
Cost-effective document classification using the Amazon Titan Multimodal Embeddings Model
AWS Machine Learning Blog
APRIL 11, 2024
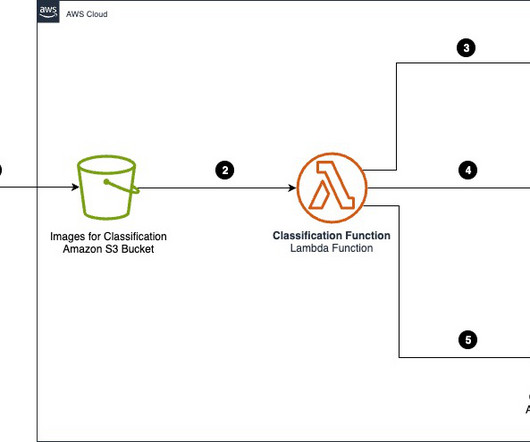
Advances in generative artificial intelligence (AI) have given rise to intelligent document processing (IDP) solutions that can automate the document classification, and create a cost-effective classification layer capable of handling diverse, unstructured enterprise documents. Categorizing documents is an important first step in IDP systems.









Let's personalize your content