This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
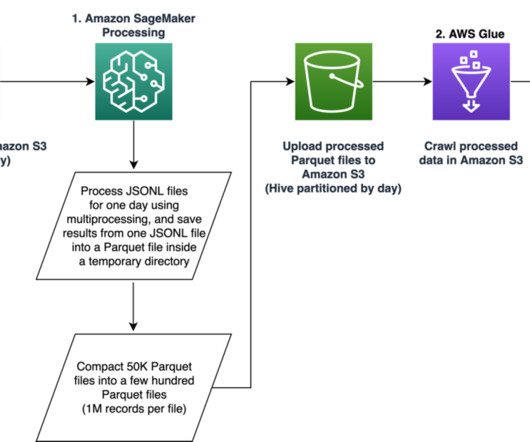
Our pipeline belongs to the general ETL (extract, transform, and load) process family that combines data from multiple sources into a large, central repository. The solution does not require porting the feature extraction code to use PySpark, as required when using AWS Glue as the ETL solution. session.Session().region_name
Advances in NLP showed how unstructured data could be transformed into vector embeddings, unlocking its semantic meaning. During this time, I noticed a key limitation: while structured data was well-managed, unstructured datarepresenting 90% of all dataremained largely untapped, with only 1% analyzed meaningfully.
An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark. Creating ETL pipelines to transform log data Preparing your data to provide quality results is the first step in an AI project.
This article lists the top data engineering courses that provide comprehensive training in building scalable data solutions, mastering ETL processes, and leveraging advanced technologies like Apache Spark and cloud platforms to meet modern data challenges effectively.
The Boom of Generative AI and Large Language Models(LLMs) 20182020: NLP was gaining traction, with a focus on word embeddings, BERT, and sentiment analysis. The Boom of Generative AI and Large Language Models(LLMs) 20182020: NLP was gaining traction, with a focus on word embeddings, BERT, and sentiment analysis.
Embeddings capture the information content in bodies of text, allowing natural language processing (NLP) models to work with language in a numeric form. Set the parameters for the ETL job as follows and run the job: Set --job_type to BASELINE. The following diagram illustrates the end-to-end architecture.
Unlike traditional natural language processing (NLP) approaches, such as classification methods, LLMs offer greater flexibility in adapting to dynamically changing categories and improved accuracy by using pre-trained knowledge embedded within the model.
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. With multiple families in plan, the first release is the Slate family of models, which represent an encoder-only architecture. To bridge the tuning gap, watsonx.ai
Just like this in Data Science we have Data Analysis , Business Intelligence , Databases , Machine Learning , Deep Learning , Computer Vision , NLP Models , Data Architecture , Cloud & many things, and the combination of these technologies is called Data Science. Data Science and AI are related?
These courses cover foundational topics such as machine learning algorithms, deep learning architectures, natural language processing (NLP), computer vision, reinforcement learning, and AI ethics. Udacity offers comprehensive courses on AI designed to equip learners with essential skills in artificial intelligence.
These are used to extract, transform, and load (ETL) data between different systems. Data integration tools allow for the combining of data from multiple sources. The most popular of these tools are Talend, Informatica, and Apache NiFi.
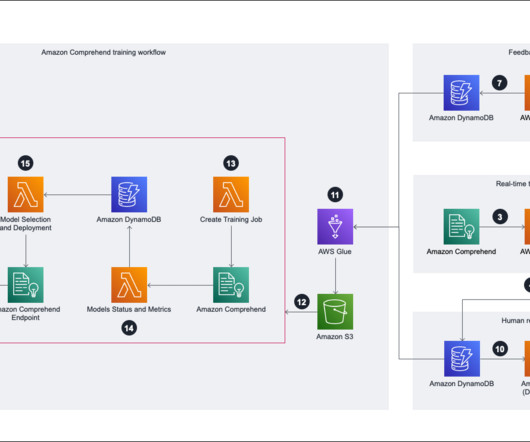
Amazon Comprehend is a fully managed and continuously trained natural language processing (NLP) service that can extract insight about the content of a document or text. However, the discovery of Amazon Comprehend enables us to efficiently and economically bring an NLP model from concept to implementation in a mere 1.5
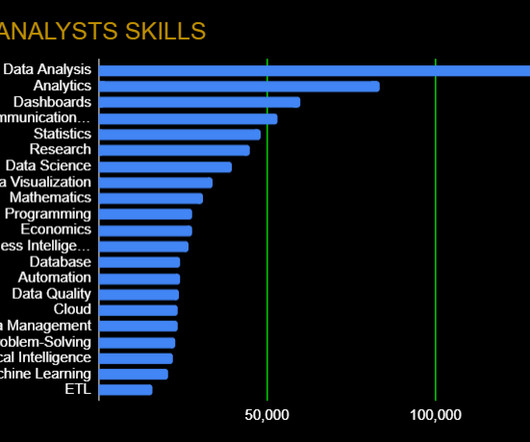
Data Wrangling: Data Quality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis. Competence in data quality, databases, and ETL (Extract, Transform, Load) are essential. By registering now, you’ll also gain access to Ai+ Training on demand for a year.
AWS Glue: Fully managed ETL service for easy data preparation and integration. Amazon Comprehend & Translate: Leverage NLP and translation for LLM (Large Language Models) applications. Data Foundation on AWS Amazon S3: Scalable storage foundation for data lakes. Amazon Redshift: Fast, scalable data warehouse for analytics.
AWS Glue: Fully managed ETL service for easy data preparation and integration. Amazon Comprehend & Translate: Leverage NLP and translation for LLM (Large Language Models) applications. Data Foundation on AWS Amazon S3: Scalable storage foundation for data lakes. Amazon Redshift: Fast, scalable data warehouse for analytics.
TR used AWS Glue DataBrew and AWS Batch jobs to perform the extract, transform, and load (ETL) jobs in the ML pipelines, and SageMaker along with Amazon Personalize to tailor the recommendations. He is passionate about recommendation systems, NLP, and computer vision areas in AI and ML. Applied AI Specialist Architect at AWS.
These teams are as follows: Advanced analytics team (data lake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
Their research paper shows that building NLP systems with DSP can easily outperform GPT-3.5 By taking a data-centric approach to AI MindsDB brings the process closer to the source of the data minimizing the need to build and maintain data pipelines and ETL’ing, speeding up the time to deployment and reducing complexity.
Automated Data Integration and ETL Tools The rise of no-code and low-code tools is transforming data integration and Extract, Transform, and Load (ETL) processes. Augmented Analytics Augmented analytics is redefining dashboards by integrating natural language processing (NLP). and receiving instant, actionable insights.
They build production-ready systems using best-practice containerisation technologies, ETL tools and APIs. Data engineers are the glue that binds the products of data scientists into a coherent and robust data pipeline. They are skilled at deploying to any cloud or on-premises infrastructure.
Furthermore, in addition to common extract, transform, and load (ETL) tasks, ML teams occasionally require more advanced capabilities like creating quick models to evaluate data and produce feature importance scores or post-training model evaluation as part of an MLOps pipeline. In her spare time, she enjoys movies, music, and literature.
You can use these connections for both source and target data, and even reuse the same connection across multiple crawlers or extract, transform, and load (ETL) jobs. These connections are used by AWS Glue crawlers, jobs, and development endpoints to access various types of data stores. In his free time, he enjoys playing chess and traveling.
Power Query Power Query is a powerful ETL (Extract, Transform, Load) tool within Power BI that helps users clean and transform raw data into usable formats. Real-World Example A sales executive uses the mobile app during client meetings to showcase real-time sales figures and projections directly from their smartphone or tablet.
Fast and Scalable XLA Compilation Distributed Computing Performance Optimization Applied ML New tools for CV and NLP Production Grade Solutions Developer Resources Ready To Deploy Easier Exporting C++ API for applications Deploy JAX Models Simplicity NumPy API Easier Debugging OpenAI opens the public access for Dall-E model in this blog post.
It’s optimized with performance features like indexing, and customers have seen ETL workloads execute up to 48x faster. It helps data engineering teams by simplifying ETL development and management. Natural Language Processing (NLP) techniques can be applied to analyze and understand unstructured text data. Morgan Kaufmann.
For examples on using asynchronous inference with unstructured data such as computer vision and natural language processing (NLP), refer to Run computer vision inference on large videos with Amazon SageMaker asynchronous endpoints and Improve high-value research with Hugging Face and Amazon SageMaker asynchronous inference endpoints , respectively.
Faster Time-to-Market The built-in SageMaker algorithms together with auto-tuning capabilities provided by SageMaker Autopilot enable users to choose from pre-written algorithms for standard classification, regression, NLP problem sets or enable automated model selection and tuning functions.
Traditional NLP pipelines and ML classification models Traditional natural language processing pipelines struggle with email complexity due to their reliance on rigid rules and poor handling of language variations, making them impractical for dynamic client communications. However, not all of them were effective for Parameta.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content