This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction The data integration techniques ETL (Extract, Transform, Load) and ELT pipelines (Extract, Load, Transform) are both used to transfer data from one system to another.
Introduction In today’s data-driven landscape, businesses must integrate data from various sources to derive actionable insights and make informed decisions. With data volumes growing at an […] The post Data Integration: Strategies for Efficient ETL Processes appeared first on Analytics Vidhya.
Obtaining, structuring, and analyzing these data into new, relevant information is crucial in today’s world. The post ETL vs ELT in 2022: Do they matter? Introduction Data is ubiquitous in our modern life. appeared first on Analytics Vidhya.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
It's the initial step in the larger process of ETL (Extract, Transform, Load), which involves pulling data (extracting), converting it into a usable format (transforming), and then loading it into a database or data warehouse (loading). Standing out in the ETL tool realm, Integrate.io What is Data Extraction?
The report also details how current Snowflake customers leverage a number of these partner technologies to enable data-driven marketing strategies and informed business decisions. Snowflake’s report provides a concrete overview of the partner solution providers and data providers marketers choose to create their data stacks.
“Data is at the center of every application, process, and business decision,” wrote Swami Sivasubramanian, VP of Database, Analytics, and Machine Learning at AWS, and I couldn’t agree more. A common pattern customers use today is to build data pipelines to move data from Amazon Aurora to Amazon Redshift.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. For more information on enabling users in IAM Identity Center, see Add users to your Identity Center directory. Akchhaya Sharma is a Sr.
Understanding data governance in healthcare The need for a strong data governance framework is undeniable in any highly-regulated industry, but the healthcare industry is unique because it collects and processes massive amounts of personal data to make informed decisions about patient care. The consequence?
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Introduction In today’s data-driven world, efficient data processing is crucial for informed decision-making and business growth. What is ETL? ETL stands for Extract, Transform, and Load.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances data integrity and quality, supporting informed decision-making. Introduction The ETL process is crucial in modern data management.
Summary: Selecting the right ETL platform is vital for efficient data integration. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes. What is ETL in Data Integration? Let’s explore some real-world applications of ETL in different sectors.
Summary: This article explores the significance of ETL Data in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark. Creating ETL pipelines to transform log data Preparing your data to provide quality results is the first step in an AI project.
Extract, Transform, and Load are referred to as ETL. ETL is the process of gathering data from numerous sources, standardizing it, and then transferring it to a central database, data lake, data warehouse, or data store for additional analysis. Involved in each step of the end-to-end ETL process are: 1. What Do ETL Tools Do?
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
This trust depends on an understanding of the data that inform risk models: where does it come from, where is it being used, and what are the ripple effects of a change? Banks and their employees place trust in their risk models to help ensure the bank maintains liquidity even in the worst of times.
While these models are trained on vast amounts of generic data, they often lack the organization-specific context and up-to-date information needed for accurate responses in business settings. You have access to a knowledge base with information about the Amazon Bedrock service on AWS.
The same ETL workflows were running fine before the upgrade. We tested the following adjustments with Anthropics Claude: We defined and assigned a persona with background information for the LLM: You are a Support Agent and an expert on the enterprise application software. The same ETL workflows were running fine before the upgrade.
With CustomerAI, brands can expand their perception of customer data, activate it more extensively, and be better informed by a deeper understanding of their customers. We recently announced Twilio CustomerAI to unlock the power of AI for hundreds of thousands of businesses and supercharge the engagement flywheel.
Data integration is the process of combining information from multiple sources to create a consolidated dataset. This is important because 3 out of 4 organizations suffer from data silos, leading to inefficient decision-making due to incomplete information. The challenge? This is where data integration comes in!
IBP brings together various functions, including sales, marketing, finance, supply chain, human resources, IT and beyond to collaborate across business units and make informed decisions that drive overall business success. Create a culture that values collaboration, information sharing, and collective decision-making.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
Apart from the time-sensitive necessity of running a business with perishable, delicate goods, the company has significantly adopted Azure, moving some existing ETL applications to the cloud, while Hershey’s operations are built on a complex SAP environment.
Data integration is the process of combining information from multiple sources to create a consolidated dataset. This is important because 3 out of 4 organizations suffer from data silos, leading to inefficient decision-making due to incomplete information. The challenge? This is where data integration comes in!
Transform raw insurance data into CSV format acceptable to Neptune Bulk Loader , using an AWS Glue extract, transform, and load (ETL) job. Run an AWS Glue ETL job to merge the raw property and auto insurance data into one dataset and catalog the merged dataset. Under Data classification tools, choose Record Matching.
Embeddings capture the information content in bodies of text, allowing natural language processing (NLP) models to work with language in a numeric form. This allows the LLM to reference more relevant information when generating a response. We can store that information and see how it changes over time.
In BI systems, data warehousing first converts disparate raw data into clean, organized, and integrated data, which is then used to extract actionable insights to facilitate analysis, reporting, and data-informed decision-making. Data Sources: Data sources provide information and context to a data warehouse.
Figure: AI chatbot workflow Archiving and reporting layer The archiving and reporting layer handles streaming, storing, and extracting, transforming, and loading (ETL) operational event data. Take note of the Verification Token value under Basic Information of your app, you will need it in later steps.
For example, each log is written in the format of timestamp, user ID, and event information. To solve this problem, we build an extract, transform, and load (ETL) pipeline that can be run automatically and repeatedly for training and inference dataset creation. These types of data are historical raw data from an ML perspective.
There are major worries about data traceability and reproducibility because, unlike code, data modifications do not always provide enough information about the exact source data used to create the published data and the transformations made to each source. This information will then be indexed as part of a data catalog.
Centralized Repository: Data warehouses create a single perspective of organizational information by gathering and combining data from various sources. ETL Procedures: To ensure data consistency and correctness for analysis, data warehouses utilize ETL (Extract, Transform, Load) tools to clean, standardize, and arrange data before storing it.
As a result, everyone across virtually every organization feels friction when looking for the information they need to perform their jobs and workflows. Essentially, it performs ETL (Extract, Transform, Load) on the left side, powering experiences via APIs on the right side. This is where we saw the opportunity for Pryon.
By analyzing a wide range of data points, were able to quickly and accurately assess the risk associated with a loan, enabling us to make more informed lending decisions and get our clients the financing they need. Our goal at Rocket is to provide a personalized experience for both our current and prospective clients.
To obtain such insights, the incoming raw data goes through an extract, transform, and load (ETL) process to identify activities or engagements from the continuous stream of device location pings. For more information, refer to Common techniques to detect PHI and PII data using AWS Services.
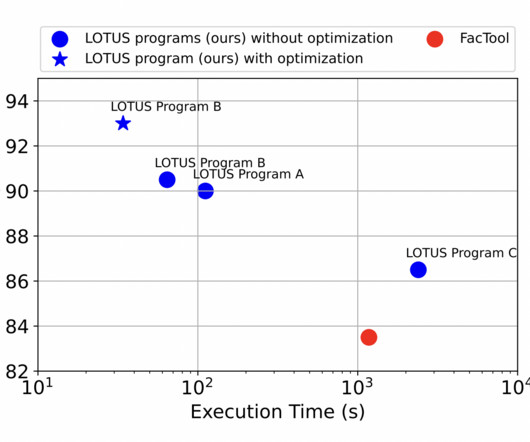
Complex tasks like summarizing recent research, extracting biomedical information, or analyzing internal business transcripts require sophisticated data processing and reasoning. For instance, Palimpzest offers a declarative approach to data cleaning and ETL tasks, introducing a convert operator for entity extraction and an AI-based filter.
While traditional data warehouses made use of an Extract-Transform-Load (ETL) process to ingest data, data lakes instead rely on an Extract-Load-Transform (ELT) process. This adds an additional ETL step, making the data even more stale. All phases of the data-information lifecycle.
To address this, teams should implement robust ETL (extract, transform, load) pipelines to preprocess, clean, and align time series data. Interpretability and trustworthiness : Time series models, particularly complex LMs, can be seen as “black boxes,” making it hard to interpret predictions.
For more information, see Customize models in Amazon Bedrock with your own data using fine-tuning and continued pre-training. It can automate extract, transform, and load (ETL) processes, so multiple long-running ETL jobs run in order and complete successfully without manual orchestration. No explanation is required.
Without data engineering , companies would struggle to analyse information and make informed decisions. It helps organisations understand their data better and make informed decisions. Talend Talend is a data integration tool that enables users to extract, transform, and load (ETL) data across different sources.
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. Information regarding potential future products is intended to outline our general product direction and it should not be relied on in making a purchasing decision.
To ensure the highest quality measurement of your question answering application against ground truth, the evaluation metrics implementation must inform ground truth curation. For more information, see the Amazon Bedrock documentation on LLM prompt design and the FMEval documentation.
Extraction, transformation and loading (ETL) tools dominated the data integration scene at the time, used primarily for data warehousing and business intelligence. Critical and quick bridges The demand for lineage extends far beyond dedicated systems such as the ETL example. Contact your IBM representative for more information.
The following figure shows an example diagram that illustrates an orchestrated extract, transform, and load (ETL) architecture solution. Identifying keywords such as use cases and industry verticals in these sources also allows the information to be captured and for more relevant search results to be displayed to the user.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content