This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Understanding data governance in healthcare The need for a strong data governance framework is undeniable in any highly-regulated industry, but the healthcare industry is unique because it collects and processes massive amounts of personal data to make informed decisions about patient care. Instead, it uses active metadata.
This trust depends on an understanding of the data that inform risk models: where does it come from, where is it being used, and what are the ripple effects of a change? Banks and their employees place trust in their risk models to help ensure the bank maintains liquidity even in the worst of times.
While these models are trained on vast amounts of generic data, they often lack the organization-specific context and up-to-date information needed for accurate responses in business settings. You have access to a knowledge base with information about the Amazon Bedrock service on AWS.
In BI systems, data warehousing first converts disparate raw data into clean, organized, and integrated data, which is then used to extract actionable insights to facilitate analysis, reporting, and data-informed decision-making. Data Sources: Data sources provide information and context to a data warehouse.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
Analyze the events’ impact by examining their metadata and textual description. Figure: AI chatbot workflow Archiving and reporting layer The archiving and reporting layer handles streaming, storing, and extracting, transforming, and loading (ETL) operational event data. Dispatch notifications through instant messaging tools or emails.
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. With multiple families in plan, the first release is the Slate family of models, which represent an encoder-only architecture.
It entails analyzing, cleansing, transforming, and modeling data to find valuable information, improve data quality, and assist in better decision-making, What is Data Profiling? Metadata analysis is the first step in establishing the association, and subsequent steps involve refining the relationships between individual database variables.
While traditional data warehouses made use of an Extract-Transform-Load (ETL) process to ingest data, data lakes instead rely on an Extract-Load-Transform (ELT) process. This adds an additional ETL step, making the data even more stale. All phases of the data-information lifecycle. Data fabric promotes data discoverability.
The following figure shows an example diagram that illustrates an orchestrated extract, transform, and load (ETL) architecture solution. Identifying keywords such as use cases and industry verticals in these sources also allows the information to be captured and for more relevant search results to be displayed to the user.
To ensure the highest quality measurement of your question answering application against ground truth, the evaluation metrics implementation must inform ground truth curation. For more information, see the Amazon Bedrock documentation on LLM prompt design and the FMEval documentation.
For example, each log is written in the format of timestamp, user ID, and event information. To solve this problem, we build an extract, transform, and load (ETL) pipeline that can be run automatically and repeatedly for training and inference dataset creation. ML engineers no longer need to manage this training metadata separately.
Open is creating a foundation for storing, managing, integrating and accessing data built on open and interoperable capabilities that span hybrid cloud deployments, data storage, data formats, query engines, governance and metadata. This enables your organization to extract valuable insights and drive informed decision-making.
Irina Steenbeek introduces the concept of descriptive lineage as “a method to record metadata-based data lineage manually in a repository.” Extraction, transformation and loading (ETL) tools dominated the data integration scene at the time, used primarily for data warehousing and business intelligence.
For more information, see Customize models in Amazon Bedrock with your own data using fine-tuning and continued pre-training. It can automate extract, transform, and load (ETL) processes, so multiple long-running ETL jobs run in order and complete successfully without manual orchestration. No explanation is required.
Tackling these challenges is key to effectively connecting readers with content they find informative and engaging. AWS Glue performs extract, transform, and load (ETL) operations to align the data with the Amazon Personalize datasets schema. For example, article metadata may contain company and industry names in the article.
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Metadata Management: Tracking metadata , such as data schema, data sources, and data transformation processes, aids in understanding the evolution of datasets and the context of changes.
This approach aims to mitigate limitations of previous methods that relied on broad demographic information for persona creation. Used for 🔀 ETL Systems, ⚙️ Data Microservices, and 🌐 Data Collection Key features: 💡Intuitive API: Easy to learn, easy to think about.
Almost all organisations nowadays make informed decisions by leveraging data and analysing the market effectively. Accordingly, the need for Data Profiling in ETL becomes important for ensuring higher data quality as per business requirements. What is Data Profiling in ETL?
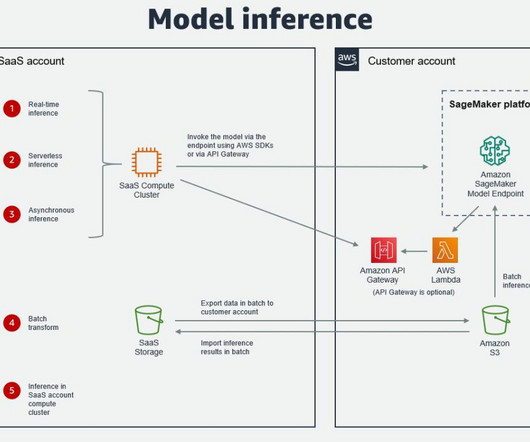
Alternatively, a service such as AWS Glue or a third-party extract, transform, and load (ETL) tool can be used for data transfer. If the ML model is deployed to a SageMaker model endpoint, additional model metadata can be stored in the SageMaker Model Registry , SageMaker Model Cards , or in a file in an S3 bucket.
The Model Registry metadata has four custom fields for the environments: dev, test, uat , and prod. The model detail information is stored in Parameter Store, including the model version, approved target environment, and model package. The SageMaker training pipeline develops and registers a model in SageMaker Model Registry.
This flexibility allows organizations to store vast amounts of raw data without the need for extensive preprocessing, providing a comprehensive view of information. This centralization streamlines data access, facilitating more efficient analysis and reducing the challenges associated with siloed information. What Is a Data Warehouse?
In the case of our CI/CD-MLOPs system, we stored the model versions and metadata in the data storage services offered by AWS i.e ” Hence the very first thing to do is to make sure that the data being used is of high quality and that any errors or anomalies are detected and corrected before proceeding with ETL and data sourcing.
A feature store typically comprises a feature repository, a feature serving layer, and a metadata store. The metadata store manages the metadata associated with each feature, such as its origin and transformations. The feature repository is essentially a database storing pre-computed and versioned features.
Overview In the era of Big Data , organizations inundated with vast amounts of information generated from various sources. Attributes : Metadata associated with the FlowFile, such as its filename, size, and any custom attributes defined by the user. Its visual interface allows users to design complex ETL workflows with ease.
These work together to enable efficient data processing and analysis: · Hive Metastore It is a central repository that stores metadata about Hive’s tables, partitions, and schemas. Processing of Data Once the data is stored, Hive provides a metadata layer allowing users to define the schema and create tables.
You also learned how to build an Extract Transform Load (ETL) pipeline and discovered the automation capabilities of Apache Airflow for ETL pipelines. The image below shows an example of DAG; the graph is directed, information flows from A throughout the graph, and it is acyclic since the info from A doesn't get back to A.
or lower) or in a custom environment, refer to appendix for more information. An AWS Glue connection is an AWS Glue Data Catalog object that stores essential data such as login credentials, URI strings, and virtual private cloud (VPC) information for specific data stores. Instead, use Secrets Manager for handling sensitive information.
Quality data fuels business decisions, informs scientific research, drives technological innovations, and shapes our understanding of the world. The significance of data quality lies at the heart of this digital age, as it determines the reliability and trustworthiness of the information we rely on.
This blog aims to clarify Big Data concepts, illuminate Hadoops role in modern data handling, and further highlight how HDFS strengthens scalability, ensuring efficient analytics and driving informed business decisions. Because it manages critical information, the NameNode typically runs on a dedicated machine for maximum efficiency.
To get all this information, we need to have sessions with the different areas of the team (scientists, engineers, QA, managers, C-level executives if the need arises) in order to fully understand each one’s expectations with the project and reach a common understanding. 3 The SQS queues were messy to maintain. What’s in the box?
Data Dictionary: This repository contains metadata about database objects, such as tables and columns. Indices: Indices are used to speed up data retrieval processes by providing quick access paths to information. Their expertise is crucial in projects involving data extraction, transformation, and loading (ETL) processes.
To keep myself sane, I use Airflow to automate tasks with simple, reusable pieces of code for frequently repeated elements of projects, for example: Web scraping ETL Database management Feature building and data validation And much more! It’s a lot of stuff to stay on top of, right? What’s Airflow, and why’s it so good?
Hierarchical databases, such as IBM’s Information Management System (IMS), were widely used in early mainframe database management systems. Data mining techniques were used to extract valuable insights from data, helping businesses make informed decisions. It helps data engineering teams by simplifying ETL development and management.
At a high level, we are trying to make machine learning initiatives more human capital efficient by enabling teams to more easily get to production and maintain their model pipelines, ETLs, or workflows. Maybe storing and emitting open lineage information, etc. How is DAGWorks different from other popular solutions? Stefan: Yeah.
quality attributes) and metadata enrichment (e.g., For example, they wouldn’t want personal information to get out to labelers or bad content to get out to users. Machine learning use cases at Brainly The AI department at Brainly aims to build a predictive intervention system for its users.
By analyzing millions of metadata elements and data flows, Iris could make intelligent suggestions to users, democratizing data integration and allowing even those without a deep technical background to create complex workflows. We use the following prompt: Human: Your job is to act as an expert on ETL pipelines.
Summary: A data warehouse is a central information hub that stores and organizes vast amounts of data from different sources within an organization. Unlike operational databases focused on daily tasks, data warehouses are designed for analysis, enabling historical trend exploration and informed decision-making.
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. The table metadata is managed by Data Catalog. This is a SageMaker Lakehouse managed catalog backed by RMS storage.
Moreover, LRRs and other industry frameworks, such as the National Institute of Standards and Technology (NIST), Information Technology Infrastructure Library (ITIL), and Control Objectives for Information and Related Technologies (COBIT), are constantly evolving.
Traditionally, data was seen as information to be put on reserve, only called upon during customer interactions or executing a program. It uses knowledge graphs, semantics and AI/ML technology to discover patterns in various types of metadata. Here are some examples of the types of architectures well suited for data democratization.
Customers want to search through all of the data and applications across their organization, and they want to see the provenance information for all of the documents retrieved. The application needs to search through the catalog and show the metadatainformation related to all of the data assets that are relevant to the search context.
Familiarise yourself with ETL processes and their significance. ETL Process: Extract, Transform, Load processes that prepare data for analysis. Can You Explain the ETL Process? The ETL process involves three main steps: Extract: Data is collected from various sources. What Is Metadata in Data Warehousing?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content