This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machine learning (ML) has become a critical component of many organizations’ digital transformation strategy. From predicting customer behavior to optimizing business processes, ML algorithms are increasingly being used to make decisions that impact business outcomes.
This involves unifying and sharing a single copy of data and metadata across IBM® watsonx.data ™, IBM® Db2 ®, IBM® Db2® Warehouse and IBM® Netezza ®, using native integrations and supporting open formats, all without the need for migration or recataloging.
Customers use Amazon Redshift as a key component of their data architecture to drive use cases from typical dashboarding to self-service analytics, real-time analytics, machine learning (ML), data sharing and monetization, and more. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
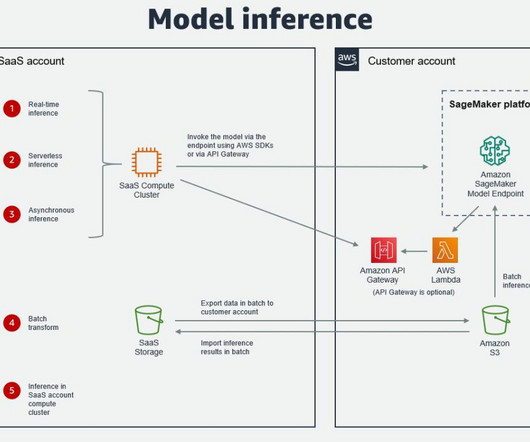
Many organizations choose SageMaker as their ML platform because it provides a common set of tools for developers and data scientists. There are a few different ways in which authentication across AWS accounts can be achieved when data in the SaaS platform is accessed from SageMaker and when the ML model is invoked from the SaaS platform.
Moreover, modern data warehousing pipelines are suitable for growth forecasting and predictive analysis using artificial intelligence (AI) and machine learning (ML) techniques. Metadata: Metadata is data about the data. Metadata: Metadata is data about the data.
Statistical methods and machine learning (ML) methods are actively developed and adopted to maximize the LTV. In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.
Iris was designed to use machine learning (ML) algorithms to predict the next steps in building a data pipeline. By analyzing millions of metadata elements and data flows, Iris could make intelligent suggestions to users, democratizing data integration and allowing even those without a deep technical background to create complex workflows.
You then format these pairs as individual text files with corresponding metadata JSON files , upload them to an S3 bucket, and ingest them into your cache knowledge base. Chaithanya Maisagoni is a Senior Software Development Engineer (AI/ML) in Amazons Worldwide Returns and ReCommerce organization.
Data within a data fabric is defined using metadata and may be stored in a data lake, a low-cost storage environment that houses large stores of structured, semi-structured and unstructured data for business analytics, machine learning and other broad applications.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. IBM watsonx.ai With watsonx.ai, businesses can effectively train, validate, tune and deploy AI models with confidence and at scale across their enterprise.
In this post, we discuss a machine learning (ML) solution for complex image searches using Amazon Kendra and Amazon Rekognition. Amazon Kendra is an intelligent search service powered by ML, and Amazon Rekognition is an ML service that can identify objects, people, text, scenes, and activities from images or videos.
They defined it as : “ A data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of data warehouses, enabling business intelligence (BI) and machine learning (ML) on all data. ”. Data fabric promotes data discoverability.
Second, because data, code, and other development artifacts like machine learning (ML) models are stored within different services, it can be cumbersome for users to understand how they interact with each other and make changes. Data and AI governance Publish your data products to the catalog with glossaries and metadata forms.
ML Engineer at Tiger Analytics. The large machine learning (ML) model development lifecycle requires a scalable model release process similar to that of software development. Model developers often work together in developing ML models and require a robust MLOps platform to work in.
Open is creating a foundation for storing, managing, integrating and accessing data built on open and interoperable capabilities that span hybrid cloud deployments, data storage, data formats, query engines, governance and metadata. A shared metadata layer, governance to catalog your data and data lineage enable trusted AI outputs.
And eCommerce companies have a ton of use cases where ML can help. The problem is, with more ML models and systems in production, you need to set up more infrastructure to reliably manage everything. And because of that, many companies decide to centralize this effort in an internal ML platform. But how to build it?
Although these traditional machine learning (ML) approaches might perform decently in terms of accuracy, there are several significant advantages to adopting generative AI approaches. The following table compares the generative approach (generative AI) with the discriminative approach (traditional ML) across multiple aspects.
And we at deployr , worked alongside them to find the best possible answers for everyone involved and build their Data and ML Pipelines. Building data and ML pipelines: from the ground to the cloud It was the beginning of 2022, and things were looking bright after the lockdown’s end. With that out of the way, let’s dig in!
Luckily, we have tried and trusted tools and architectural patterns that provide a blueprint for reliable ML systems. In this article, I’ll introduce you to a unified architecture for ML systems built around the idea of FTI pipelines and a feature store as the central component. But what is an ML pipeline?
Dolt LakeFS Delta Lake Pachyderm Git-like versioning Database tool Data lake Data pipelines Experiment tracking Integration with cloud platforms Integrations with ML tools Examples of data version control tools in ML DVC Data Version Control DVC is a version control system for data and machine learning teams. DVC Git LFS neptune.ai
ML operationalization summary As defined in the post MLOps foundation roadmap for enterprises with Amazon SageMaker , ML and operations (MLOps) is the combination of people, processes, and technology to productionize machine learning (ML) solutions efficiently.
The examples focus on questions on chunk-wise business knowledge while ignoring irrelevant metadata that might be contained in a chunk. About the authors Samantha Stuart is a Data Scientist with AWS Professional Services, and has delivered for customers across generative AI, MLOps, and ETL engagements.
This article was originally an episode of the ML Platform Podcast , a show where Piotr Niedźwiedź and Aurimas Griciūnas, together with ML platform professionals, discuss design choices, best practices, example tool stacks, and real-world learnings from some of the best ML platform professionals. Stefan: Yeah.
Data Extraction, Transformation, and Loading (ETL) This is the workhorse of architecture. ETL tools act like skilled miners , extracting data from various source systems. Metadata This acts like the data dictionary, providing crucial information about the data itself. This ensures data accuracy and consistency across the board.
This includes the tools and techniques we used to streamline the ML model development and deployment processes, as well as the measures taken to monitor and maintain models in a production environment. Costs: Oftentimes, cost is the most important aspect of any ML model deployment. I would say the same happened in our case. S3 buckets.
You also learned how to build an Extract Transform Load (ETL) pipeline and discovered the automation capabilities of Apache Airflow for ETL pipelines. You might need to extract the weather and metadata information about the location, after which you will combine both for transformation. This type of execution is shown below.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them. You can find Pranav on LinkedIn.
Create data dictionaries and metadata repositories to help users understand the data’s structure and context. ETL (Extract, Transform, Load) Processes Enhance ETL processes to ensure data quality checks are performed during data ingestion. Data Documentation Comprehensive data documentation is essential.
And because it takes more than technologies and processes to succeed with MLOps, he will also share details on: 1 Brainly’s ML use cases, 2 MLOps culture, 3 Team structure, 4 And technologies Brainly uses to deliver AI services to its clients, Enjoy the article! quality attributes) and metadata enrichment (e.g.,
Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. It’s optimized with performance features like indexing, and customers have seen ETL workloads execute up to 48x faster. It helps data engineering teams by simplifying ETL development and management.
Organizations run millions of Apache Spark applications each month to prepare, move, and process their data for analytics and machine learning (ML). This feature uses ML and generative AI technologies to provide automated root cause analysis for failed Spark applications, along with actionable recommendations and remediation steps.
The application needs to search through the catalog and show the metadata information related to all of the data assets that are relevant to the search context. The following diagram illustrates the end-to-end architecture, consisting of the metadata API layer, ingestion pipeline, embedding generation workflow, and frontend UI.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content