This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
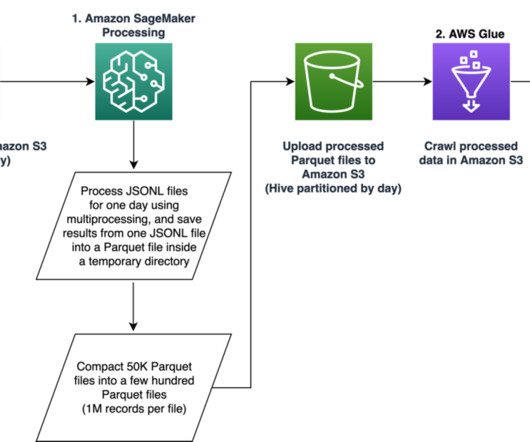
Our pipeline belongs to the general ETL (extract, transform, and load) process family that combines data from multiple sources into a large, central repository. The solution does not require porting the feature extraction code to use PySpark, as required when using AWS Glue as the ETL solution. session.Session().region_name
These teams are as follows: Advanced analytics team (data lake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
During my MS, I got the opportunity to work on many types of data and ML projects, including web scraping to collect data, parsing big data, building unsupervised ML models, building supervised ML models, creating deep neural networks, working with text data using NaturalLanguageProcessing, and with speech data using audio processing techniques.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









Let's personalize your content