This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
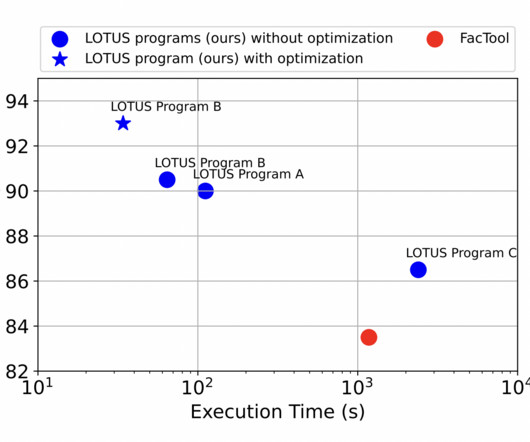
Similar to how a customer service team maintains a bank of carefully crafted answers to frequently asked questions (FAQs), our solution first checks if a users question matches curated and verified responses before letting the LLM generate a new answer. No LLM invocation needed, response in less than 1 second.
30% Off ODSC East, Fan-Favorite Speakers, Foundation Models for Times Series, and ETL Pipeline Orchestration The ODSC East 2025 Schedule isLIVE! Explore the must-attend sessions and cutting-edge tracks designed to equip AI practitioners, data scientists, and engineers with the latest advancements in AI and machine learning.
For example, recently, I started working on developing a model in an open-science manner for the European Space Agency for fine-tuning an LLM on data concerning earth observation and earth science. In this article, we will look at some data engineering basics for developing a so-called ETL pipeline.
An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark. Creating ETL pipelines to transform log data Preparing your data to provide quality results is the first step in an AI project.
However, the industry is seeing enough potential to consider LLMs as a valuable option. The following are a few potential benefits: Improved accuracy and consistency LLMs can benefit from the high-quality translations stored in TMs, which can help improve the overall accuracy and consistency of the translations produced by the LLM.
Checking LLM accuracy for ground truth data To evaluate an LLM for the task of category labeling, the process begins by determining if labeled data is available. When automation is preferred, using another LLM to assess outputs can be effective. However, the precision of this method depends on the reliability of the chosen LLM.
The ETL (Extract, Transform, Load) process is also critical in aggregating and processing data from varied sources. Despite their effectiveness, these methods and frameworks must provide a unified, customizable solution for all LLM data processing needs. It inspires intrigue about its potential impact on data processing.
” He notes it’s powered by “a compound AI system that continuously learns from usage across an organisation’s entire data stack, including ETL pipelines, lineage, and other queries.”
To scale ground truth generation and curation, you can apply a risk-based approach in conjunction with a prompt-based strategy using LLMs. Its important to note that LLM-generated ground truth isnt a substitute for use case SME involvement. To convert the source document excerpt into ground truth, we provide a base LLM prompt template.
The raw data is processed by an LLM using a preconfigured user prompt. The LLM generates output based on the user prompt. Prerequisites This post is intended for developers with a basic understanding of LLM and prompt engineering. We use an LLM from Amazon Bedrock to generate a category label for each piece of feedback.
This facilitates a series of data transformations and enhances the effectiveness of the proposed LLM-based system. Bootstrapping ETL pipelines using the provided data transformation greatly reduces the user’s burden of writing their code.
Overview of RAG The RAG pattern lets you retrieve knowledge from external sources, such as PDF documents, wiki articles, or call transcripts, and then use that knowledge to augment the instruction prompt sent to the LLM. This allows the LLM to reference more relevant information when generating a response.
Cost-effective – The solution should only invoke LLM to generate reusable code on an as-needed basis instead of manipulating the data directly to be as cost-effective as possible. LLMs excel at writing code and reasoning over text, but tend to not perform as well when interacting directly with time-series data.
Berkeley researchers wrote a new mechanism to create diverse training dataset for a variety of different “personas” and through these personas to diversity the training corpus being used to train the LLM. This library is designed to offer valuable insights into the reliability of an LLM's structured outputs.
For instance, Palimpzest offers a declarative approach to data cleaning and ETL tasks, introducing a convert operator for entity extraction and an AI-based filter. It supports complex query patterns, including joins, aggregation, ranking, and search functions, beyond the capabilities of row-wise LLM UDFs.
Analytics/Answers are included(batteries included in LLM): In the consumption of the data after data janitor work, we no longer have to depend on tables, spreadsheets or any other your favorite analytics tool for messaging and formatting this dataset to build the decks/presentations that you want to communicate the insights and learnings.
Shamika Ariyawansa , serving as a Senior AI/ML Solutions Architect in the Healthcare and Life Sciences division at Amazon Web Services (AWS),specializes in Generative AI, with a focus on Large Language Model (LLM) training, inference optimizations, and MLOps (Machine Learning Operations).
Essentially, it performs ETL (Extract, Transform, Load) on the left side, powering experiences via APIs on the right side. Additionally, Pryon provides the flexibility to choose a public, custom, or Pryon-developed large language model (LLM), making the implementation process seamless and highly customizable.
Furthermore, we deep dive on the most common generative AI use case of text-to-text applications and LLM operations (LLMOps), a subset of FMOps. LLM-powered evaluation – In this scenario, the prompt testers are replaced by an LLM, ideally one that is more powerful (although perhaps slower and most costly) than the ones being tested.
By taking a data-centric approach to AI MindsDB brings the process closer to the source of the data minimizing the need to build and maintain data pipelines and ETL’ing, speeding up the time to deployment and reducing complexity. Personalized Segment Anything Model (SAM) , termed as PerSAM.
🔎 ML Research RL for Open Ended LLM Conversations Google Research published a paper detailing dynamic planning, a reinforcement learning(RL) based technique to guide open ended conversations. Self-Aligned LLM IBM Research published a paper introducing Dromedary, a self-aligned LLM trained with minimum user supervision.
RAG is a methodology to improve the accuracy of LLM responses answering a user query by retrieving and inserting relevant domain knowledge into the language model prompt. Tuning chunking and indexing in the retriever makes sure the correct content is available in the LLM prompt for generation.
You can use these connections for both source and target data, and even reuse the same connection across multiple crawlers or extract, transform, and load (ETL) jobs. This adaptation is facilitated through the use of LLM prompts. To host your LLM as a SageMaker endpoint, you generate several artifacts.
Efficient Incremental Processing with Apache Iceberg and Netflix Maestro Dimensional Data Modeling in the Modern Era Building Big Data Workflows: NiFi, Hive, Trino, & Zeppelin An Introduction to Data Contracts From Data Mess to Data Mesh — Data Management in the Age of Big Data and Gen AI Introduction to Containers for Data Science / Data Engineering (..)
Anthropic, an AI safety and research lab that builds reliable, interpretable, and steerable AI systems, is one of the leading AI companies that offers access to their state-of-the art LLM, Claude, on Amazon Bedrock. Let’s combine these suggestions to improve upon our original prompt: Human: Your job is to act as an expert on ETL pipelines.
It supports ETL/ELT, automation, API management, and secure deployments across cloud, on-premises, and hybrid environments. SnapLogic is an AI-powered integration platform that streamlines data and application workflows with no-code tools and over 1,000 pre-built connectors.
LLM chain service – This service orchestrates the solution by invoking the LLM models with a fitting prompt and creating the response that is returned to the user. Query variants – Prior to retrieving documents from the database, multiple variants of the user query are generated using an LLM.
As an early adopter of large language model (LLM) technology, Zeta released Email Subject Line Generation in 2021. ZOE is a multi-agent LLM application that integrates with multiple data sources to provide a unified view of the customer, simplify analytics queries, and facilitate marketing campaign creation.
This will help them ensure data quality and speed – elements that are critical for driving valuable insights and fueling AI and LLM models. Before Exasol, Helsana relied on various reporting tools with data warehouses built on different technologies and ETL tools which created a tangled, inefficient architecture.
AWS Glue: Fully managed ETL service for easy data preparation and integration. Data & ML/LLM Ops on AWS Amazon SageMaker: Comprehensive ML service to build, train, and deploy models at scale. Amazon Comprehend & Translate: Leverage NLP and translation for LLM (Large Language Models) applications.
AWS Glue: Fully managed ETL service for easy data preparation and integration. Data & ML/LLM Ops on AWS Amazon SageMaker: Comprehensive ML service to build, train, and deploy models at scale. Amazon Comprehend & Translate: Leverage NLP and translation for LLM (Large Language Models) applications.
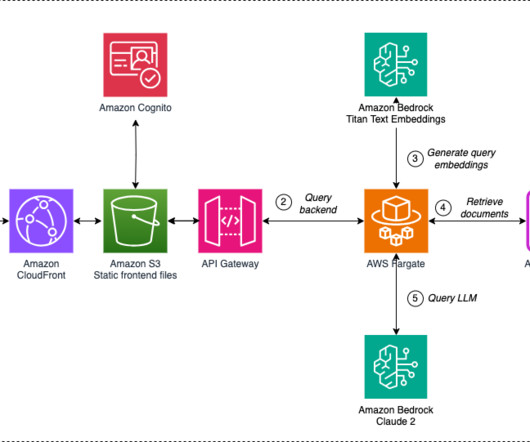
Read triples from the Neptune database and convert them into text format using an LLM hosted on Amazon Bedrock. The following LLM models must be enabled. The following is a SPARQL query that inserts new metadata inferred from existing triples: PREFIX xsd: INSERT { ?asset account } WHERE { ?asset asset "GlueTableAssetType". ?asset
By focusing on applications like AI-generated ad creatives, the framework enables self-interested LLM agents to influence joint outputs through strategic bidding while maintaining computational efficiency and incentive compatibility. a word or phrase) as a decision point where LLM agents bid to influence the next token’s selection.
Deterministic LLM-based workflows Parametas solution demanded more than just raw large language model (LLM) capabilitiesit required a structured approach while maintaining operational control. Martin Gregory is a Senior Market Data Technician at Parameta Solutions with over 25 years of experience.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content