This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
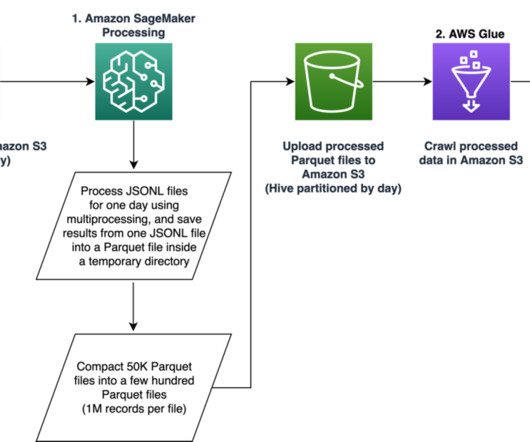
Our pipeline belongs to the general ETL (extract, transform, and load) process family that combines data from multiple sources into a large, central repository. The solution does not require porting the feature extraction code to use PySpark, as required when using AWS Glue as the ETL solution. session.Session().region_name
Often the Data Team, comprising Data and MLEngineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier. What is an ETL data pipeline in ML? Let’s look at the importance of ETL pipelines in detail.
Data refinement: Raw data is refined into consumable layers (raw, processed, conformed, and analytical) using a combination of AWS Glue extract, transform, and load (ETL) jobs and EMR jobs. Deployment times stretched for months and required a team of three system engineers and four MLengineers to keep everything running smoothly.
In addition to the challenge of defining the features for the ML model, it’s critical to automate the feature generation process so that we can get ML features from the raw data for ML inference and model retraining. Because most of the games share similar log types, they want to reuse this ML solution to other games.
To obtain such insights, the incoming raw data goes through an extract, transform, and load (ETL) process to identify activities or engagements from the continuous stream of device location pings. We can analyze activities by identifying stops made by the user or mobile device by clustering pings using ML models in Amazon SageMaker.
This situation is not different in the ML world. Data Scientists and MLEngineers typically write lots and lots of code. Building a mental model for ETL components Learn the art of constructing a mental representation of the components within an ETL process.
Specialist Data Engineering at Merck, and Prabakaran Mathaiyan, Sr. MLEngineer at Tiger Analytics. The large machine learning (ML) model development lifecycle requires a scalable model release process similar to that of software development. This post is co-written with Jayadeep Pabbisetty, Sr.
📢 Event: apply(risk), the MLEngineering Community Conference for Building Risk & Fraud Detection Systems Want to connect with the MLengineering community and learn best practices from ML practitioners at Affirm, Remitly, Block, Tide, and more, on how to build risk and fraud detection systems?
It eliminates tedious, costly, and error-prone ETL (extract, transform, and load) jobs. SageMaker Projects provides a straightforward way to set up and standardize the development environment for data scientists and MLengineers to build and deploy ML models on SageMaker.
.” Hence the very first thing to do is to make sure that the data being used is of high quality and that any errors or anomalies are detected and corrected before proceeding with ETL and data sourcing. If you aren’t aware already, let’s introduce the concept of ETL. We primarily used ETL services offered by AWS.
These teams are as follows: Advanced analytics team (data lake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
With experience of leading AWS AI/ML solutions across industries, Bhajandeep has enabled clients to maximize the value of AWS AI/ML services through his expertise and leadership. Ajay Vishwakarma is an MLengineer for the AWS wing of Wipro’s AI solution practice.
We’ll see how this architecture applies to different classes of ML systems, discuss MLOps and testing aspects, and look at some example implementations. Understanding machine learning pipelines Machine learning (ML) pipelines are a key component of ML systems. But what is an ML pipeline?
You have to make sure that your ETLs are locked down. And usually what ends up happening is that some poor data scientist or MLengineer has to manually troubleshoot this in a Jupyter Notebook. So this path on the right side of the production icon is what we’re calling ML observability.
You have to make sure that your ETLs are locked down. And usually what ends up happening is that some poor data scientist or MLengineer has to manually troubleshoot this in a Jupyter Notebook. So this path on the right side of the production icon is what we’re calling ML observability.
You have to make sure that your ETLs are locked down. And usually what ends up happening is that some poor data scientist or MLengineer has to manually troubleshoot this in a Jupyter Notebook. So this path on the right side of the production icon is what we’re calling ML observability.
While dealing with larger quantities of data, you will likely be working with Data Engineers to create ETL (extract, transform, load) pipelines to get data from new sources. Data Science is an umbrella role with common roles such as Data Analytics, research, ML model building, ML Ops, and MLengineering underneath.
And that’s what we’re going to focus on in this article, which is the second in my series on Software Patterns for Data Science & MLEngineering. While often ignored by data scientists, I believe mastering ETL is core and critical to guarantee the success of any machine learning project.
Regarding other teams, they may approach testing ML models differently, especially in tabular ML use cases, by testing on sub-populations of the data. It’s a healthy situation when data scientists and MLengineers, in particular, are responsible for delivering tests for the functionalities of their projects.
This is Piotr Niedźwiedź and Aurimas Griciūnas from neptune.ai , and you’re listening to ML Platform Podcast. Stefan is a software engineer, data scientist, and has been doing work as an MLengineer. Jeff Magnusson has a pretty famous post about engineers shouldn’t write ETL. Stefan: Yeah.
He helps architect solutions across AI/ML applications, enterprise data platforms, data governance, and unified search in enterprises. Gi Kim is a Data & MLEngineer with the AWS Professional Services team, helping customers build data analytics solutions and AI/ML applications.
Seamless AWS Integration Works effortlessly with AWS S3 (data storage), AWS Lambda (serverless computing), and AWS Glue (ETL). Challenges of Custom ML Initial deployment costs are high because DevOps teams and MLengineers must be hired while infrastructure expenditure is necessary.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content