This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
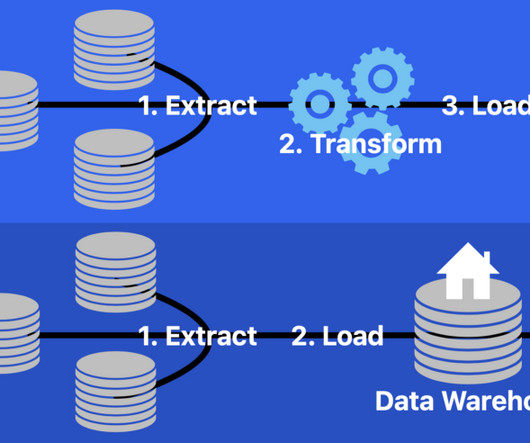
Two of the more popular methods, extract, transform, load (ETL ) and extract, load, transform (ELT) , are both highly performant and scalable. ETL/ELT tools typically have two components: a design time (to design data integration jobs) and a runtime (to execute data integration jobs).
30% Off ODSC East, Fan-Favorite Speakers, Foundation Models for Times Series, and ETL Pipeline Orchestration The ODSC East 2025 Schedule isLIVE! Explore the must-attend sessions and cutting-edge tracks designed to equip AI practitioners, data scientists, and engineers with the latest advancements in AI and machine learning.
Machine learning (ML) has become a critical component of many organizations’ digital transformation strategy. From predicting customer behavior to optimizing business processes, ML algorithms are increasingly being used to make decisions that impact business outcomes.
Learn the basics of data engineering to improve your ML modelsPhoto by Mike Benna on Unsplash It is not news that developing Machine Learning algorithms requires data, often a lot of data. In this article, we will look at some data engineering basics for developing a so-called ETL pipeline.
Our pipeline belongs to the general ETL (extract, transform, and load) process family that combines data from multiple sources into a large, central repository. The solution does not require porting the feature extraction code to use PySpark, as required when using AWS Glue as the ETL solution. session.Session().region_name
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
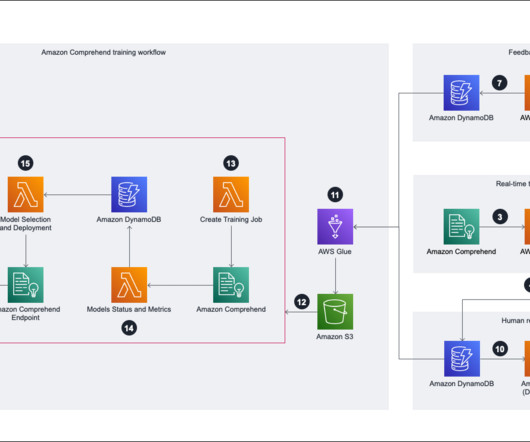
These techniques utilize various machine learning (ML) based approaches. In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience.
Db2 Warehouse fully supports open formats such as Parquet, Avro, ORC and Iceberg table format to share data and extract new insights across teams without duplication or additional extract, transform, load (ETL). This allows you to scale all analytics and AI workloads across the enterprise with trusted data.
” He notes it’s powered by “a compound AI system that continuously learns from usage across an organisation’s entire data stack, including ETL pipelines, lineage, and other queries.”
However, the success of ML projects is heavily dependent on the quality of data used to train models. Introduction Machine learning has become an essential tool for organizations of all sizes to gain insights and make data-driven decisions. Poor data quality can lead to inaccurate predictions and poor model performance.
Summary: This article explores the significance of ETL Data in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. This use case, solvable through ML, can enable support teams to better understand customer needs and optimize response strategies.
This post presents a solution that uses a workflow and AWS AI and machine learning (ML) services to provide actionable insights based on those transcripts. We use multiple AWS AI/ML services, such as Contact Lens for Amazon Connect and Amazon SageMaker , and utilize a combined architecture. Validation set 11 1500 0.82
Apart from the time-sensitive necessity of running a business with perishable, delicate goods, the company has significantly adopted Azure, moving some existing ETL applications to the cloud, while Hershey’s operations are built on a complex SAP environment. So that’s on the vendor side.
AWS Glue: A serverless ETL service that simplifies the monitoring and management of data pipelines. Microsoft SQL Server Integration Services (SSIS): A closed-source platform for building ETL, data integration, and transformation pipeline workflows. Strengths: Fault-tolerant, scalable, and reliable for real-time data processing.
An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark. Creating ETL pipelines to transform log data Preparing your data to provide quality results is the first step in an AI project.
20212024: Interest declined as deep learning and pre-trained models took over, automating many tasks previously handled by classical ML techniques. This shift suggests that while traditional ML is still relevant, its role is now more supportive rather than cutting-edge.
The ETL (Extract, Transform, Load) process is also critical in aggregating and processing data from varied sources. Researchers from Upstage AI have introduced Dataverse, an innovative ETL pipeline crafted to enhance data processing for LLMs. Also, don’t forget to follow us on Twitter.
Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. To address the legacy data science environment challenges, Rocket decided to migrate its ML workloads to the Amazon SageMaker AI suite. Analytic data is stored in Amazon Redshift.
In this article we’re going to check what is an Azure function and how we can employ it to create a basic extract, transform and load (ETL) pipeline with minimal code. Extract, transform and Load Before we begin, let’s shed some light on what an ETL pipeline essentially is. ELT stands for extract, load and transform.
AI and machine learning (ML) models are incredibly effective at doing this but are complex to build and require data science expertise. HT: Today’s marketers need to not only understand past customer behaviour but must be able to anticipate and act on customers’ future wants and needs. With Segment, you choose where you start.
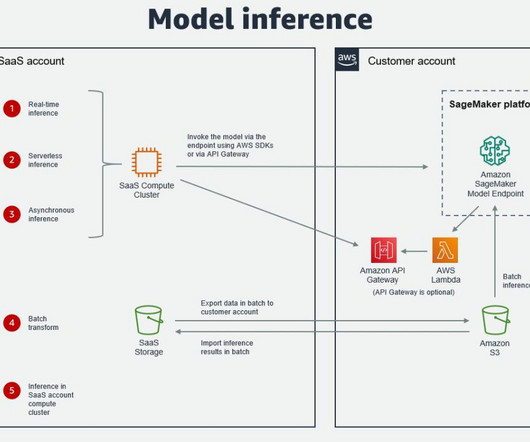
Many organizations choose SageMaker as their ML platform because it provides a common set of tools for developers and data scientists. There are a few different ways in which authentication across AWS accounts can be achieved when data in the SaaS platform is accessed from SageMaker and when the ML model is invoked from the SaaS platform.
Statistical methods and machine learning (ML) methods are actively developed and adopted to maximize the LTV. In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.
PT “Architecture Analysis for ETL Processing: CPU vs. GPU” at 4:30 p.m. PT; “Spark RAPIDS ML: GPU Accelerated Distributed ML in Spark Clusters” at 1:30 p.m. Key sessions, taking place June 13, include: “Development and Deployment of Generative AI with NVIDIA” at 12:30 p.m.
We then discuss the various use cases and explore how you can use AWS services to clean the data, how machine learning (ML) can aid in this effort, and how you can make ethical use of the data in generating visuals and insights. The following reference architecture depicts a workflow using ML with geospatial data.
Data scientists and engineers frequently collaborate on machine learning ML tasks, making incremental improvements, iteratively refining ML pipelines, and checking the model’s generalizability and robustness. To build a well-documented ML pipeline, data traceability is crucial. Also, don’t forget to follow us on Twitter.
Our product is one of those that is able to do the entire automation including the ETL pipelines and data modeling and loading data into your star schemas or data wall automatically and also maintaining it using CDC. Speed Varying data formats Data publishing What are some ways that Astera has integrated AI into customer workflow?
Second, because data, code, and other development artifacts like machine learning (ML) models are stored within different services, it can be cumbersome for users to understand how they interact with each other and make changes. For Project profile , choose Data analytics and AI-ML model development. Choose Continue.
Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines. He specializes in building scalable machine learning infrastructure, distributed systems, and containerization technologies.
The embeddings are captured in Amazon Simple Storage Service (Amazon S3) via Amazon Kinesis Data Firehose , and we run a combination of AWS Glue extract, transform, and load (ETL) jobs and Jupyter notebooks to perform the embedding analysis. Set the parameters for the ETL job as follows and run the job: Set --job_type to BASELINE.
And eCommerce companies have a ton of use cases where ML can help. The problem is, with more ML models and systems in production, you need to set up more infrastructure to reliably manage everything. And because of that, many companies decide to centralize this effort in an internal ML platform. But how to build it?
In this post, we explore how AWS customer Pro360 used the Amazon Comprehend custom classification API , which enables you to easily build custom text classification models using your business-specific labels without requiring you to learn machine learning (ML), to improve customer experience and reduce operational costs. overall accuracy.
ML Engineer at Tiger Analytics. The large machine learning (ML) model development lifecycle requires a scalable model release process similar to that of software development. Model developers often work together in developing ML models and require a robust MLOps platform to work in.
Moreover, modern data warehousing pipelines are suitable for growth forecasting and predictive analysis using artificial intelligence (AI) and machine learning (ML) techniques. They can contain structured, unstructured, or semi-structured data.
They defined it as : “ A data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of data warehouses, enabling business intelligence (BI) and machine learning (ML) on all data. ”.
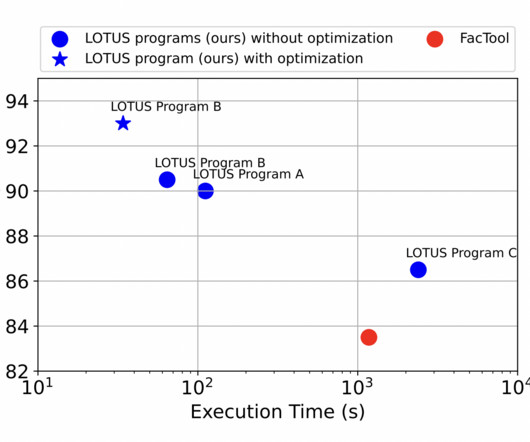
For instance, Palimpzest offers a declarative approach to data cleaning and ETL tasks, introducing a convert operator for entity extraction and an AI-based filter. Several prior works have extended relational languages with LM-based operations for specialized tasks. If you like our work, you will love our newsletter.
And we at deployr , worked alongside them to find the best possible answers for everyone involved and build their Data and ML Pipelines. Building data and ML pipelines: from the ground to the cloud It was the beginning of 2022, and things were looking bright after the lockdown’s end. With that out of the way, let’s dig in!
This situation is not different in the ML world. Data Scientists and ML Engineers typically write lots and lots of code. From writing code for doing exploratory analysis, experimentation code for modeling, ETLs for creating training datasets, Airflow (or similar) code to generate DAGs, REST APIs, streaming jobs, monitoring jobs, etc.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. IBM watsonx.ai With watsonx.ai, businesses can effectively train, validate, tune and deploy AI models with confidence and at scale across their enterprise.
To address this, teams should implement robust ETL (extract, transform, load) pipelines to preprocess, clean, and align time series data. Interpretability and trustworthiness : Time series models, particularly complex LMs, can be seen as “black boxes,” making it hard to interpret predictions.
In this post, we discuss a machine learning (ML) solution for complex image searches using Amazon Kendra and Amazon Rekognition. Amazon Kendra is an intelligent search service powered by ML, and Amazon Rekognition is an ML service that can identify objects, people, text, scenes, and activities from images or videos.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content