This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
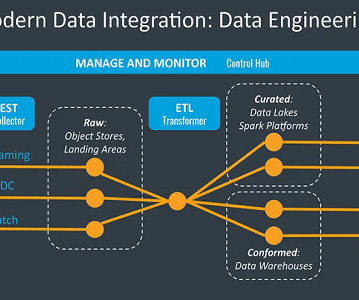
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
AI engineering extended this by integrating AI systems more deeply into softwareengineering pipelines, making it a crucial field as AI applications became more sophisticated and embedded in real-world systems. Takeaway: The industrys focus has shifted from building models to making them robust, scalable, and maintainable.
Data Scientists and ML Engineers typically write lots and lots of code. From writing code for doing exploratory analysis, experimentation code for modeling, ETLs for creating training datasets, Airflow (or similar) code to generate DAGs, REST APIs, streaming jobs, monitoring jobs, etc. Related post MLOps Is an Extension of DevOps.
The rapid evolution of AI is transforming nearly every industry/domain, and softwareengineering is no exception. But how so with softwareengineering you may ask? These technologies are helping engineers accelerate development, improve software quality, and streamline processes, just to name a few.
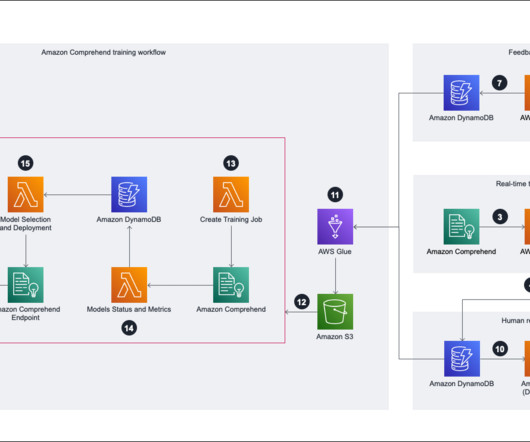
The embeddings are captured in Amazon Simple Storage Service (Amazon S3) via Amazon Kinesis Data Firehose , and we run a combination of AWS Glue extract, transform, and load (ETL) jobs and Jupyter notebooks to perform the embedding analysis. Set the parameters for the ETL job as follows and run the job: Set --job_type to BASELINE.
In this solution, we leverage the reasoning and coding abilities of LLMs for creating reusable Extract, Transform, Load (ETL), which transforms sensor data files that do not conform to a universal standard to be stored together for downstream calibration and analysis.
It covers advanced topics, including scikit-learn for machine learning, statistical modeling, softwareengineering practices, and data engineering with ETL and NLP pipelines. The program culminates in a capstone project where learners apply their skills to solve a real-world data science challenge.
Data Warehouses Some key characteristics of data warehouses are as follows: Data Type: Data warehouses primarily store structured data that has undergone ETL (Extract, Transform, Load) processing to conform to a specific schema. Schema Enforcement: Data warehouses use a “schema-on-write” approach.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. ETL Tools: Apache NiFi, Talend, etc. Read more to know.
Data engineers will also work with data scientists to design and implement data pipelines; ensuring steady flows and minimal issues for data teams. They’ll also work with softwareengineers to ensure that the data infrastructure is scalable and reliable.
About the authors Samantha Stuart is a Data Scientist with AWS Professional Services, and has delivered for customers across generative AI, MLOps, and ETL engagements. He has touched on most aspects of these projects, from infrastructure and DevOps to software development and AI/ML.
Learning about the framework of a service cloud platform is time consuming and frustrating because there is a lot of new information from many different computing fields (computer science/database, softwareengineering/developers, data science/scientific engineering & computing/research).
The following steps show you how to train the model: We use AWS Glue to conduct extract, transform, and load (ETL) jobs and merge the data from two different DynamoDB tables and store it in Amazon Simple Storage Service (Amazon S3). Before joining AWS, she was a softwareengineer. Shanna Chang is a Solutions Architect at AWS.
The following blog will help you know about the Azure Data Engineering Job Description, salary, and certification course. Data Engineering is one of the most productive job roles today because it imbibes both the skills required for softwareengineering and programming and advanced analytics needed by Data Scientists.
Stefan is a softwareengineer, data scientist, and has been doing work as an ML engineer. At a high level, we are trying to make machine learning initiatives more human capital efficient by enabling teams to more easily get to production and maintain their model pipelines, ETLs, or workflows.
Data version control in machine learning vs conventional softwareengineering Data version control in machine learning and conventional softwareengineering have some similarities, but there are also some key differences to consider. This is where data versioning comes in.
About the Authors Christopher Diaz is a Lead R&D Engineer at CCC Intelligent Solutions. Emmy Award winner Sam Kinard is a Senior Manager of SoftwareEngineering at CCC Intelligent Solutions. In his spare time, he enjoys trying new restaurants in his hometown of Chicago and collecting as many LEGO sets as his home can fit.
You can use these connections for both source and target data, and even reuse the same connection across multiple crawlers or extract, transform, and load (ETL) jobs. Varun Shah is a SoftwareEngineer working on Amazon SageMaker Studio at Amazon Web Services. In his free time, he enjoys playing chess and traveling.
Let’s combine these suggestions to improve upon our original prompt: Human: Your job is to act as an expert on ETL pipelines. Specifically, your job is to create a JSON representation of an ETL pipeline which will solve the user request provided to you.
My journey in the database field spans over 15 years, including six years as a softwareengineer at Oracle, where I was a founding member of the Oracle 12c Multitenant Database team. Can you share the story behind founding Zilliz and what inspired you to develop Milvus and focus on vector databases?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content