The automation workflow will run all the checks.
A significant challenge in AI applications today is explainability. How does the knowledge graph architecture of the AI Context Engine enhance the accuracy and explainability of LLMs compared to SQL databases alone? Our team, experts in both symbolic AI and machinelearning, drives this commitment.
Whether youre new to Gradio or looking to expand your machinelearning (ML) toolkit, this guide will equip you to create versatile and impactful applications. Using the Ollama API (this tutorial) To learn how to build a multimodal chatbot with Gradio, Llama 3.2, and the Ollama API, just keep reading. ollama/models directory.
In the past decade, Artificial Intelligence (AI) and MachineLearning (ML) have seen tremendous progress. The Need for Self-Supervised Learning in Computer Vision Data annotation or data labeling is a pre-processing stage in the development of machinelearning & artificial intelligence models.
The embeddings, along with metadata about the source documents, are indexed for quick retrieval. Technical Info: Provide part specifications, features, and explain component functions. The embeddings are stored in the Amazon OpenSearch Service owner manuals index. Assist with partial information.
In machinelearning, experiment tracking stores all experiment metadata in a single location (database or a repository). Tracking machinelearning experiments has always been a crucial step in ML development, but it used to be a labor-intensive, slow, and error-prone procedure. are all included in this.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Third, despite the larger adoption of centralized analytics solutions like data lakes and warehouses, complexity rises with different table names and other metadata that is required to create the SQL for the desired sources.
The Next Generation of Low-Code MachineLearning Devvret Rishi | Co-founder and Chief Product Officer | Predibase In this session, you’ll explore declarative machinelearning, a configuration-based modeling interface, which provides more flexibility and simplicity when implementing cutting-edge machinelearning.
The search precision can also be improved with metadata filtering. To overcome these limitations, we propose a solution that combines RAG with metadata and entity extraction, SQL querying, and LLM agents, as described in the following sections. But how can we implement and integrate this approach to an LLM-based conversational AI?
The randomization process was adequately explained to patients, and they understood the rationale behind blinding, which is to prevent bias in the results (Transcript 2). You will notice the content of this file as JSON with a text transcript available under the key transcripts, along with other metadata.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content